第四次作业
作业①
1)、Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
Myspider.py
import scrapy
from dangdang.items import DangdangItem
from bs4 import UnicodeDammit
class MyspiderSpider(scrapy.Spider):
name = 'Myspider'
key = 'java'
source_url='http://search.dangdang.com/'
def start_requests(self):
url = MyspiderSpider.source_url + "?key=" + MyspiderSpider.key
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = DangdangItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
pipelines.py
import pymysql
class DangdangPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "******", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
settings.py
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}

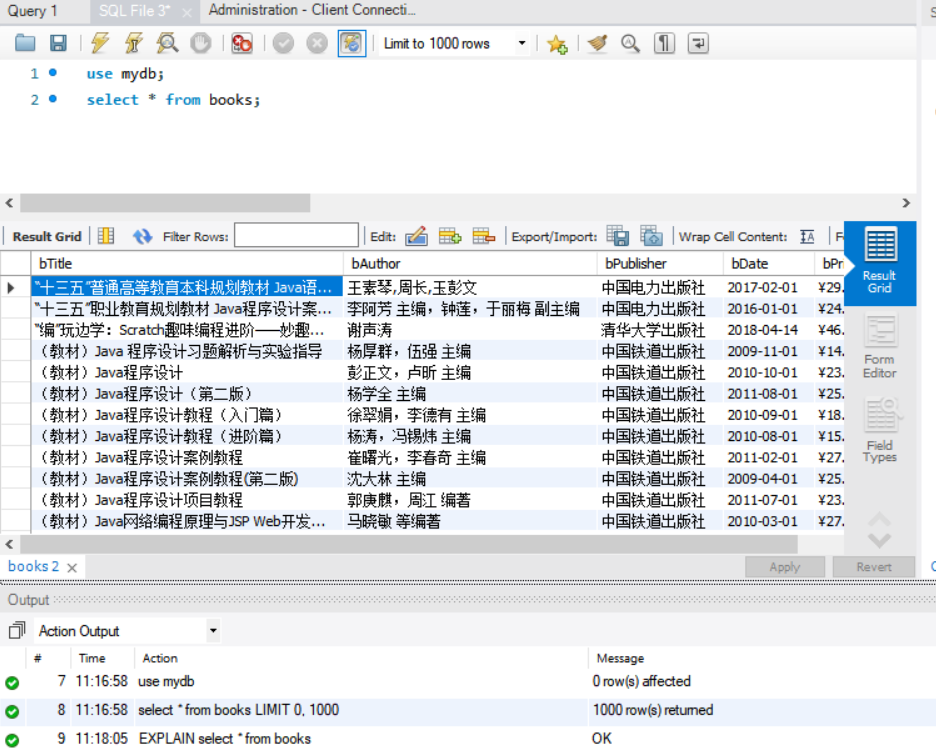
2)、心得体会
本次实验主要是对课本上代码的复现,通过使用Scrapy框架来对当当网的图书信息进行爬取。本次实验相较之前实验的不同之处是多使用了数据库技术来存储数据,而这更靠近日常生产中的使用要求。因为往往我们在网上爬取一些信息后,希望的是将其存储起来,而不是在需要的时候又去爬取一遍信息打印出来进行查看。因此这种情况下使用数据库技术就非常合适,我们将爬取下来的信息存储到数据库中,需要时只要输入几句查询语句就能对爬取的信息进行查询。本次实验让我很好地学习了如何将爬取的信息存取到数据库中,也让我对于数据库的使用更加熟悉了。
更新:在周六进行了数据库课程的实验后,下载了老师给的Wampserver软件,然后再重新打开之前下载的MySQL时打不开了。。。。经过网上搜索了资料才知道是下了两个MySQL造成了端口的冲突。。。然后打算又重新爬一遍,出现了数据表编码的问题,于是改了好久的本不该出现的莫名其妙的数据库出现的bug。。。bug改得心好累T.T
作业②
1)、Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
MySpider.py
import json
from stock.items import StockItem
import scrapy
class MySpider(scrapy.Spider):
name = 'stocks'
page = 1
start_urls = [
'http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240821834413285744_1602921989373&pn=' + str
(page) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,'
'm:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,'
'f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602921989374']
def parse(self, response):
try:
data = response.body.decode('utf-8')
data = data[41:-2] # 将获取到的json文件字符串去掉前面的jQuery.....一大串东西,截取为标准的json格式,传入处理
responseJson = json.loads(data)
stocks = responseJson.get('data').get('diff')
for stock in stocks:
item = StockItem()
item['code'] = stock.get('f12')
item['name'] = stock.get('f14')
