qca-wifi代码流程
转:https://blog.csdn.net/walker0411/article/details/73332737?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-2.no_search_link&utm_relevant_index=5
高通AP10.4开发者指南——WLAN(2.5 代码流程)
2.5 代码流程(Code Flow)
这部分讲解一些主要的配置通路、收发数据的通路。下面这些颜色,用于区分不同的模块。
2.5.1配置通路(Configuration Path)
WLAN驱动的配置路径主要包含:radio接口的初始化和去初始化(比如wifi network接口)、VAP的创建和删除(比如说ath network接口)。
2.5.1.1 驱动线程(Driver Threads)
同一时间可能有多个线程被启动。这些线程有:
- 传输线程(Transmit (OS context))
- 中断线程(Interrupt)
- 延迟中断处理线程(Deferred Interrupt Handler)
- Timer处理线程(Timers)
- Beacon处理线程(Beacon handling)
- ADDBA帧处理线(Addba exchange)
- 接收包乱序处理(Receive Reordering)
- MLME timer处理(鉴权/关联)(MLME timers (authentication/association))
- 同步处理(Synchronization (Lock Macros: OS-specific abstraction))
2.5.1.2 Tx和Rx的初始化(Tx and Rx Initialization)
Tx和Rx初始化包含如下内容:
- 为transmit & receive分配Descriptor
- 针对不同OS,初始化过程会有一些不同:
- NDIS请求驱动来分配receive buffer
- Unix OS变量维护一个common的buffer pool
- 对于AR93xx设备,status会进入到环状的packet buffer
2.5.1.3 设备attach过程(Device attach)
图2-4解释了radio interface通过PCI bus interface的初始化过程(通过其他bus interface的初始化过程不在本次讨论之列)。WLAN driver load后,radio interface通过ath_pci_probe进行初始化。每个radio interface都会进行一次device attach。 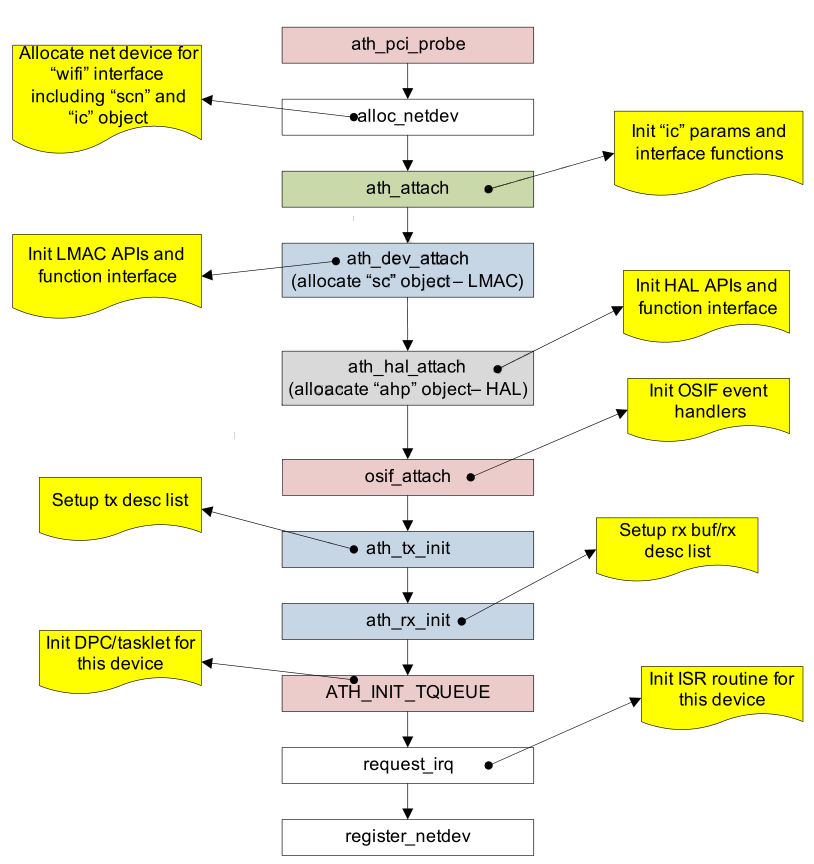
图 2-4 Radio Interface初始化(PCI Mode)
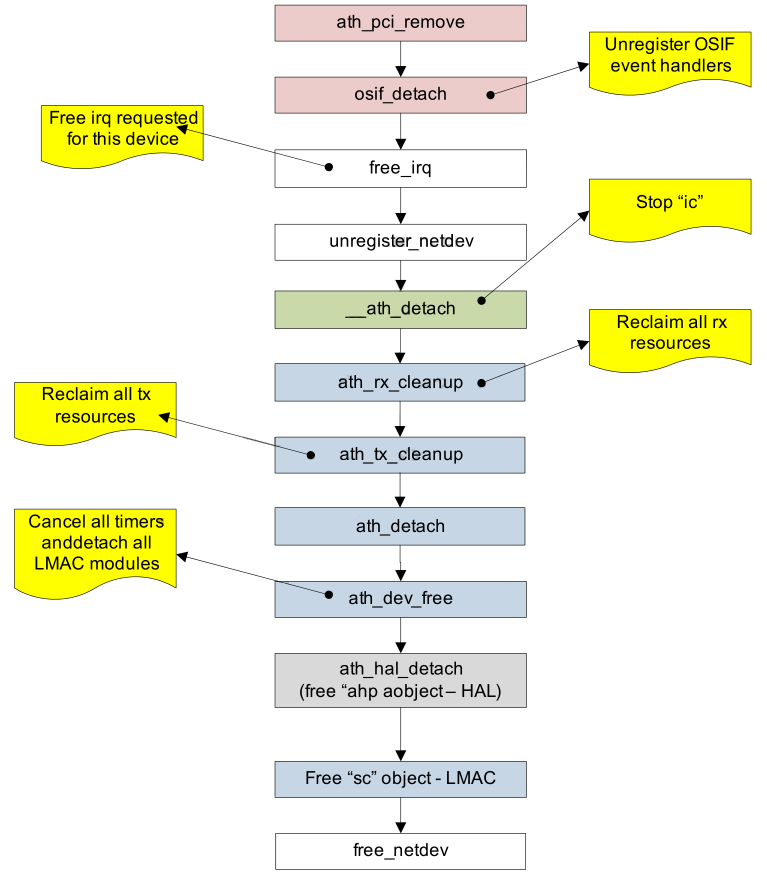
2.5.1.4 设备detach过程(Device detach)
driver unload的时候,会remove掉radio interface,使用ath_pci_remove函数来进行。这个函数是注册在pci_driver结构体中的,作为remove动作时的例行函数。
2.5.1.5 VAP的创建(VAP create)
VAP network interface通过“wifi” radio network interface ioctl SIOC80211IFCREATE进行创建。
