
1. 可变类型与不可变类型
可变类型,值可以改变:列表 list,字典 dict
不可变类型,值不可以改变:数值类型 int, long, bool, float,字符串 str,元组 tuple
2. 局部变量与全局变量
局部变量:
局部变量,就是在函数内部定义的变量
不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响
局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用
全局变量:
在函数外边定义的变量叫做全局变量
全局变量能够在所有的函数中进行访问
如果在函数中修改全局变量,那么就需要使用global进行声明,否则出错
如果全局变量的名字和局部变量的名字相同,那么使用的是局部变量的,小技巧强龙不压地头蛇
可变类型的全局变量:
在函数中不使用global声明全局变量时不能修改全局变量的本质是不能修改全局变量的指向,即不能将全局变量指向新的数据。
对于不可变类型的全局变量来说,因其指向的数据不能修改,所以不使用global时无法修改全局变量
对于可变类型的全局变量来说,因其指向的数据可以修改,所以不使用global时也可修改全局变量。
3. 函数返回多个返回值
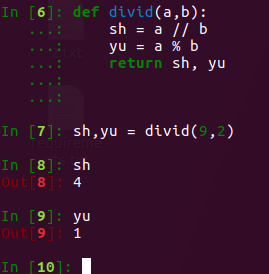
本质上是利用了元组
4. 函数参数
1. 缺省参数:调用函数时,缺省参数的值如果没有传入,则被认为是默认值。
带有默认值的参数一定要位于参数列表的最后面
2. 不定长参数:有时可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名。

加了星号(*)的变量args会存放所有未命名的变量参数,args为元组;而加**的变量kwargs会存放命名参数,即形如key=value的参数, kwargs为字典。
3. 引用参数

Python中函数参数是引用传递(注意不是值传递)。对于不可变类型,因变量不能修改,所以运算不会影响到变量自身;而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量。
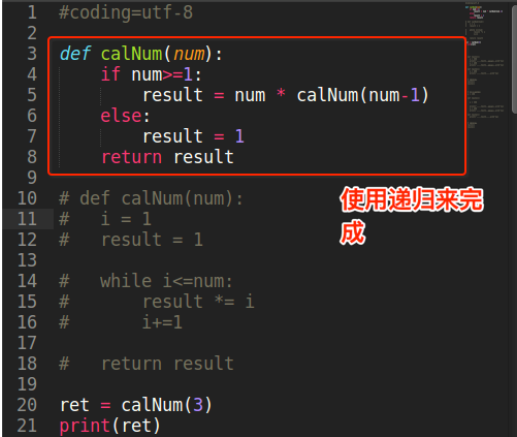
5. 递归函数
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
例:
6. 匿名函数
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
Lambda函数能接收任何数量的参数但只能返回一个表达式的值
