

python正则表达式常用4个方法总结说明
正则表达式只针对字符串,进行各种操作的
用途:
1、匹配 - 符合规则的字符串,则认为匹配了。
2、提取 - 提取出符合规则的字符串。
python中通过re模块来处理正则表达式。re模块的常用方法如下:
re.match(re规则,字符串):从头开始匹配。从字符串的第一个字符开始匹配,如果第一个字符不匹配规则,那么匹配失败。
re.search(re规则,字符串):匹配包含。不要求从字符串的第一个字符就匹配。只要字符串当中有匹配该规则的,则就匹配成功。
re.findall(re规则,字符串):把所有匹配的字符放在列表中并返回。
re.sub(re规则,替换串,被替换串):匹配字符并替换。
re.subn(re规则,替换串,被替换串):匹配字符并替换,返回元组类型(替换后的字符串,被替换次数)
1、匹配1个字符
. 除换行符以外的所有字符 \n
\d 只匹配数字0-9
\D 匹配非数字
\w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”, 支持中文
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[0-9] 匹配数字
[abcd] 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”
[a|b] 匹配x或y(单字符)。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”
2、数量匹配
* 匹配前一个字符,0次或者多次
+ 匹配前一个字符,1次或者多次
? 匹配前一个字符,0次或1次
{n} 匹配前一个字符n次
{n,m} 匹配前一个字符最少是n次,最多是m次
{n,} 匹配前一个字符最少是n次,没有下限。
贪婪模式: 尽可能的匹配更多更长
非贪婪模式: 尽可能的匹配更少 在数量表达后面加上?
3、边界匹配:
^ 匹配输入字符串的开始位置
$ 匹配输入字符串的结束位置
4、匹配分组:()
#(\w+?)#
#(\w+)#
#(.+?)#
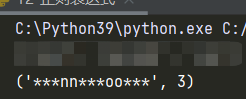
另外,subn()方法举例
aa ="kkk"
bb ='kkknnkkkookkk'
c =re.subn(aa,'***',bb )
print(c)
文章转载https://www.cnblogs.com/Simple-Small/p/9150947.html#4005587


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)