这个“wifi” interface是这个VAP interface的父设备。图2-5说明了VAP创建的代码流程。每个VAP都有与之对应的“ath” network interface。 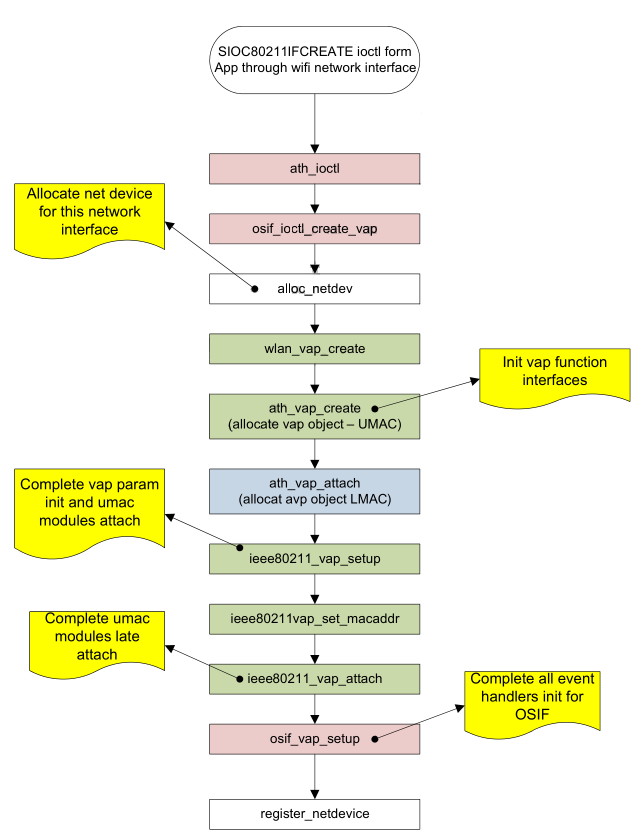
Figure 2-5 VAP创建的代码流程
2.5.1.6 VAP的删除(VAP delete)
VAP的删除,通过application调用VAP network接口ioctl SIOC80211IFDESTROY来完成。 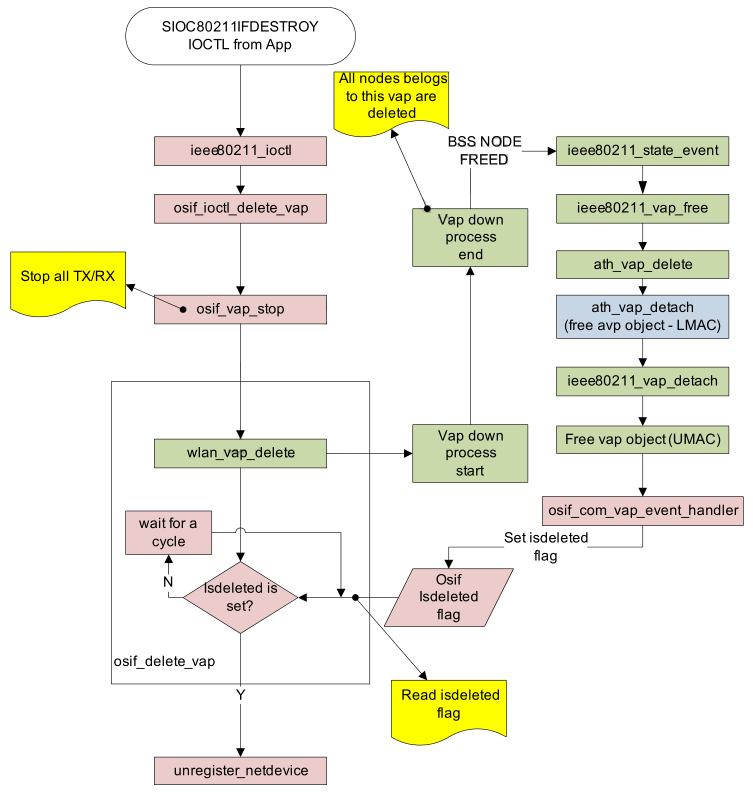
Figure 2-6 VAP Delete代码流程
2.5.1.7 VAP的启动(VAP start)
VAP的启动,是通过VAP创建时注册的network device open callback函数来完成。 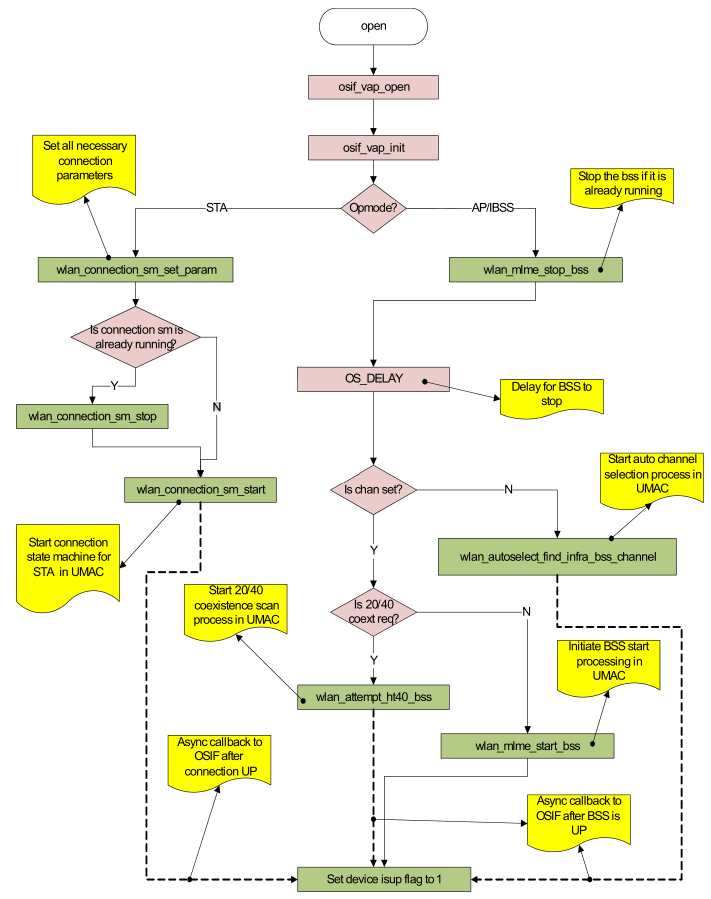
Figure 2-7 VAP Start代码流程
2.5.1.8 VAP的停止(VAP stop)
VAP的停止,是通过VAP创建时注册的network device stop callback函数来完成。 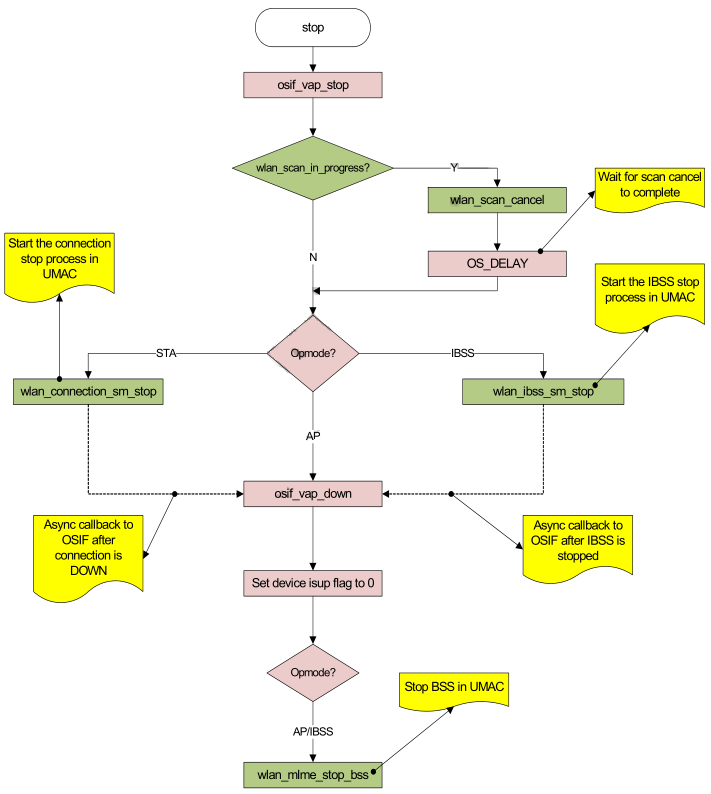
Figure 2-8 VAP Stop代码流程
2.5.2 数据通路(Data Path)
2.5.2.1 传输流(Transmit flow)
传输流主要存在于两种不同的执行路径:WLAN驱动从network stack中获取data packet,以及驱动处理过后,获取存储在software TID队列,或发送到硬件的data packet(假定这里在硬件队列中没有pending的传输packet)。packet传输完成后,硬件产生传输完成interrupt,驱动启动tx_tasklet任务来完成transmit流程。作为tx_tasklet的一部分,驱动释放已完成传输的packet,并运行TID scheduler,将软件TID queue中的packet,放到hardware queue中。
数据传输通路主要在OS shim层进行,并有如下特征:
- 调用wlan_vap_send (umac/txrx/ieee80211_output.c) 来启动传输流程
- Win7/Vista处理802.11 packet,其他的处理802.3
- Node查找与鉴权
- UMAC调用ath_tx_send (umac/if_lmac/if_ath.c)传递packet,构建packet
- 封装crypto headers, tid, crypto
- Packet传递到ath_tx_start_dma (lmac/ath_dev/ath_xmit.c)
- 完成Physical mapping to descriptor
- Descriptors分配与创建
- 若硬件queue中的阀值packet比较少,则操作单一packet入队列,或者将packe放到“tid”队列中处理
- 处理中断时创建Aggregate
- 中断对应queue
- tx中断发生时,驱动扫描有packet发送的node
- 通过“round robin”算法从中选择一个node
- 创建Aggregate并放到硬件队列中
2.5.2.2 传输中断的处理(Transmit Interrupt Handling)
传输中断与queue一一对应。中断发生时,ath_tx_edma_tasklet()将被调用。Rate信息可通过ath_rate_tx_complete_11n函数获取。