匿名函数不能直接调用print,因为lambda需要一个表达式

应用场合:1. 自己定义函数。 2. 作为内置函数的参数
7. 函数使用注意事项
1. 一个函数到底有没有返回值,就看有没有return,因为只有return才可以返回数据。
2. 函数中,可以有多个return语句,但是只要执行到一个return语句,那么就意味着这个函数的调用完成
3. 如果调用的函数有返回值,那么就可以用一个变量来进行保存这个值
8. 面向对象
面向过程:根据业务逻辑从上到下写代码
面向对象:将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程
类的创建:
- 定义类时有2种:新式类和经典类,上面的Car为经典类,如果是Car(object)则为新式类
- 类名 的命名规则按照"大驼峰"
创建对象:
- BMW = Car(),这样就产生了一个Car的实例对象,此时也可以通过实例对象BMW来访问属性或者方法
- 第一次使用BMW.color = '黑色'表示给BMW这个对象添加属性,如果后面再次出现BMW.color = xxx表示对属性进行修改
- BMW是一个对象,它拥有属性(数据)和方法(函数)
- 当创建一个对象时,就是用一个模子,来制造一个实物
__init__()方法:
__init__()方法,在创建一个对象时默认被调用,不需要手动调用__init__(self)中,默认有1个参数名字为self,如果在创建对象时传递了2个实参,那么__init__(self)中出了self作为第一个形参外还需要2个形参,例如__init__(self,x,y)__init__(self)中的self参数,不需要开发者传递,python解释器会自动把当前的对象引用传递进去
__del__()方法:
当删除一个对象时,python解释器也会默认调用一个方法,这个方法为__del__()方法
- 当有1个变量保存了对象的引用时,此对象的引用计数就会加1
- 当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除
"魔法"方法:
- 在python中方法名如果是
__xxxx__()的,那么就有特殊的功能,因此叫做“魔法”方法 - 当使用print输出对象的时候,只要自己定义了
__str__(self)方法,那么就会打印从在这个方法中return的数据
self:
- 所谓的self,可以理解为自己
- 可以把self当做C++中类里面的this指针一样理解,就是对象自身的意思
