python_多进程概念及简单用法、队列、守护进程、进程池
一。了解 单任务与多任务、串行与并行、并发、进程的概念:
1)单任务与多任务:
单任务:单任务的应用程序(cmd.exe),没办法同时执行多条命令
多任务:多任务的应用 windowns操作系统,Pycharm,迅雷(同时下载多个文件,边下边播)
多任务的实现方式:多进程、多线程、协程
2)串行与并行
串行运行:比如在linux中串行执行多条命令用&,举栗:apt install python & apt install mysql :先下载python然后下载mysql
并行运行:比如在linux中串行执行多条命令用&&,举栗:apt install python && apt install mysql :同时下载python和mysql
并行:3台电脑分别安装一个mysql8.0,然后组成mysql集群,3个mysql是同时运行(并行)
举栗:5个收银员 同时 操作 5 台收款机 --并行
3)并发
并发:比如 迅雷同时下载5个电影(单核cpu的话,5个任务反复切换下载)
举栗:1个收银员,"同时"操作5台 收款机 --并发
4)进程
进程:静态的:(软件、程序、代码、函数...) 动态:(软件运行、程序运行、代码运行、函数运行),进程是动态的
程序是怎么运行的? -->操作系统 创建一个进程(加载代码到内存,为变量分配内存,建个档案:process id PID)
二。进程介绍,举栗
实现需求:
使用多进程实现并发下载图片
-多进程会独享资源,2个进程不能共享变量(例如:不能共享list),如何实现共享资源那?(队列Queue,内存数据库redis...)
-多线程占用的资源最少,2个线程是共享变量的,迅雷就是使用多线程下载技术的。
运行代码:
#引入进程模块
from multiprocessing import Process, Queue
import requests
import os
#看不懂没关系后面会详细介绍
def download(q: Queue):
while True:
url = q.get()
r = requests.get(url)
img_name = url.split('/')[-1]
img_name = os.path.join('./', img_name)
with open(img_name, 'wb') as f: #把服务器返回的信息(图片)保存到文件中
f.write(r.content)
if q.empty():
break
if __name__ == '__main__':
tasks = Queue()
#put相当于list中的append方法
tasks.put("https://dss0.bdstatic.com/-0U0bnSm1A5BphGlnYG/tam-ogel/067d0e8627b667778ea8729e6e480a47_254_96.png")
tasks.put("https://dss0.bdstatic.com/-0U0bnSm1A5BphGlnYG/tam-ogel/3f52ff39e52f182d1bfd9ce061e9c6a6_254_144.jpg")
# 创建两个来执行download函数的进程p1,p2
p1 = Process(target=download, args=(tasks, ))
p2 = Process(target=download, args=(tasks, ))
#启动进程p1,p2
p1.start()
p2.start()
p1.join() #加上阻塞
p2.join() #加上阻塞,等p1,p2运行结束后关闭主进程,不然主进程会直接运行结束,那么子进程尚未运行结束就会找不到目录,因为主进程内存已经销毁了
#进程启动后,是由操作系统控制执行
print("主进程运行结束")
三。进程中的队列:Queue
1)使用list迭代对象存放需要处理的数据,list会存储在储存区,开多进程的话都会被执行,举栗:
from multiprocessing import Process, Queue
import time
# 1.进程,list,未使用Queue
def work1(q):
"""
:param q: 要处理的所有任务
:return:
"""
print("这个是work2中的参数q的id: ", id(q))
while q:
print(f"work1 从q中获得了 {q.pop()}")
def work2(q):
"""
:param q: 要处理的所有任务
:return:
"""
print("这个是work2中的参数q的id: ", id(q))
while q:
print(f"work2 从q中获得了 {q.pop()}")
if __name__ == '__main__':
# 进程1,使用list,work1与work2会做重复工作,因为会把list分别存在储存区,子进程p1与p2独享list
q = ['a', 'b', 'c']
p1 = Process(target=work1, args=(q,)) #子进程q1,单独把q存储在内存区不与p2子进程共享q(两个q的id不同)
p2 = Process(target=work2, args=(q,)) #子进程q2,单独把q存储在内存区不与p1子进程共享q(两个q的id不同)
p1.start()
p2.start()
print(f'主进程运行完毕!')