- 对于single packet,如果软件允许retry,则会有retry动作。
- 对于aggregate,ath_tx_complete_aggr_rifs() 函数用于处理block ack并return没有完成的传输queue的head(node,tid)
- 如果retry次数达到最大,则将packet送至OS shim层完成处理
- 通过调用ath_txq_schedule() (ath_xmit_ht.c)函数,来调度下一次传输处理
- 根据发送的packet筛选node(round robin算法,即轮询)
- 如果addba完成,则创建一个aggregate(之前failed的packet将做为新aggregate的一部分)
- 查找速率控制和选择速率序列
- 用于hardware传输的Queue packet/aggregate
2.5.2.3 传输通路管理(Transmit Path Management)
ieee80211_send_mgmt (wlan/umac/mlme/ieee80211_mgmt.c) 函数主要作用有:
- probe request
- probe response
- beacon
- action frames
- null data packets
这里的packet跟data packet很像。速率强制设定为最小速率,voice queue用于所有的management packet。
传输路径管理接口,通过ath_tx_mgt_send()函数提供给ath层。management task结束之后的代码流程与data packet的相同。
2.5.2.4 中断流程(Interrupt Path)
驱动初始化的过程中会注册中断. 流程如下:
- 入口 sc -> sc_ops -> isr() 映射到 ath_intr
- ath_intr (lmac/ath_dev/ath_main.c)调用HAL层(ah_isInterruptPending)来获取pending状态的中断
- ah_isInterruptPending根据平台映射到不同函数——AR93xx平台HAL使用的是ar9300IsInterruptPending()
- HAL层将不同平台的中断寄存器的每个bit的意义抽象出来,做一个common的映射:
HAL_INT_SWBA
HAL_INT_RX
HAL_INT_TX
… - ath_intr() 返回一个bool值来表明这个中断是否为当前使用者所创建的
- ath_handle_intr()通过OS来调度。
OS适配层与下面的内容关联:
- Windows平台中的DPC接口
- MacOS平台的handle_interrupt接口
- netBSD平台的紧急调用
- 调用指定的tasklet,来响应每个中断
- 发送中断的处理,在文件ath_edma_xmit.c的ath_tx_edma_tasklet()函数中结束。
- 接收中断的处理,在文件ath_edma_recv.c的ath_rx_edma_tasklet()函数中结束。
- 其他的中断也有类似处理。
- Beacon
- GPIO
- 错误处理,如overrun/underrun/fatal-chip-error
2.5.2.5 AR93xx的传输(AR93xx Transmit)
对于AR93xx的设备,有一个通用的循环链结构会上报传输的结束状态。每个硬件descriptor指针都会指向4个物理内存块。descriptor可以有多个链在一起。
- TX descriptor指针(TXDP) FIFO
- 长度为8个元素
- 每个队列有一个FIFO