- 某个对象调用其方法时,python解释器会把这个对象作为第一个参数传递给self,所以开发者只需要传递后面的参数即可
修改对象属性:
1. 直接通过对象名修改
SweetPotato.cookedLevel = 5
2. 通过方法间接修改
SweetPotato.cook(5)
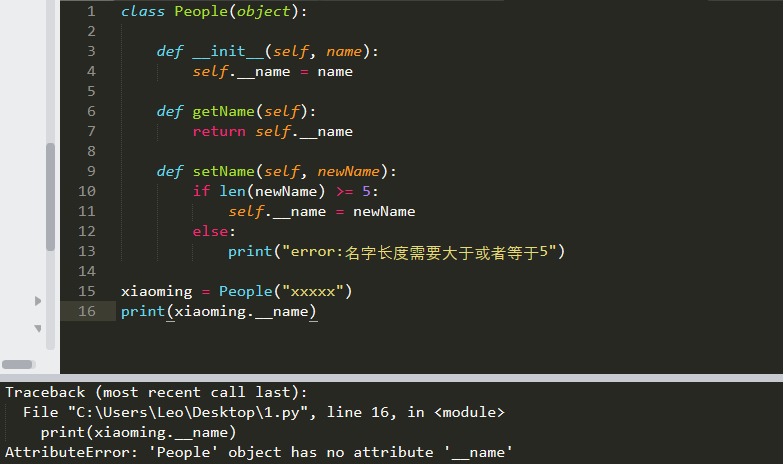
保护对象的属性:
为了更好的保存属性安全,即不能随意修改,一般的处理方式为
-
- 将属性定义为私有属性
- 添加一个可以调用的方法,供调用
-
- Python中没有像C++中public和private这些关键字来区别公有属性和私有属性
- 它是以属性命名方式来区分,如果在属性名前面加了2个下划线'__',则表明该属性是私有属性,否则为公有属性(方法也是一样,方法名前面加了2个下划线的话表示该方法是私有的,否则为公有的)。
单继承:
虽然子类没有定义__init__方法,但是父类有,所以在子类继承父类的时候这个方法就被继承了,所以只要创建Bosi的对象,就默认执行了那个继承过来的__init__方法
-
- 子类在继承的时候,在定义类时,小括号()中为父类的名字
- 父类的属性、方法,会被继承给子类
注意:
-
- 私有的属性,不能通过对象直接访问,但是可以通过方法访问
- 私有的方法,不能通过对象直接访问
- 私有的属性、方法,不会被子类继承,也不能被访问
- 一般情况下,私有的属性、方法都是不对外公布的,往往用来做内部的事情,起到安全的作用
多继承:
-
- python中是可以多继承的
- 父类中的方法、属性,子类会继承
print(C.__mro__) #可以查看C类的对象搜索方法时的先后顺序
重写父类方法与调用父类方法:
1. 重写父类方法
所谓重写,就是子类中,有一个和父类相同名字的方法,在子类中的方法会覆盖掉父类中同名的方法
2. 调用父类的方法
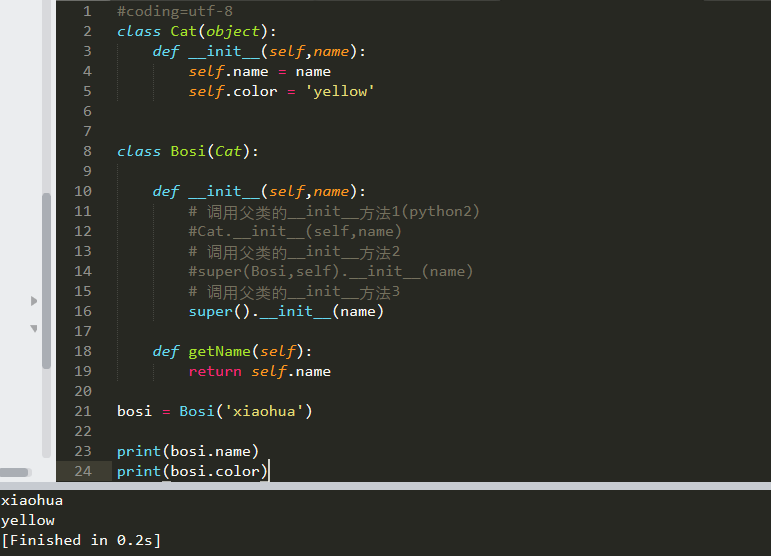
多态:
所谓多态:定义时的类型和运行时的类型不一样,此时就成为多态
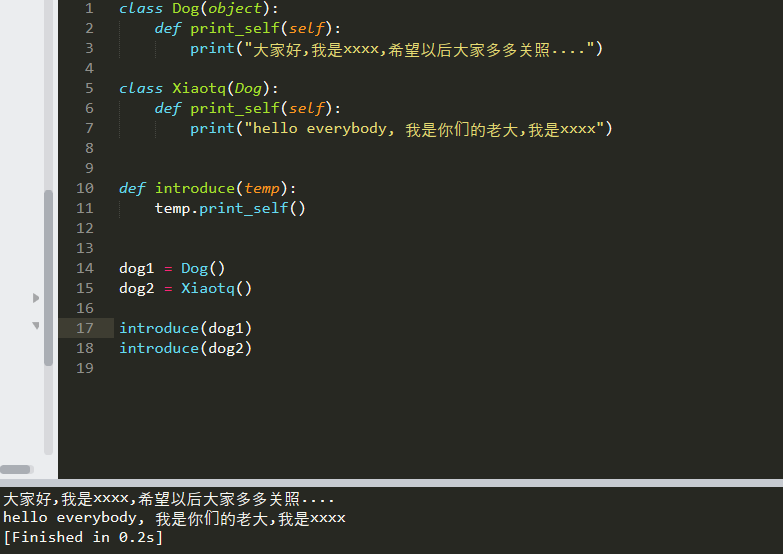
定义的时候不确定 调用哪个类中的方法,而是等到真的调用之后才确定,即定义时不确定 而是运行时确定这就称为多态
类属性、实例属性:
通过实例(对象)去修改类属性:
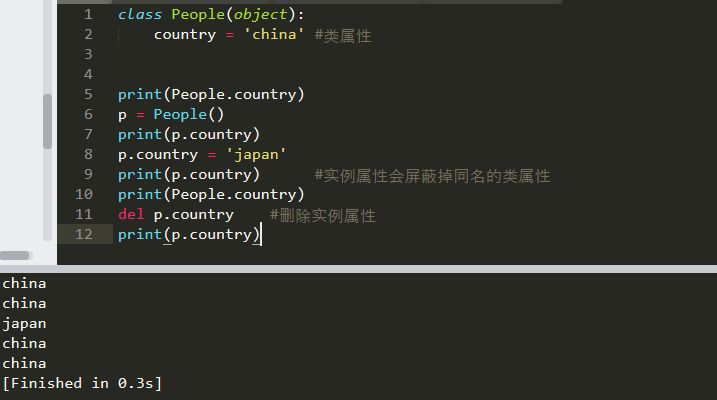
如果需要在类外修改类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,
不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
