第五次作业
作业①
1)、使用Selenium框架爬取京东商城某类商品信息及图片
JDspider.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
# Initializing database
try:
self.con = sqlite3.connect("phones.db")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table phones")
except:
pass
try:
# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# Initializing images folder
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
# 取下一页的数据,直到最后一页
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break


2)、心得体会
这一个作业主要是对ppt上的代码进行复现,一开始先尝试对代码看懂,有了一定的理解后再照着ppt进行复现,对于缩进的处理也会更好一些,出现的错误也会更少。不然这么长的一段代码要是没有理解好,某个地方的缩进打错,确实挺头疼的。
作业②
1)、使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息
Seleniumstockspider.py
import datetime
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
class Myspider:
def startUp(self, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)#
self.driver.get(url)
self.No = 0
self.flag = 0
try:
print("opened")
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "", db = "stock", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table stocks")
except:
pass
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
if self.opened:
self.cursor.execute("create table stocks (id varchar(32), bStockNo varchar(32) primary key, bName varchar(32), bNewPrice varchar(32), bPriceLimit varchar(32), bChangeAmount varchar(32), bTurnover varchar(32), bVolume varchar(32), bRise varchar(32), bHighest varchar(32), bLowest varchar(32), bTodayOpen varchar(32), bYesterdayReceive varchar(32))")
def closeUp(self):
try:
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, code, name, new_price, price_limit, change_amount, turnover, volume, rise, highest, lowest, today_open, yesterday_receive):
try:
sql = "insert into stocks (id,bStockNo,bName,bNewPrice,bPriceLimit,bChangeAmount,bTurnover,bVolume,bRise,bHighest,bLowest,bTodayOpen,bYesterdayReceive)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (self.count, code, name, new_price, price_limit, change_amount, turnover, volume, rise, highest, lowest, today_open, yesterday_receive))
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(2)
# print(self.driver.current_url)
stocks = self.driver.find_elements_by_xpath("//div[@class='listview full']//tbody//tr")
for stock in stocks:
code = stock.find_element_by_xpath(".//td[position()=2]//a").text
name = stock.find_element_by_xpath(".//td[position()=3]//a").text
new_price = stock.find_element_by_xpath(".//td[position()=5]//span").text
price_limit = stock.find_element_by_xpath(".//td[position()=6]//span").text