运行结果,开启了两个进程p1与p2,他们分别把执行任务q都执行了一遍:

2)使用队列:Queue,他通过put方法添加执行任务到队列,分别执行队列中的执行任务
from multiprocessing import Process, Queue
# 1.进程,使用Queue共享变量
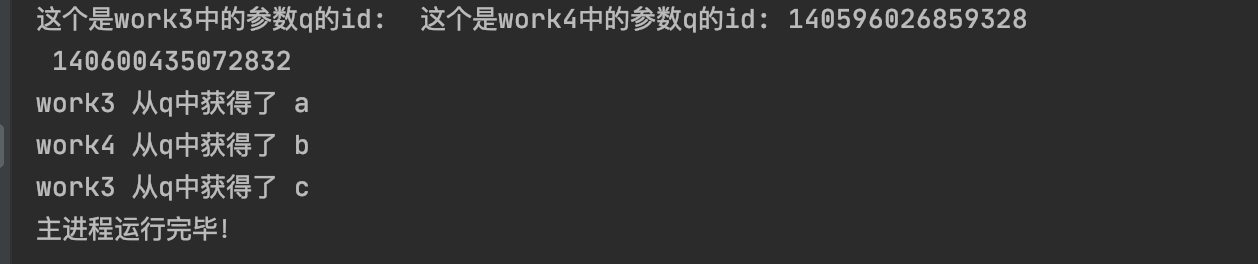
def work3(q: Queue):
"""
:param q: 要处理的所有任务
:return:
"""
time.sleep(0.5)
print("这个是work3中的参数q的id: ", id(q))
while not q.empty():
print(f"work3 从q中获得了 {q.get()}")
def work4(q: Queue):
"""
:param q: 要处理的所有任务
:return:
"""
time.sleep(0.5)
print("这个是work4中的参数q的id: ", id(q))
while not q.empty():
print(f"work4 从q中获得了 {q.get()}")
if __name__ == '__main__':
# 进程2,使用Queue(队列):work3与work4共同完成q中的所有任务 Queue 是被p1、p2共享的
q = Queue()
q.put('a')
q.put('b')
q.put('c')
p1 = Process(target=work3, args=(q,))
p2 = Process(target=work4, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
print(f'主进程运行完毕!')
运行结果,开启了两个进程p1与p2,可以明显看出他们分别执行了不同的任务:
四。多进程类的使用:继承Process,调用时会自动执行run()方法
from multiprocessing import Process
class MyProcess(Process):
def __init__(self):
super().__init__()
def run(self):
print("hello")
if __name__ == '__main__':
p1 = MyProcess()
p2 = MyProcess()
p1.start() #会调用MyProcess中的run方法
p2.start()
运行结果,可以看出,他把run()方法的内容执行了两次,暂时还没有想到比较好的使用方法(可以通过封装不同方法,最后在run方法中调用并执行),感觉使用之前队列的已经可以让执行效率提高很多了:

五。多进程与单一进程对比,守护进程:守护进程(Process().daemon ,默认值是False,)
1)单进程与多进程对比
import os
import time
from multiprocessing import Process
def play_music():
print("子进程p1,PID:", os.getpid())
for i in range(5):
print('play music ...')
time.sleep(1)
def play_lol():
print("子进程p2,PID:", os.getpid())
for i in range(5):
print('play lol ...')
time.sleep(1)
if __name__ == '__main__':
#1.第一种方式:运行了10秒
start1 = time.time()
play_music()
play_lol()
end1 = time.time()
print(f"单进程使用时间是:{end1 - start1:.2f}")
运行结果,可以明显看出单进行执行完成需要10秒左右:

2)多进程
import os
import time
from multiprocessing import Process
def play_music():
print("子进程p1,PID:", os.getpid())
for i in range(5):
print('play music ...')
time.sleep(1)
def play_lol():
print("子进程p2,PID:", os.getpid())
for i in range(5):
print('play lol ...')