静态方法和类方法:
1. 类方法
是类对象所拥有的方法,需要用修饰器@classmethod来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls作为第一个参数(当然
可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以'cls'作为第一个参数的名字,就最好用'cls'了),能够通过实例对象和类对象去访问。
2. 静态方法
需要通过修饰器@staticmethod来进行修饰,静态方法不需要多定义参数
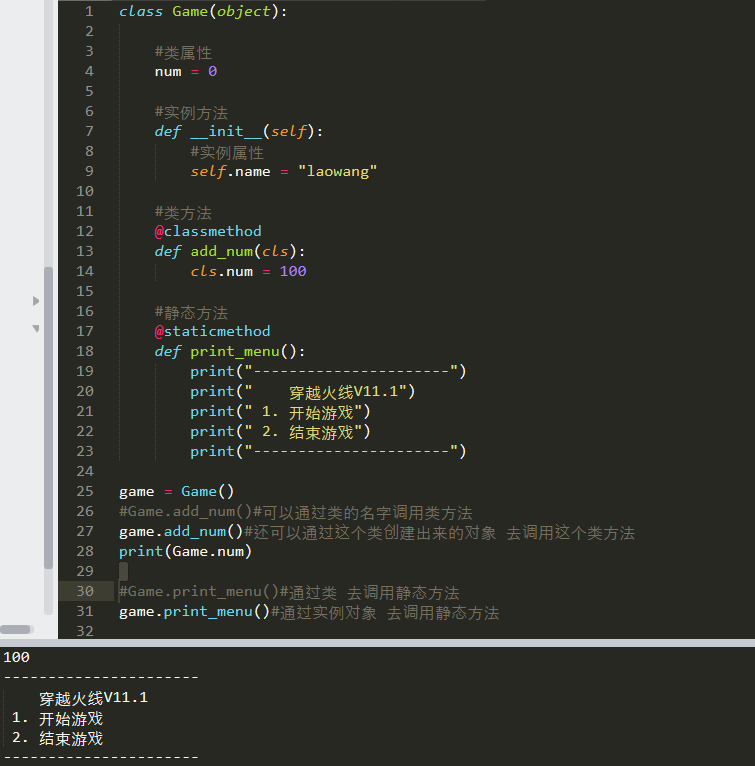
从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法;而实例方法的第
一个参数是实例对象self,那么通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实
例属性优先级更高。静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类对象来引用
工厂函数:


# 定义一个基本的4S店类 class CarStore(object): #仅仅是定义了有这个方法,并没有实现,具体功能,这个需要在子类中实现 def createCar(self, typeName): pass def order(self, typeName): # 让工厂根据类型,生产一辆汽车 self.car = self.createCar(typeName) self.car.move() self.car.stop() # 定义一个北京现代4S店类 class XiandaiCarStore(CarStore): def createCar(self, typeName): self.carFactory = CarFactory() return self.carFactory.createCar(typeName) # 定义伊兰特车类 class YilanteCar(object): # 定义车的方法 def move(self): print("---车在移动---") def stop(self): print("---停车---") # 定义索纳塔车类 class SuonataCar(object): # 定义车的方法 def move(self): print("---车在移动---") def stop(self): print("---停车---") # 