- 2 个(最多)
2.5.2.5.1 数据传输流程(Data Transmit flow)
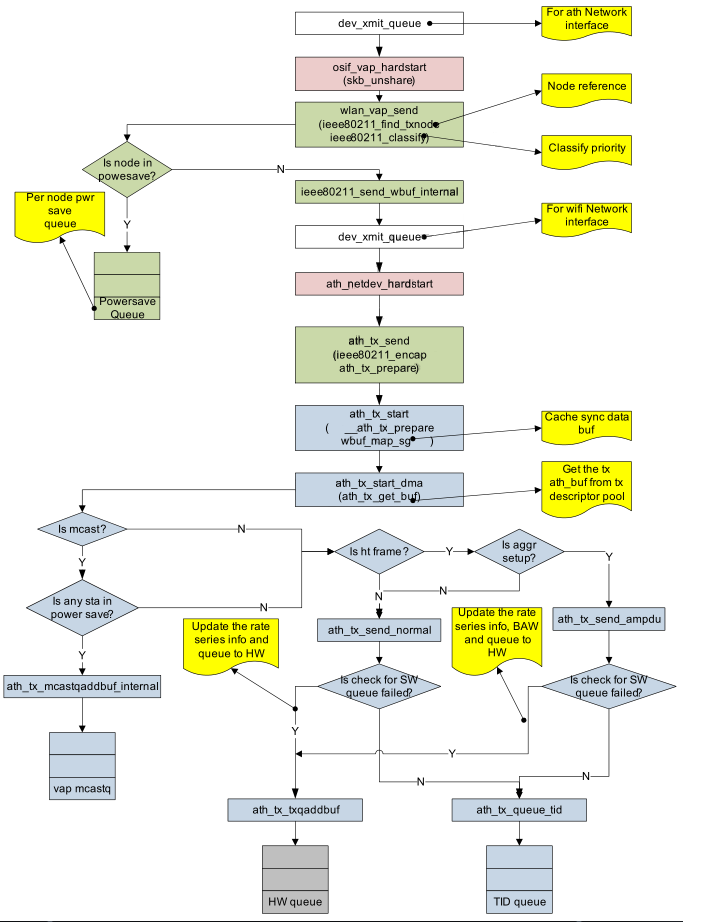
图 2-9 数据传输流程
2.5.2.6 数据传输完毕的处理流程(Data Transmit Completion Flow)
图 2-10 说明了TX完成中断的处理,以及tx是如何调度的,这些都是传输完毕的处理内容。 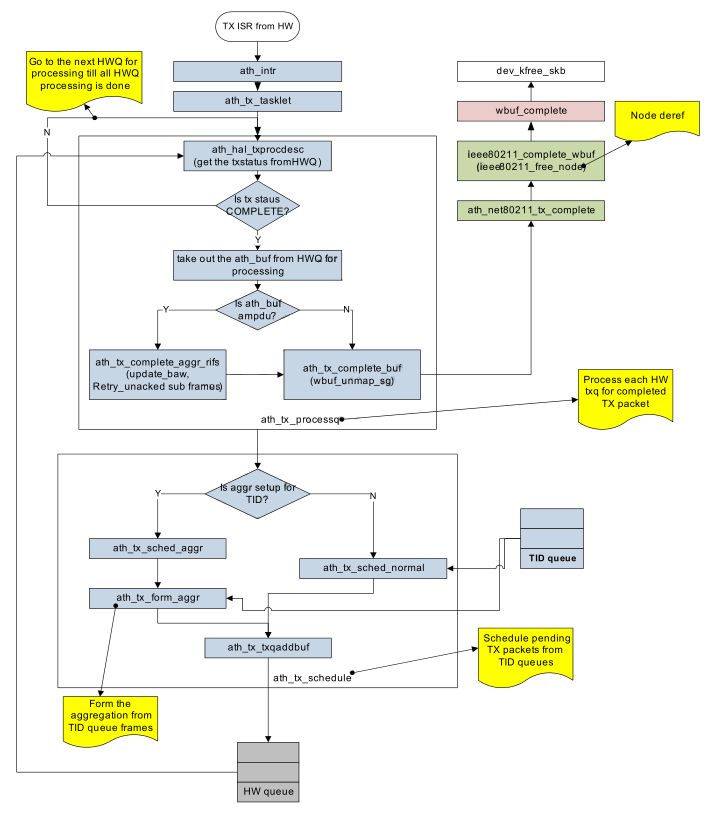
图 2-10 数据传输完毕的代码流程
2.5.2.7 接收流程(Receive flow)
硬件的接收帧通过HAL_INT_RX发送带指定驱动。有一些接收处理是延迟敏感的(如UAPSD触发),在这种情况下,处理在ISR上下文中处理。这些rx处理应该尽可能的保持到最小。其他主要的接收处理流程,在tasklet上下文中处理(ath_rx_tasklet)。rx帧的处理细节参看图2-11。 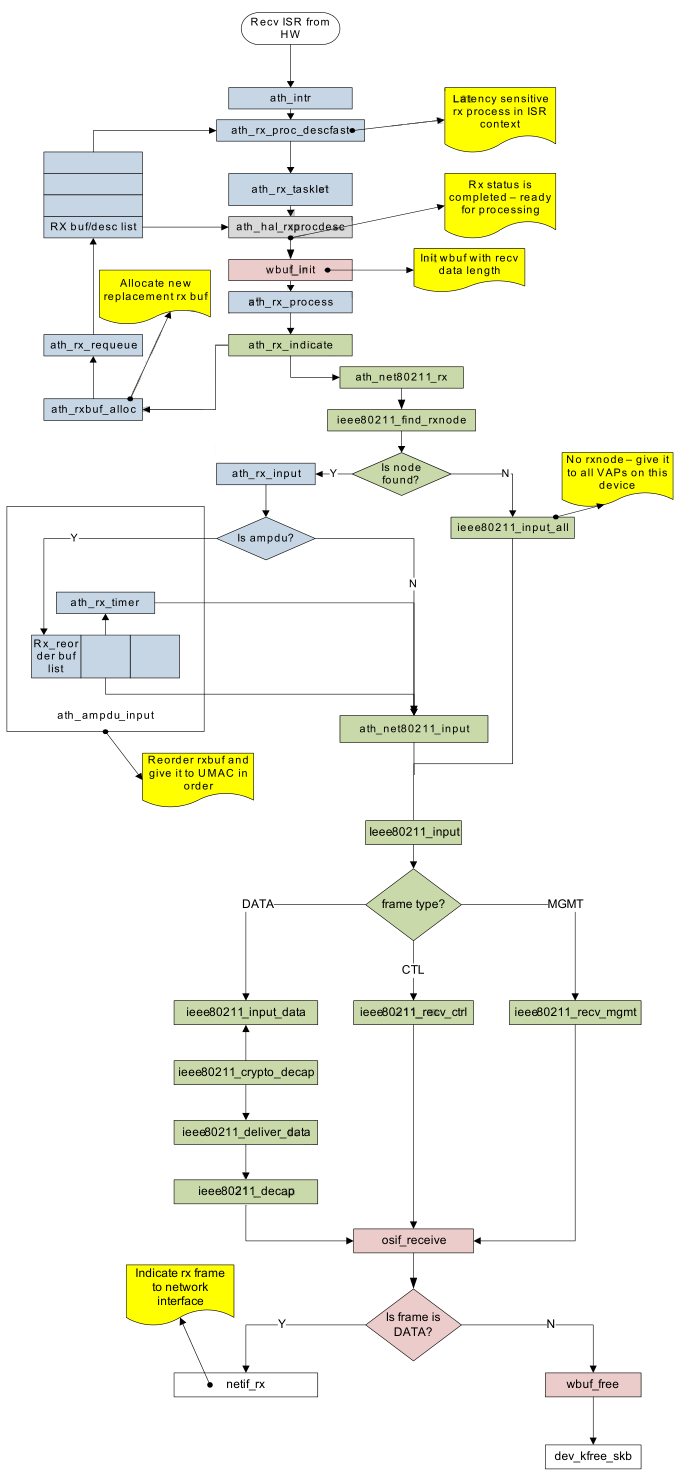
图 2-11 接收代码流程
2.5.2.8 单包接收(Single Data Packet Receive)
在单包接收task中,由ieee80211_input_data()进行处理。并根据STA/HOSTAP/IBSS这些不同的mode来进行解析和排序,并使用不同的广播。其他的event包括:
- Crypto DeCap和DeMic; 给软件提供处理crypto和demic的机会。
- 按需进行AMSDU的处理(ieee80211_amsdu_input)
- 按需调用ieee80211_deliver_data 转换成802.3
- 在HostAP mode下,如果目的节点已经associated,则包可以转发到wifi mediumu或转发到上面的桥接接口。
- 在STA mode下,包由栈处理。
2.5.2.9 聚合接收(Aggregate Receive)
在Aggregate接收中,包由AMPDU处理流程中的ath层进行处理。
ath_ampdu_input() (in lmac/ath_dev/ath_recv_ht.c)会获取packet。
- 如果处理的内容是qos data,则tid会从中解析出来。
- tid相关的rxbaw结构会从node中被抽取出来。
- Seq#映射到baw中,所有流程中的帧,此时会交由上层 (umac)进行处理。
- 传输通道会维护一个timer,如果timer到了,则所有的包都处理结束,window向下一个迁移。
处理完毕的packet,会与上面提到的单包处理的流程一样,继续进行处理。
2.5.2.10 AR93xx的接收处理(AR93xx Receive Handling)
AR93xx芯片支持高低优先级的接收ring。高优先级的用于UAPSD。低优先级的是通常的TID traffic。
ath_rx_edma_init() (在wlan/lmac/ath_dev/ath_edma_recv.c中) 会初始化一个固定大小的receive buffer、FIFO软件数据结构,并在ath_osdep.c调用OS-specific的函数来分配buffer。
接收准备就绪时,通过调用th_edma_startrecv() 来传递已分配的buffer、使能硬件上的的接收FIFO,设置MAC地址,并启动DMA引擎。
2.5.2.11 接收中断(Receive Interrupt)
当接收中断触发时,DPC函数会调用ath_rx_edma_tasklet(),来处理接收的高低优先级队列。