time.sleep(1)
if __name__ == '__main__':
#1.第二种方式:使用多进程运行,运行了5秒,说明了在同时运行
start_time = time.time()
p1 = Process(target=play_music)
p2 = Process(target=play_lol)
p1.start() #操作系统 启动一个进程 用来运行 target=play_music 的进程,这个进程是子进程(不是完整的代码)
p2.start()
p1.join()
p2.join() #代表 运行完p1与p2的子进程后 在运行主进
end_time = time.time()
# 统计子进程所用时间
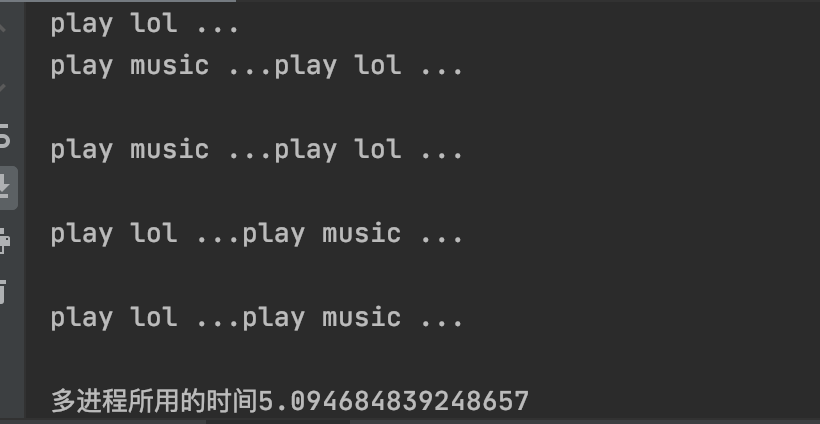
print(f"多进程所用的时间{end_time-start_time}")
print("主进程pid: ", os.getpid())
运行结果,开启了两个进程 可以明显看出 执行时间是5秒左右:
3)守护进程:Process().daemon,在主进程运行结束后,子进程依然运行直到子进程全部运行结束
import os
import time
from multiprocessing import Process
def play_music():
print("子进程p1,PID:", os.getpid())
for i in range(5):
print('play music ...')
time.sleep(1)
def play_lol():
print("子进程p2,PID:", os.getpid())
for i in range(5):
print('play lol ...')
time.sleep(1)
if __name__ == '__main__':
#1.第二种方式:使用多进程运行,运行了5秒,说明了在同时运行
start_time = time.time()
p1 = Process(target=play_music)
p2 = Process(target=play_lol)
#6)守护进程,使用在进程启动之前。默认值是False,当为True的时候,主进程结束,会强制结束子进程
p1.daemon = False
p2.daemon = False
#2)查看进程使用信息
#print(help(p2))
p1.start() #操作系统 启动一个进程 用来运行 target=play_music 的进程,这个进程是子进程(不是完整的代码)
p2.start()
end_time = time.time()
# 5)统计子进程所用时间
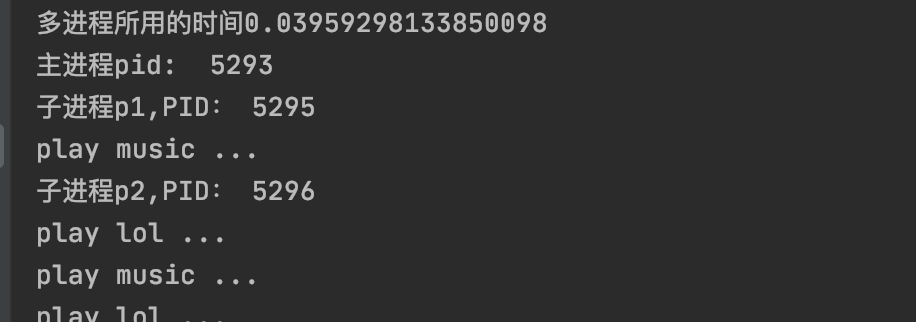
print(f"多进程所用的时间{end_time-start_time}")
print("主进程pid: ", os.getpid())
运行结果,可以明显看出,主进程已经运行结束了,子进程还在运行:
六。进程池:Pool,在介绍进程池前先介绍两个经典的进程池方法:map、apply
1)map与map_async
map:
#map
# 调用python3的进程池
"""
map:把一个可迭代对象 映射到 函数(有几个迭代参数运行几次),同步执行
"""
from multiprocessing import Pool
import time
def square(x):
result = x * x
time.sleep(1)
return result
if __name__ == '__main__':
start = time.time()
#创建9个进程
pool = Pool(9)