定义一个生产汽车的工厂,让其根据具体得订单生产车 class CarFactory(object): def createCar(self,typeName): self.typeName = typeName if self.typeName == "伊兰特": self.car = YilanteCar() elif self.typeName == "索纳塔": self.car = SuonataCar() return self.car suonata = XiandaiCarStore() suonata.order("索纳塔")
定义了一个创建对象的接口(可以理解为函数),但由子类决定要实例化的类是哪一个,工厂方法模式让类的实例化推迟到子类,抽象的CarStore提供了一个创建对象的方法createCar,也叫作工厂方法。
子类真正实现这个createCar方法创建出具体产品。 创建者类不需要直到实际创建的产品是哪一个,选择了使用了哪个子类,自然也就决定了实际创建的产品是什么。
__new__和__init__的作用:
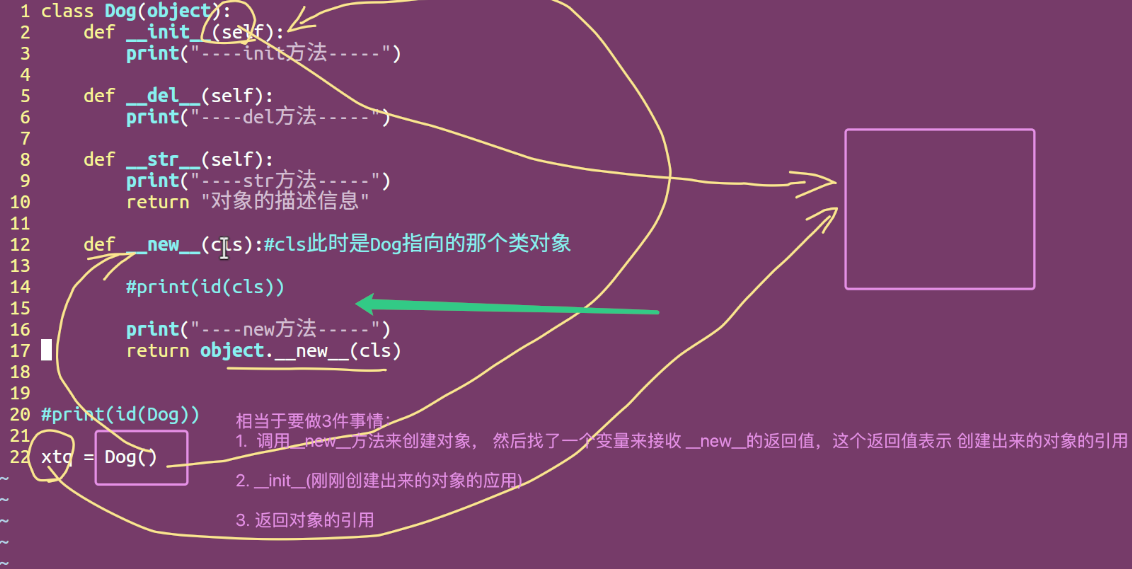
-
-
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供 -
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例 -
__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值 -
我们可以将类比作制造商,
__new__方法就是前期的原材料购买环节,__init__方法就是在有原材料的基础上,加工,初始化商品环节
-
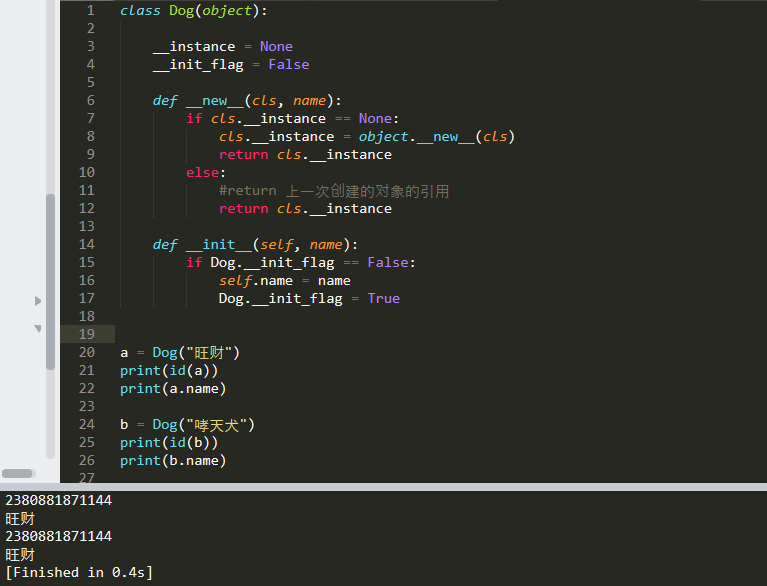
单例模式:
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。
1. 创建单例-保证只有1个对象

2. 创建单例时,只执行1次__init__方法
异常:
捕获异常:else
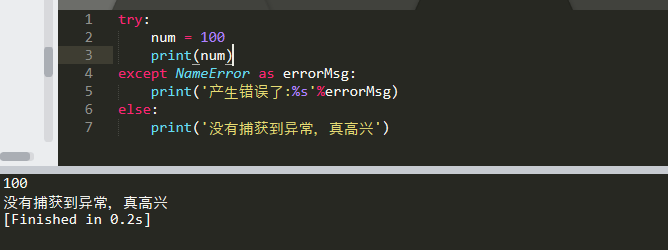
捕获异常:finally
在程序中,如果一个段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用finally。 比如文件关闭,释放锁,把数据库连接返还给连接池等

异常的传递:
1. try嵌套中
2. 函数嵌套调用中