这个函数有如下功能:
- 取出第一个“完成”位被置位的buffer
- 如果完成了,则检查状态,取出所有完整的packet,并处理
- 将损坏的packet放回到硬件队列中以便重用
在闭环结构中处理完毕的packet,会传递到ath_rx_process (在the ath_recv.c文件中)。
针对不同硬件,这个函数是一个通用的函数。状态位处理后,带有状态的packet会传递到ath_osdep文件中的ath_rx_indicate()函数。
2.5.2.12 MacOS萍提的ath_rx_indicate()(ath_rx_indicate() for MacOS)
在这个函数中,packet会通过调用入口函数sc_ieee_ops -> rx_indicate()来传递给上层(UMAC)。一个新的buffer分配后,会发送到硬件的ready队列。
2.5.2.13 其他的接收event(Other Receive Events)
sc_ieee_ops -> rx_indicate()映射到if_ath.c文件(在umac/if_lmac路径下)的ath_net80211_rx()函数。
包含如下功能:
- 能够在监控mode的接口上打印packet内容
- 定位与这个packet associated的节点
- 针对ampdu节点,在ath层调用 sc_ops -> rx_proc_frame
- 对于单packet,会在ieee80211_input() (在umac/txrx/ieee80211_input.c文件中)函数中做进一步处理
- 数据packet会在ieee80211_input_data()函数中处理
- 管理packet会在ieee80211_recv_mgt()函数中处理
2.5.3 数据通路——局部卸载(Data Path — Partial Offload)
在新的一代802.11ac无线芯片中,比如QCA988x/989x和QCA999x/998x,多数的数据处理由主CPU转移到芯片本身来处理(目标处理器),这样可以降低主CPU负载,提高数据处理效率。AP SOC平台上的处理器,如AP135等,会运行一个小的host数据通路代码。在AP平台上,“低延迟”的代码路径被启用。host和target之间的通信,通过DMA来进行,这被称作Copy Engine。“Copy Engine”有8个管道。每个管道都被配制成双向通信。
所有的taget到host的通知,都是由一系列中断产生,中断的handler有如下功能:
1. 检查中断是否有错误
2. 关闭中断
3. 调度延迟进程进行进一步处理。(比如Linux的tasklet)
在Partial Offload架构中,host和target的功能划分可以大体按照下面进行:
Host Tx
- 栈中的单个包或多个包所使用的buffer直接由DMA映射
- 建立基于target的扩展数据
- 建立copy engine来传输扩展数据或部分数据包
-
Tx闭环处理,包含两个步骤:
- Tx descriptor下载完毕
- Tx packet处理t完毕
只有上面两个部分都结束,packet才会被释放。
Target Tx
- packet按照WMM访问类别进行分类。
- 汇总每个TID,汇总setup & teardown。
- 查询率。
- 通过HTT消息,表明packet结束。
Host Rx
- 通过DMA发送Rx buffer到MAC硬件。
- 丢弃、重排序或转发packet到栈中(取决于HTT消息)。
Target Rx
- Block Ack窗口管理和发送Block Ack.