result = pool.map(square, [1, 2, 3, 4]) #map会阻塞主程序(使用了map就不需要使用join(),作用:一系列的数据应用到函数身上,并使用多进程)
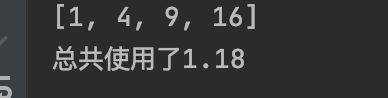
print(result)
pool.close()
endtimes1 = time.time()
#打印所用时间并保存两位小数,:.2f
print(f"总共使用了{(endtimes1 - start):.2f}")
运行结果:
map_async:
"""
什么时候用map什么时候用map_async:当不需要打印结果的时候使用map_async,因为map 也是调用 map_async只是多了一步".get"的方法,所以直接运行map_async比较快
map_async:把一个可迭代对象 映射到 函数(有几个迭代参数运行几次),异步执行
"""
from multiprocessing import Pool
import time
def square(x):
time.sleep(2)
result = x * x
print("~~~~~~~~~~")
return result
if __name__ == '__main__':
start = time.time()
pool = Pool(8)
result = pool.map_async(square, [1, 2, 3, 4]) #不会阻塞主程序
#print(result.get()) #.get() :是获取运行结果,每运行完一次就会拿一次结果然后再执行下一次,实质上就是阻塞 等同于pool.map 阻塞方法
end = time.time()
print(f"总共使用了{(end - start):.2f}")
print("主程序结束")
运行结果:

map与map_async对比:
map其实调用的是map_async方法,只是比map_async多了一步".get()",如下图源码:

2)apply与apply_async区别:
"""
apply:调用函数,传递任意参数(运行一次)
"""
import time
from multiprocessing import Pool
def test(x, y, z=0):
print("子程序正在运行")
#pass
if __name__ == '__main__':
pool = Pool(2)
#apply(self, func, args=(), kwds={})
pool.apply(test, (2, 3), {"z": 1}) #阻塞 主程序(也就是主进程),apply传的参数是元组类型的任意参数,map是可迭代对象
pool.apply_async(test, (2, 3), {"z": 1}) # 不阻塞 主程序(也就是主进程)
print("主程序运行结束")
print(help(pool.apply))
运行结果,可以看到无论传递多少参数其实只运行了一次:

apply与apply_async区别,apply其实调用的是apply_async方法只是多了".get()"方法,如下图源码:
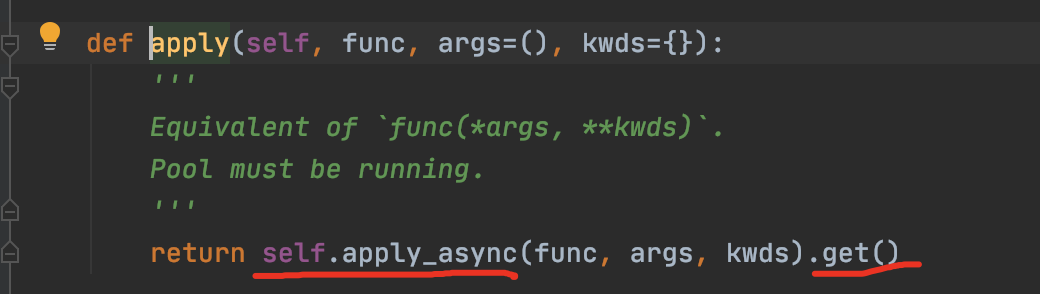
3)map与apply的区别:
apply:调用函数,传递任意参数(运行一次)
map:把一个可迭代对象 映射到 函数(有几个迭代参数运行几次)
_async:如果加这个名字的进程函数,都是不阻塞的函数方法
同步(阻塞)与异步(不阻塞)区别:
同步 :该方法不运行完成 主程序不会结束
异步:可以执行多个异步方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号