change_amount = stock.find_element_by_xpath(".//td[position()=7]//span").text
turnover = stock.find_element_by_xpath(".//td[position()=8]").text
volume = stock.find_element_by_xpath(".//td[position()=9]").text
rise = stock.find_element_by_xpath(".//td[position()=10]").text
highest = stock.find_element_by_xpath(".//td[position()=11]//span").text
lowest = stock.find_element_by_xpath(".//td[position()=12]//span").text
today_open = stock.find_element_by_xpath(".//td[position()=13]//span").text
yesterday_receive = stock.find_element_by_xpath(".//td[position()=14]").text
self.count += 1
print("{:^2}{:>10}{:>10}{:>10}{:>10}{:>12}{:>13}{:>15}{:>12}{:>12}{:>12}{:>12}{:>12}".format(self.count, code,name,new_price,price_limit,change_amount,turnover,volume, rise,highest,lowest,today_open,yesterday_receive))
self.insertDB(code, name, new_price, price_limit, change_amount, turnover, volume, rise, highest, lowest, today_open, yesterday_receive)
'''
# 取下一页的数据,直到最后一页
try:
self.driver.find_element_by_xpath("//a[@class='next paginate_button disabled']") # 此时本版块已经到达最后一页
self.flag = 0
if self.flag == 0:
button = self.driver.find_element_by_xpath("//ul[@class='tab-list clearfix']//li[position()=2]") # 找到上证A股的板块按钮
time.sleep(2)
button.click()
self.flag += 1
self.processSpider()
elif self.flag == 1:
button = self.driver.find_element_by_xpath("//ul[@class='tab-list clearfix']//li[position()=3]") # 找到深证A股的版块按钮
time.sleep(2)
button.click()
self.flag += 1
self.processSpider()
except:
nextPage = self.driver.find_element_by_xpath("//a[@class='next paginate_button']")
nextPage.click()
time.sleep(2)
self.processSpider()
'''
# 上面注释掉的代码为爬取直到最后一页的方法,但是感觉爬取的数据过多,于是选择爬取前三页就好了,方法大同小异
if self.driver.find_element_by_xpath("//a[@class='paginate_button current']").text == "3" : # 已经到第三页了,开始爬取下一个版块
if self.flag == 0:
button = self.driver.find_element_by_xpath("//div[@id='tab']//ul[@class='tab-list clearfix']//li[position()=2]") # 找到上证A股的板块按钮
time.sleep(2)
button.click()
self.flag += 1
self.processSpider()
elif self.flag == 1:
button = self.driver.find_element_by_xpath("//div[@id='tab']//ul[@class='tab-list clearfix']//li[position()=3]") # 找到深证A股的版块按钮
time.sleep(2)
button.click()
self.flag += 1
self.processSpider()
else:
nextPage = self.driver.find_element_by_xpath("//a[@class='next paginate_button']")
nextPage.click()
time.sleep(2)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = Myspider()
while True:
print("1.爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
break