- 发送HTT Rx indication消息到host
header的封装/解封,以及加密/解密(如果使能了安全机制),在MAC硬件中进行。
图 2-13 列出了数据通路的相关模块:
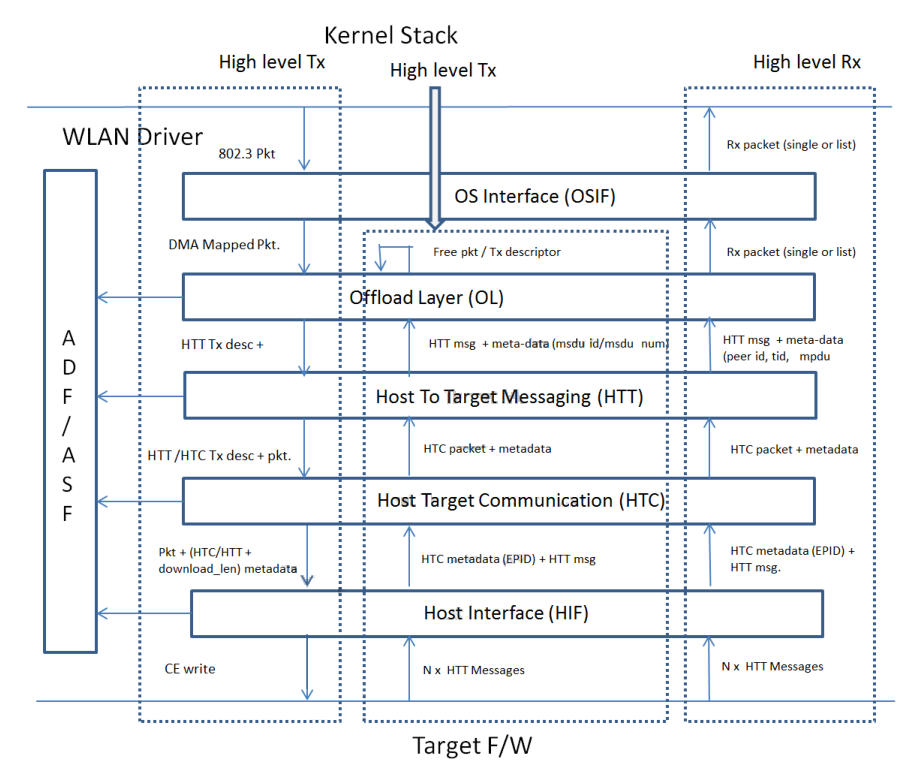
图 2-13 TxRx 架构概述
2.5.3.1 Tx处理(Tx Processing)
对于Partial Offload的通路,Tx处理流程可以分为两个部分:
- packet的传输
- packet的结束
- 标记完成传输的packet
WLAN驱动可以从栈中接收下面几种类型的packet: (取决于配置):
- 普通Ethernet packet (包含或不包含一个VLAN header)
- 一个本地的Wi-Fi (802.11)packet(包含或不包含一个VLAN header)
- 一个裸802.11packet
下面是Tx处理的主要feature:
packet的传输
- packet通过OS适配层提供的主要节点进入驱动。DMA到buffer list的映射在此时完成。同时packet会下放到通用“Offload”(OL)层做进一步处理。
- OL层的入口是 ol_tx_ll()
-
ol_tx_ll()
- 分配OL层Tx descriptor
- 存储packet中控制块里的meta-data碎片 (linux中使用结构体struct cb {})
- 准备HTT descriptor,并嵌入到OL Tx descriptor
- 填充HTT descriptor中的分散-收集list
- 调用 ol_tx_send()
-
ol_tx_send() 将packet传递到HTT层。
- htt_tx_send_std() 添加HTT/HTC fragment到qdf_nbuf meta-data,设置每个fragment的endianness,分配并准备一个HTC (仅软件内部) packet,并通知HTC层。
- HTCSendDataPkt() 检查可用的HIF资源,如果没有足够的资源则将packet丢弃。这个函数会填充HTCdescriptor,并传递给HIF层。
- HIFSend_head() 添加fragment到qdf_nbuf _cb的meta-data (fragment由stack +HTT/HTC fragment组成),并放到Copy Engine (CE) send-list中和激活CE。
- CE_sendlist_send() 通过将copy engine环索引,写入target上对应的CE register来传递buffer。CE slot的数量与包中的fragment数量(= DMA已映射的地址) 对等。如果linux从栈中一次发送一个packet,则每个packet所使用的CE slot数为2。
- CE 4 用于从host到target的 HTT + HTCdescriptor,以及数据packet的一部分。
NOTE
对于一个已知的packet,驱动会下载24byte的HTT/HTC header + 一部分固定的数据packet到target端。这个下载动作很有必要,即使这部分数据packet已经由MAC层h/w的host内存,放在了DMA中,也需要进行,这样target端才能解析packet header,并按照packet类型分类。下载的长度包括 L2 headers + L3 headers的2 bytes(Ipv4 TOS / IPV6 Flow label) 长度的信息。下载从行度在驱动初始化的时候设置,使用下面的值:
Ethernet packet -> 28 bytes
Native 802.11 packet -> 44 bytes
Raw 802.11 packet -> 50 bytes
图 2-14 传输流程
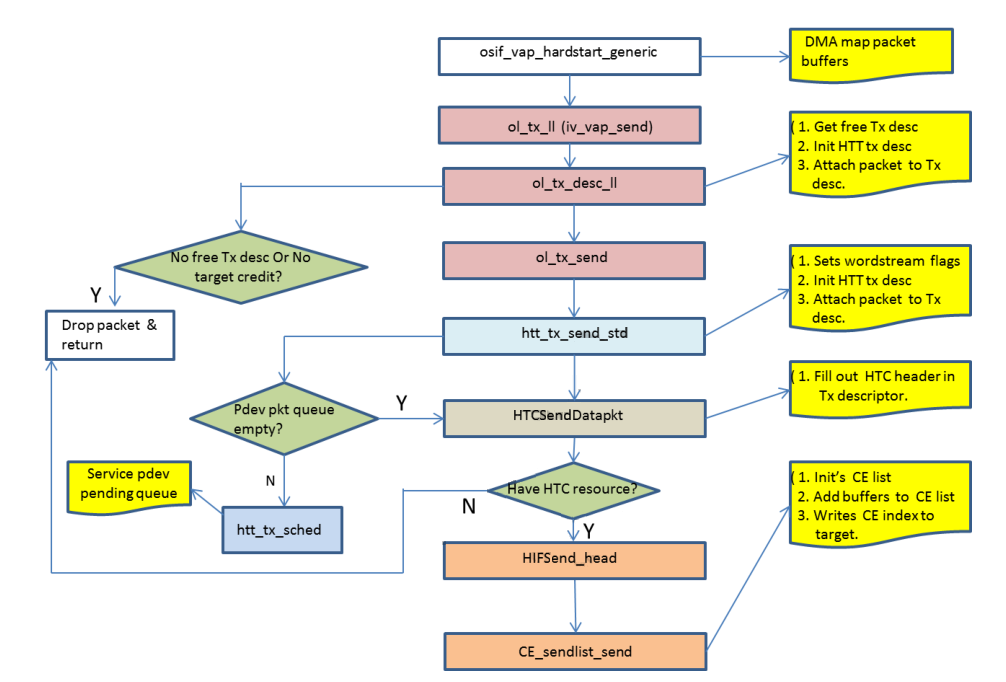
传输packet的完成
Tx完毕通知包含两部分:
-
target端完成下载descriptor。
- 这个完毕通知只是一个从target到host的中断,用来通知descriptor传输结束。
- 这个可以用于释放Copy Engine索引,但不是实际的packet的meta-data。
- 为了CPU更有效率,用于CE 4的这个中断已经被禁用了。替代的方案是,这个CE硬件索引会被轮询,用于查找已完成的descriptor数。
-
真实packet的传输结束。
- 会产生一个从target到host的HTT消息。
- 会在CE 1上的每个Tx PPDU都产生中断作为通知,主要用于从target到host的HTT消息。