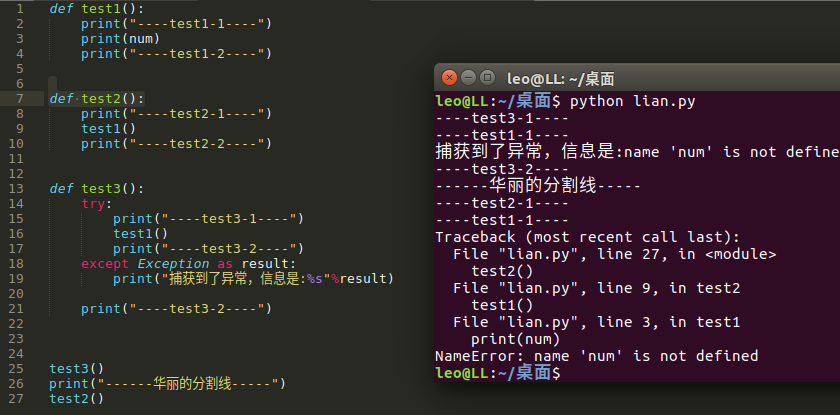
-
- 如果try嵌套,那么如果里面的try没有捕获到这个异常,那么外面的try会接收到这个异常,然后进行处理,如果外边的try依然没有捕获到,那么再进行传递。。。
- 如果一个异常是在一个函数中产生的,例如函数A---->函数B---->函数C,而异常是在函数C中产生的,那么如果函数C中没有对这个异常进行处理,那么这个异常会传递到函数B中,如果函数B有异常处理那么就会按照函数B的处 理方式进行执行;如果函数B也没有异常处理,那么这个异常会继续传递,以此类推。。。如果所有的函数都没有处理,那么此时就会进行异常的默认处理,即通常见到的那样
- 注意观察上图中,当调用test3函数时,在test1函数内部产生了异常,此异常被传递到test3函数中完成了异常处理,而当异常处理完后,并没有返回到函数test1中进行执行,而是在函数test3中继续执行
抛出自定义异常:
用raise语句来引发一个异常。异常/错误对象必须有一个名字,且它们应是Error或Exception类的子类
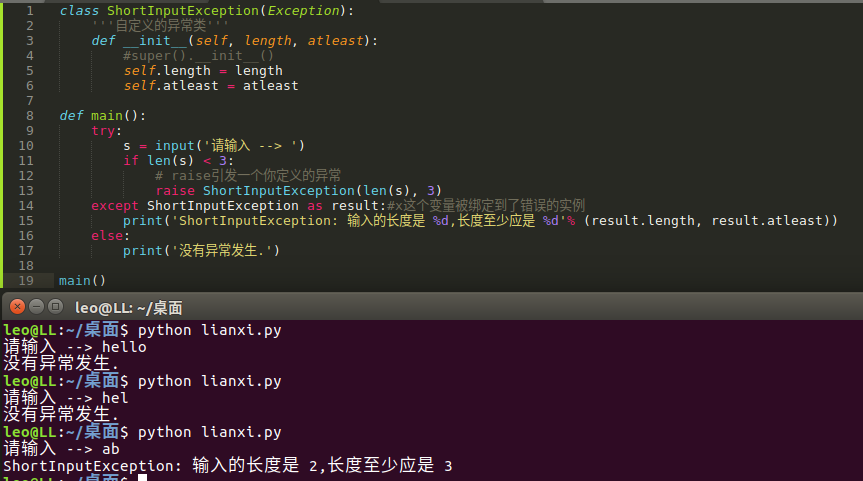
注:#super().__init__()
这一行代码,可以调用也可以不调用,建议调用,因为__init__方法往往是用来对创建完的对象进行初始化工作,如果在子类中重写了父类的__init__方法,即意味着父类中的很多初始化工作没有做,
这样就不保证程序的稳定了,所以在以后的开发中,如果重写了父类的__init__方法,最好是先调用父类的这个方法,然后再添加自己的功能
异常处理中抛出异常:

模块 :
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
如果一个文件中有__all__变量,那么也就意味着这个变量中的元素,不会被from xxx import *时导入
包:
-
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件,那么这个文件夹就称之为包 - 有效避免模块名称冲突问题,让应用组织结构更加清晰
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件有什么用:控制着包的导入行为
__init__.py为空:仅仅是把这个包导入,不会导入包中的模块
__all__:在__init__.py文件中,定义一个__all__变量,它控制着 from 包名 import *时导入的模块


 浙公网安备 33010602011771号
浙公网安备 33010602011771号