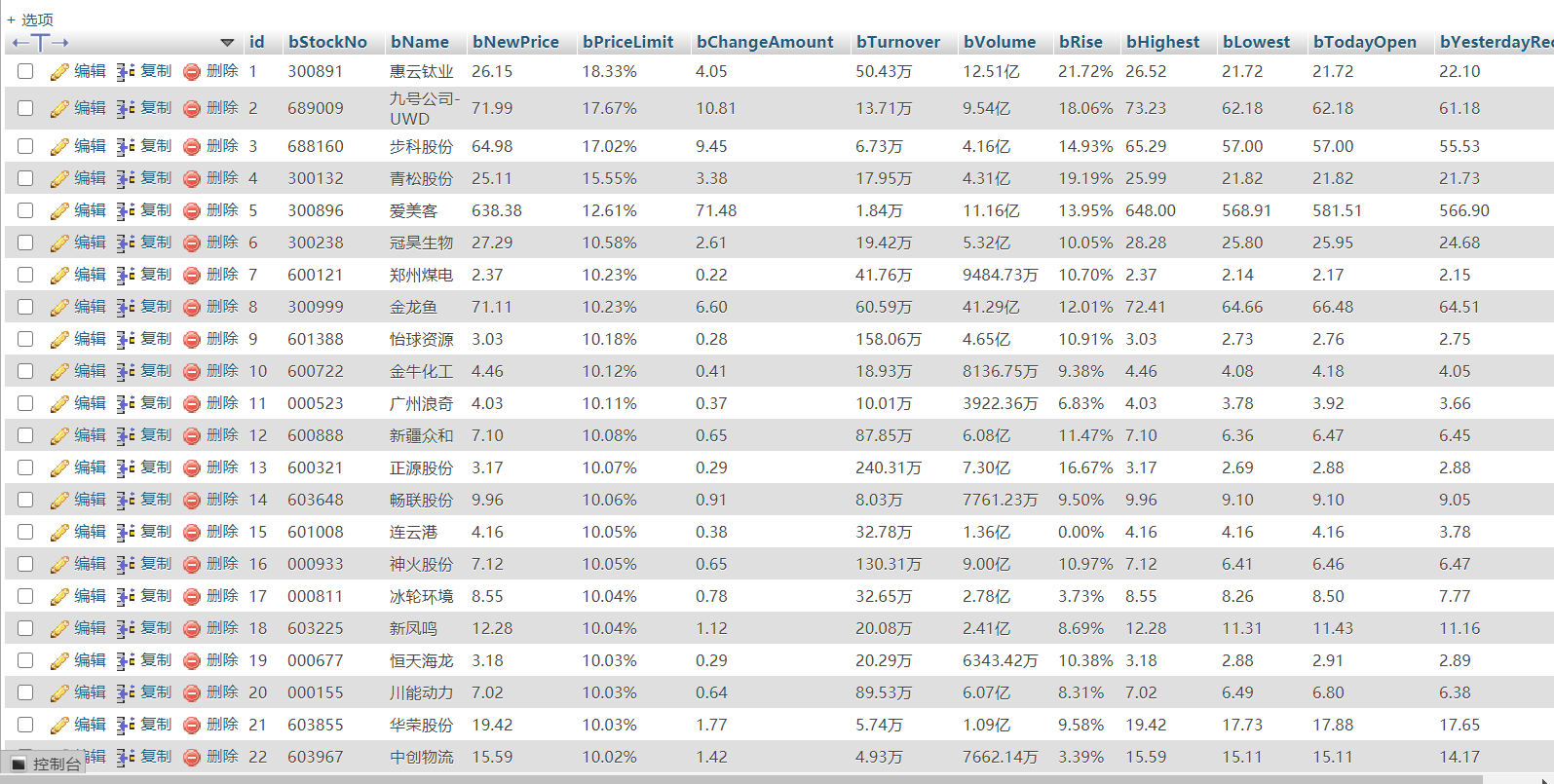
2)、心得体会
本题爬取的内容之前的作业也爬取过,不过之前采取的是提取json格式的数据包来进行处理,而本次是采取selenium框架来模拟浏览器行为从而获取完整的股票信息。较之前的实验不同的思路在对于翻页和翻不同版块的处理上,之前的作业对于翻页处理是通过观察url的参数规律来进行翻页,而本次实验则是模拟鼠标对下一页按钮进行点击,对模块进行点击则实现翻模块处理,相比之前的方法,这一处理更加直观一些。虽然方法很直观,但在做的过程还是遇到了一些错误:
1.首先便是对于翻模块的处理。在运行代码时,找到模块的那一个按钮,然后模拟鼠标进行点击操作,但是一开始运行了好几次发现无法进行跳转模块,将浏览器显示出来观察其运行时,发现模块没有被点击,检查了好几次代码也没有错误,但是是出现了 Element is not clickable at point,Other element would receive the click: 的报错,百度之后貌似是说点击这个button的时候,这个单击事件被上层的其他覆盖在这个button上的标签给接收了,driver.execute_script("arguments[0].click();", btn_div) 按照教程把click改成了这样,但貌似还是没有很好地解决问题。最后对翻模块处理进行单独调试,发现原来的代码并没问题,然后又试了几次,终于成功爬取下来。折腾来折腾去原来的代码并没有问题,但是就不知道为啥会翻不过去。。。。可能是热点的网不太好吧,回到宿舍连上网线就没问题了。
2. (1062, "Duplicate entry '689009' for key 'PRIMARY'") 在数据插入数据库时出现了这样的错误提示,原因是那个主key重复了,爬取第二模块的某些股票在之前的第一个模块就已经爬取过插入到了数据库里了,因此再插入会无法插入,不过这也让数据库里的信息不会产生冗余,因此就没有去解决这个报错。
作业③
1)、使用Selenium框架+MySQL爬取中国mooc网课程资源信息
CourseSpider.py
import datetime
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import pymysql
class Myspider:
def startUp(self, key, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)#
self.driver.get(url)
time.sleep(2) # 找到输入框
input = self.driver.find_element_by_xpath("//div[@class='web-nav-right-part']//div[@class='u-baseinputui']//input")
input.send_keys(key) # 输入关键字
input.send_keys(Keys.ENTER) # 回车
try:
print("opened")
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "", db = "course", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table courses")
except:
pass
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
if self.opened:
self.cursor.execute("create table courses (id varchar(32), cCourse varchar(32) , cCollege varchar(32), cTeacher varchar(32), cTeam varchar(512), cCount varchar(32), cProcess varchar(64), cBrief varchar(1024))")
def closeUp(self):
try:
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, name, college, teacher, team, participants, process, brief):
try:
sql = "insert into courses (id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)values(%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (self.count, name, college, teacher, team, participants, process, brief))
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(3)
# print(self.driver.current_url)
courses = self.driver.find_elements_by_xpath("//div[@class='m-course-list']//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click']")
for course in courses:
name = course.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']//a//span").text
print(name)
college = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='t21 f-fc9']").text
print(college)
teacher = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='f-fc9']").text
print(teacher)
try: # 团队有好几个人
teacher_main = teacher
teacher_team_else = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//span[@class='f-fc9']").text
team = teacher_main + teacher_team_else
except: # 团队只有一个人
team = teacher
print(team)
participants = course.find_element_by_xpath(
".//div[@class='t2 f-fc3 f-nowrp f-f0 margin-top0']//span[@class='hot']").text
print(participants)
course_url = course.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']//a").get_attribute("href")
print(course_url)
time.sleep(2)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver_son = webdriver.Chrome(chrome_options=chrome_options) # 开另一个浏览器来进入另一个链接
driver_son.get(course_url)
time.sleep(2)
process = driver_son.find_element_by_xpath("//div[@class='g-mn1 course-enroll-info-wrapper']//div[@class='course-enroll-info_course-info_term-info_term-time']").text
print(process)
brief = driver_son.find_element_by_xpath("//div[@class='m-infomation_content-section']//div[@class='course-heading-intro_intro']").text
print(brief)
driver_son.quit()
time.sleep(2)
self.count += 1
self.insertDB(name, college, teacher, team, participants, process, brief)
# 取下一页的数据,直到最后一页
try:
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-disable-gh']") # 此时已经到达最后一页
except:
nextPage = self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']")
nextPage.click()
time.sleep(2)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, key, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(key, url)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = Myspider()
while True:
print("1.爬取慕课网站信息")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
key = input("请输入要搜索的课程关键词")
spider.executeSpider(key, url)
continue
elif s == "2":
break

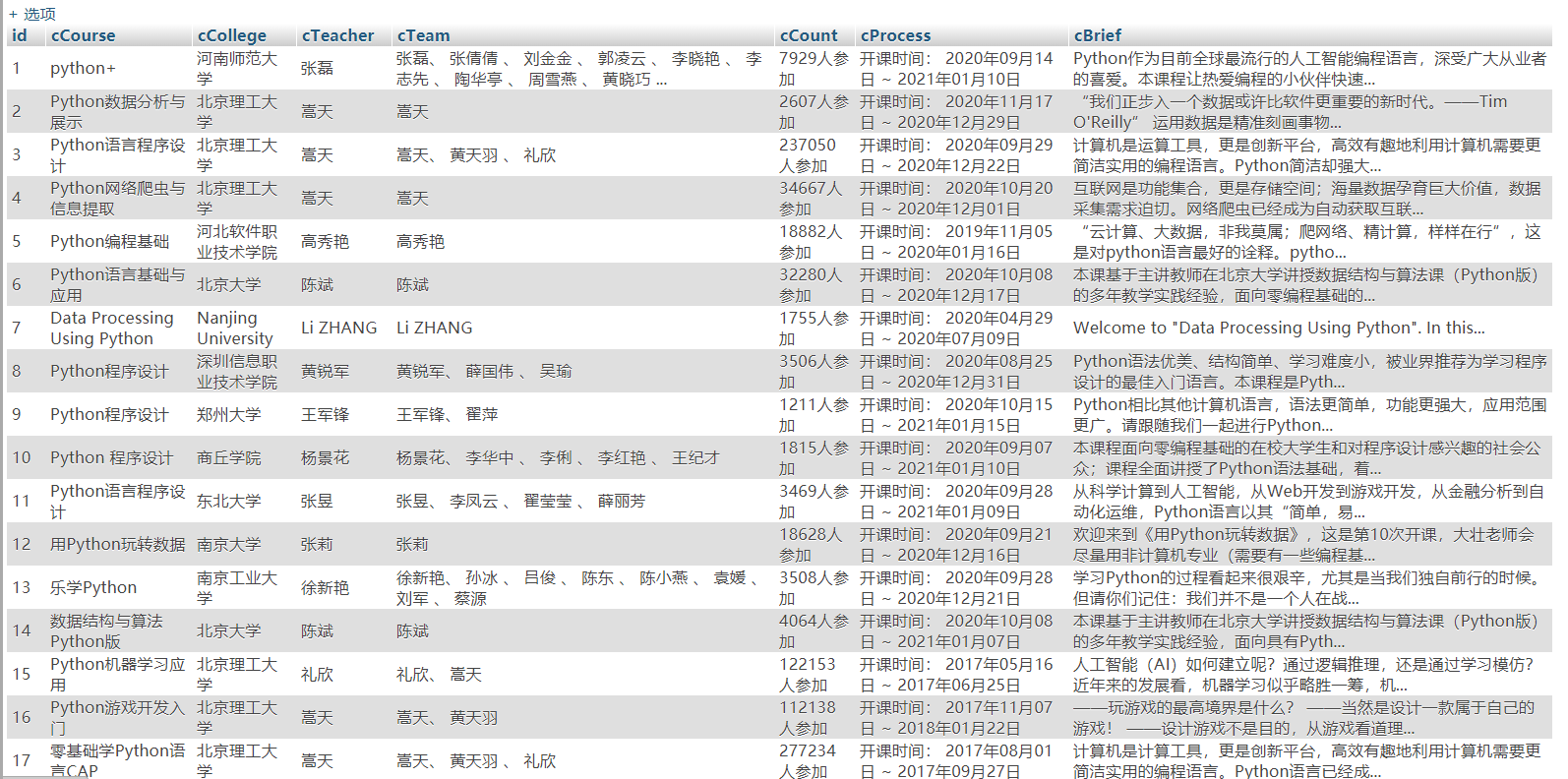
2)、心得体会
本次作业要求对于慕课上的课程信息资源进行爬取,没有什么新的东西,基本就是对于selenium框架使用的巩固,编写本题时没有出现太多的障碍,就是爬虫程序一如既往的玄学,同样的代码第一次不行出错,第二次就可以了,很莫名其妙。 不过题目里要求实现用户模拟登录,但是貌似不需要登录就能直接爬取下来,因此就没有去进行登录操作。
Message: no such element: Unable to locate element: {"method":"xpath","selector":".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='t21 f-fc9']"}
(Session info: headless chrome=86.0.4240.198)
在进行连续爬取网页时,有时候爬取到一半就出现这样的报错然后停止,也不知道是什么原因。。。。根据错误提示的意思大概是找不到这个元素,但是之前的连续爬取都是没有问题的,排除了代码问题,我也找不到很好的解决办法。
三个作业做下来,感觉爬虫总是不太稳定,一样的代码有时候成功有时候找不到元素,很迷惑。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号