- HTT消息携带所有完成的packet的ID。根据这些ID,所有实际的packet和所有的meta-data,比如HTC packet,OL Tx descriptor等等,都会被释放。
- 释放每个copy engine所处理的HTT消息buffer。这些buffer会在函数return之前,重新分配,并通过HTT消息handler传递回去。
图 2-15 发送完成的处理流程
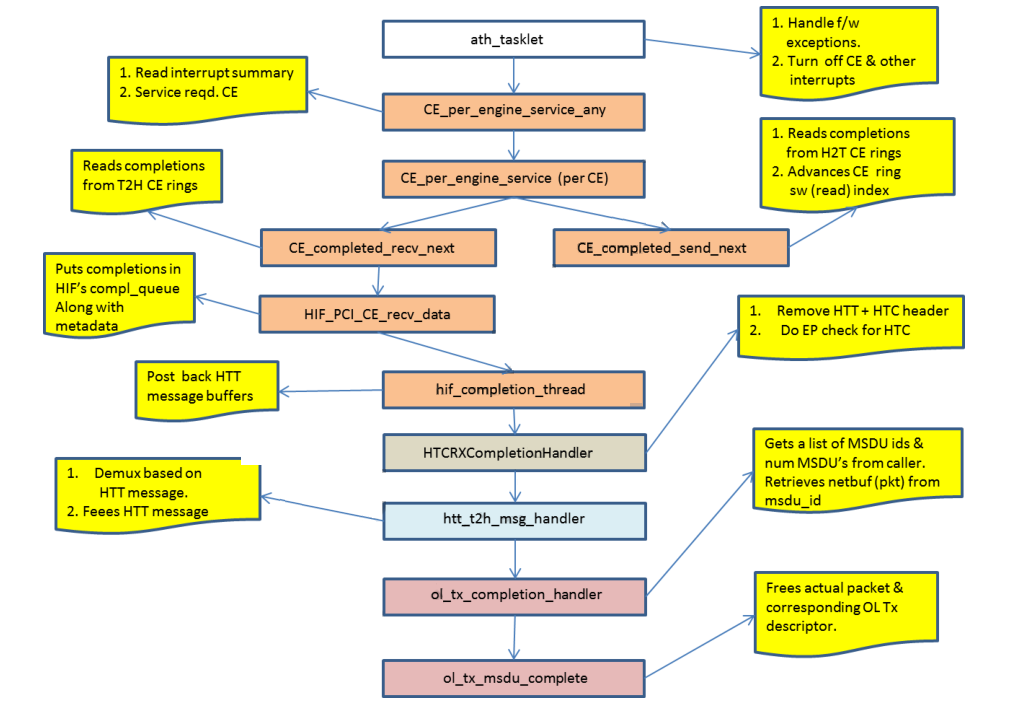
2.5.3.2 Rx处理(Rx Processing)
接收处理主要包含两个部分:
- 处理由target发向host的HTT消息中的Rx通知。
- 分配并传递Rx buffer到MAC硬件,来处理实际的数据。
处理Rx标识
- 从target到host的Rx标识,是在每一个PPDU中断中的。
- 从target到host的Rx标识通过HTT消息来传递,因此他使用target到host的专用copy engine 1。
- CEhandler从TID队列中,获取HTT消息buffer,并经由HIF、HTC、最终到达HTT。
- HTT消息handler(htt_t2h_message_handler())分解消息,并调用OL handler函数ol_rx_inidication_handler()。
- ol_rx_indication_handler()查找Rxdescriptor(实际的Rx buffer),并从MPDU抽取MSDU,并将每个MSDU入栈。
Rx buffer的分配和发送
Rx buffer在ol_rx_indication_handler()函数返回之前,会传递给硬件,
图 2-16 Rx处理流程
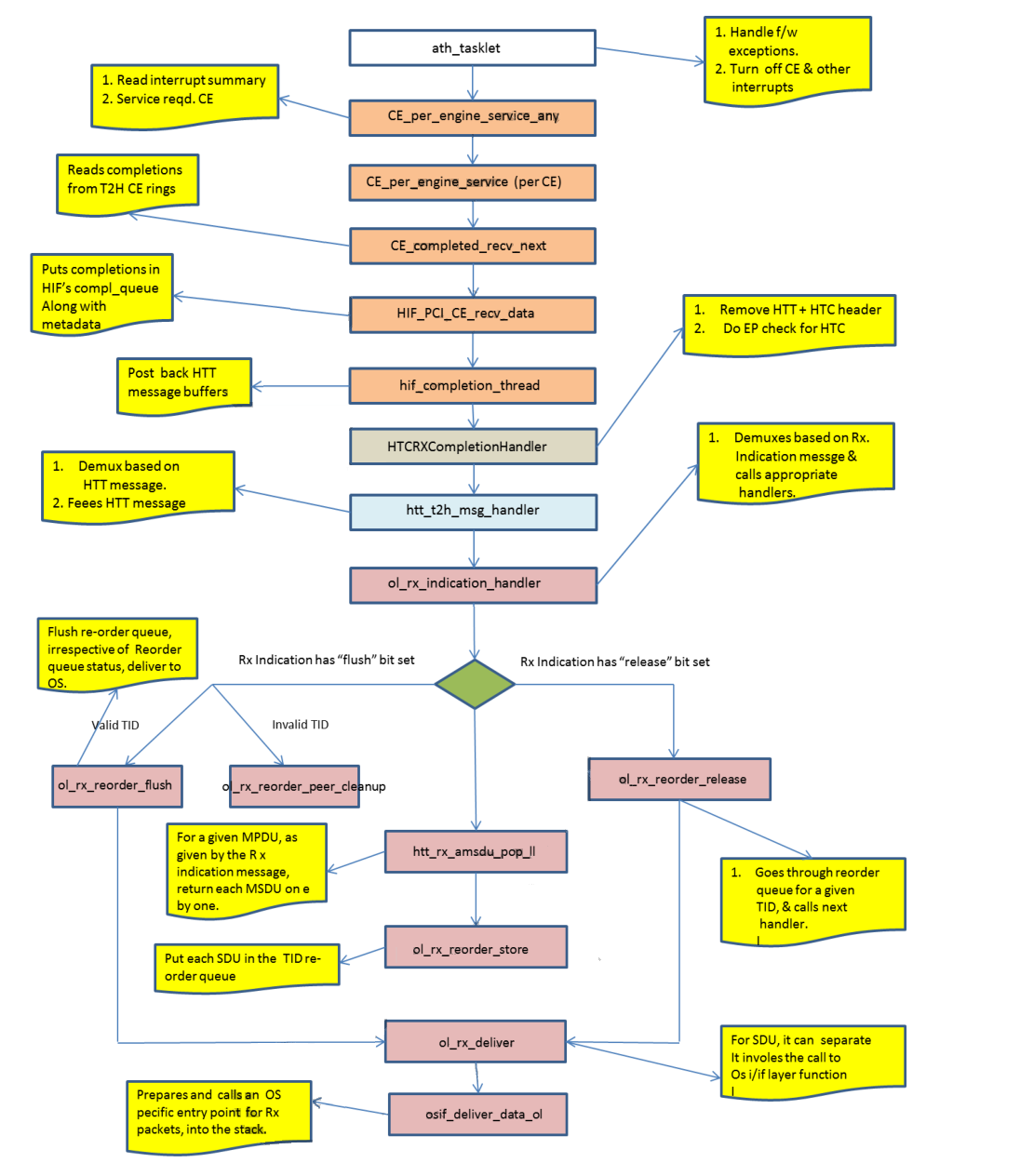
2.5.3.3 数据通路和数据结构
下面的章节,列举了一些offload层数据路径的重要结构。
2.5.3.2.1 ol_txrx_pdev_t: 与TxRx物理设备对应
这个结构主要是,与WLAN驱动协作的物理设备,在offload mode下的收发特性。一个OL物理设备代表一个射频接口(比如wifi0,wifi1等等)。这个结构体维护下面这些重要的信息:
- 非透明OS设备的handler
- 与更底层的物理设备的接口,比如HTT
- 针对特殊物理设备(Ethernet, native Wi-Fi, raw等等)的帧格式
- 与当前物理设备(PDEV)对应的虚拟设备(VDEV)列表
- Peer Id到Peer Object的映射数组
- 接收处理产生的信息;比如说Rx re-order数组
- 调用OS接口层注册的Rx处理回调函数
- TxRx host统计计数TxRx host statistics
- Tx descriptor池
2.5.3.2.2 ol_txrx_vdev_t: 与TxRx虚拟设备对应
这个结构主要指,对于一个已知的VAP,offload mode下的虚拟设备与之对应的OL物理设备的收发特性。一个VDEV实体对应一个网络接口(如 ath0, ath1等等)。多个VDEV实体可以映射到OS层中,可见的、单个OL物理设备(PDEV)。
- TxRx物理设备的handler(ol_txrx_vdev_t)
- VAP的MAC地址
- 当前vdev的虚拟设备ID
- 与当前VAP(vdev)连接的对端设备列表
- Tx和Rx处理函数的函数指针
- 速率控制信息(在host端完成的)
- VAP的可选mode
2.5.3.2.3 ol_tx_desc_t: 与Tx descriptor对应
这个结构体代表OL Tx descriptor。一个Tx descriptor池空间会在驱动初始化的时候申请。池的size等于1K,这与射频接口的传输descriptor数量是一致的。对于每个有驱动传输的packet,都有一个对应的OL Tx descriptor会被分配出来与之对应。每个OL Tx descriptor都有自己的唯一ID。这个ID会在meta-data中携带给target。Target会将这个Tx descriptor的ID作为Tx传输结束message的一部分,依次返回给host,并由host释放Tx包和OL Tx包。
2.5.3.2.4 ol_txrx_peer_t: 与peer node对应
这个结构体存储了已连接的对端节点的重要状态信息。这个数据结构主要用在Rx流程中。其包含的一些重要的信息如下:
- 对端已连接的VEDV的handler。
- 每个已连接的对端ID列表。这些对端ID主要用于获取对应的节点结构体(利用对端ID到节点的映射机制)。
- 已连接对端,所对应的本地VAP的MAC地址。
- 每个TID的Rx重排序数组。这个数组会缓存Rx packet,直到当这个驱动从Target接收到一段连续的packet,或者从Target收到FLUSH消息。当收到FLUSH消息时,整个数组会被发送到网络栈中,不管TID packet数组是否已存有连续的packet。
- 安全信息。
2.5.3.2.5 cvg_nbuf_cb: 聚会网络buffer控制块
这是一个非常重要的meta-data结构,存储于inline或作为一个在OS专用data buffer结构中(比如linux的sk_buff,NetBSD的mbuf,Windows的NBLs)的指针。
这个meta-data结构,作为每个packet的一部分,维护了下面这些内容:
- 分散或集聚由OS下发到驱动的,物理地址&长度的碎片list。
- 由驱动添加的物理地址碎片和碎片的长度(在Tx通路中,target所需求的HTT/HTC meta-data)。
2.5.4 OL数据结构(OL Data Structures)
对于offload架构解决方案,OL(Off-Load)层是处于Unified MAC和其底层中间,比如target固件的WMI (无线管理接口) / WDI (无线数据接口)。参看图 2-18 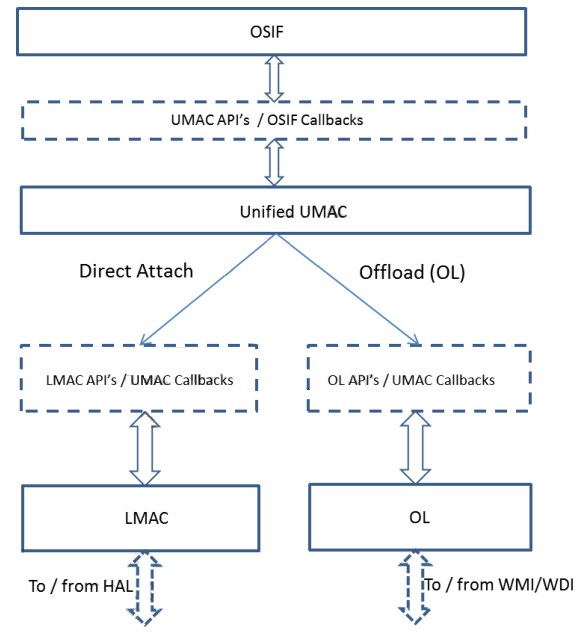
图 2-18 Offload层架构
从图2-18中可以很明显的看出。大部分OSIF层和UMAC层数据结构没有什么变化,并可以在offload模型中被重用。LMAC和其底层并没有应用在offload模式下,而是使用OL和其底层,比如WMI和WDI来代替。OL层有一些新的数据结构,将会在下面的小节中说明。
2.5.4.1 ol_ath_softc_net80211: OL radio device结构
这个结构属于OL层的“scn”模块,主要抽象出了radio接口。在offload架构中,目标固件code实例和radio接口之间有一个1:1的映射。这个数据结构还会截取在指定radio接口上运行的code信息。它嵌套了UMAC层ieee80211结构体。
本结构体中的一些重要内容如下:
- UMAC通用设备结构体 (sc_ic)
- OS
- 设备handler
- OS层注册的回调函数,会在目标迁移到service ready状态时调用.
- 目标的状态信息;如version/type/status
- 固件下载相关信息 (BMI information)
- 其他层的handler如WMI, HTT, HTC, HIF
- Channel和Tx功率信息
- 存储TxRx统计计数的结构体
- 同步锁
2.5.4.2 ol_ath_vap_net80211: OL network interface结构
ol_ath_vap_ieee80211是WLAN network接口在offload层的抽象。每个WLAN network接口在UMAC层通过“Virtual AP” (VAP)来表示,并与底层物理device/radio接口对应,比如“wifi0”, “wifi1”等等。一个VAP主要呈现出access point的操作模式,access point可以是一个host access point,一个IBSS或一个station。
存储在这个结构图中的重要信息如下:
- UMAC层VAP object (av_vap)
- OL层底层的物理设备 (OL层scn模块)
- 每个VAP数据通路结构体的handler(av_txrx_handle)
- 用于beacon的相关信息(如offload mode, beacon buffer, probe templates etc.)
- Timer,主要用于cleanup。
- 同步锁。
2.5.4.3 ol_ath_node_net80211: OL network interface结构
ol_ath_node_ieee80211是offload层在UMAC节点的抽象。一个UMAC节点代表了一个在HOST AP模式下已连接的station,或一个IBSS模式下的ad-hoc station,或一个infra-structure模式下的BSS。已连接的节点list,代表VAP的本地网络。OL节点结构包含下面内容:
- UMAC层节点 (an_node)
-
VAP数据通路objecthandler (an_txrx_handle)
NOTE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号