item['new_price'] = stock.get('f2')
item['price_limit'] = stock.get('f3')
item['change_amount'] = stock.get('f4')
item['turnover'] = stock.get('f5')
item['volume'] = stock.get('f6')
item['rise'] = stock.get('f7')
item['highest'] = stock.get('f15')
item['lowest'] = stock.get('f16')
item['today_open'] = stock.get('f17')
item['yesterday_receive'] = stock.get('f18')
yield item
url = response.url.replace("pn=" + str(self.page), "pn=" + str(self.page + 1)) # 实现翻页
self.page = self.page + 1
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
pipelines.py
import pymysql
class StockPipeline:
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "", db = "stock", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条股票信息")
def process_item(self, item, spider):
try:
self.count = self.count + 1
print("{:^2}{:>10}{:>10}{:>10}{:>10}{:>12}{:>13}{:>15}{:>12}{:>12}{:>12}{:>12}{:>12}".format(self.count, item['code'], item['name'],
item['new_price'], item['price_limit'],
item['change_amount'],
item['turnover'],
item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
if self.opened:
self.cursor.execute("insert into stocks (id,bStockNo,bName,bNewPrice,bPriceLimit,bChangeAmount,bTurnover,bVolume,bRise,bHighest,bLowest,bTodayOpen,bYesterdayReceive)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(self.count, item['code'], item['name'],item['new_price'], item['price_limit'],item['change_amount'],item['turnover'],item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
except Exception as err:
print(err)
return item
items.py
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
price_limit = scrapy.Field()
change_amount = scrapy.Field()
turnover = scrapy.Field()
volume = scrapy.Field()
rise = scrapy.Field()
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
today_open = scrapy.Field() # 今开
yesterday_receive = scrapy.Field() # 昨收
pass
settings.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'stock.pipelines.StockPipeline': 300,
}
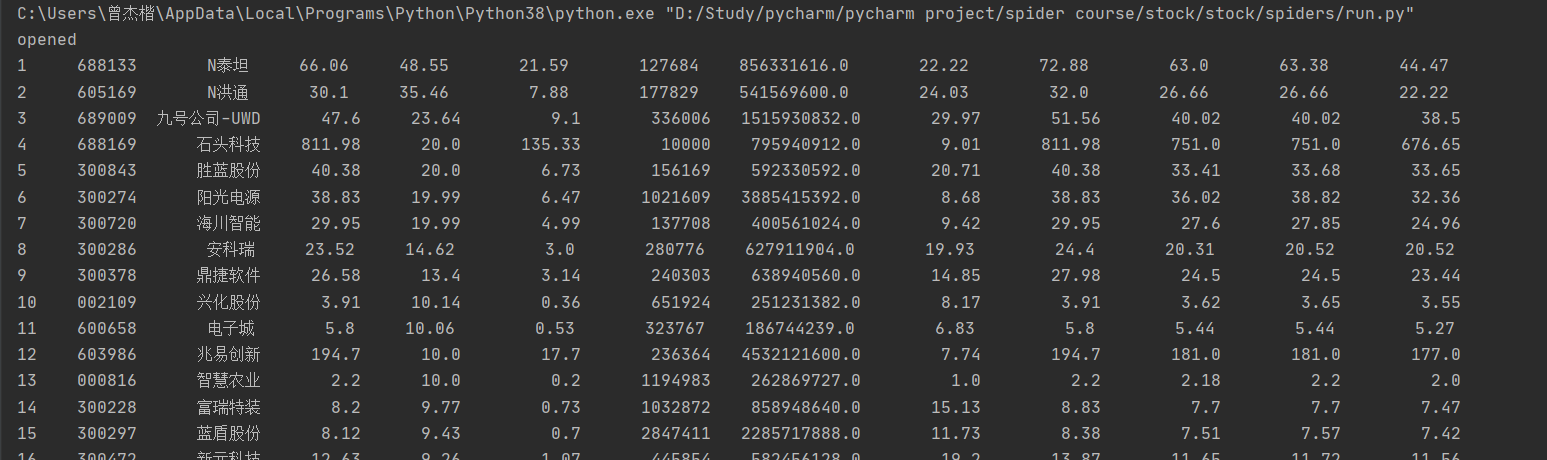
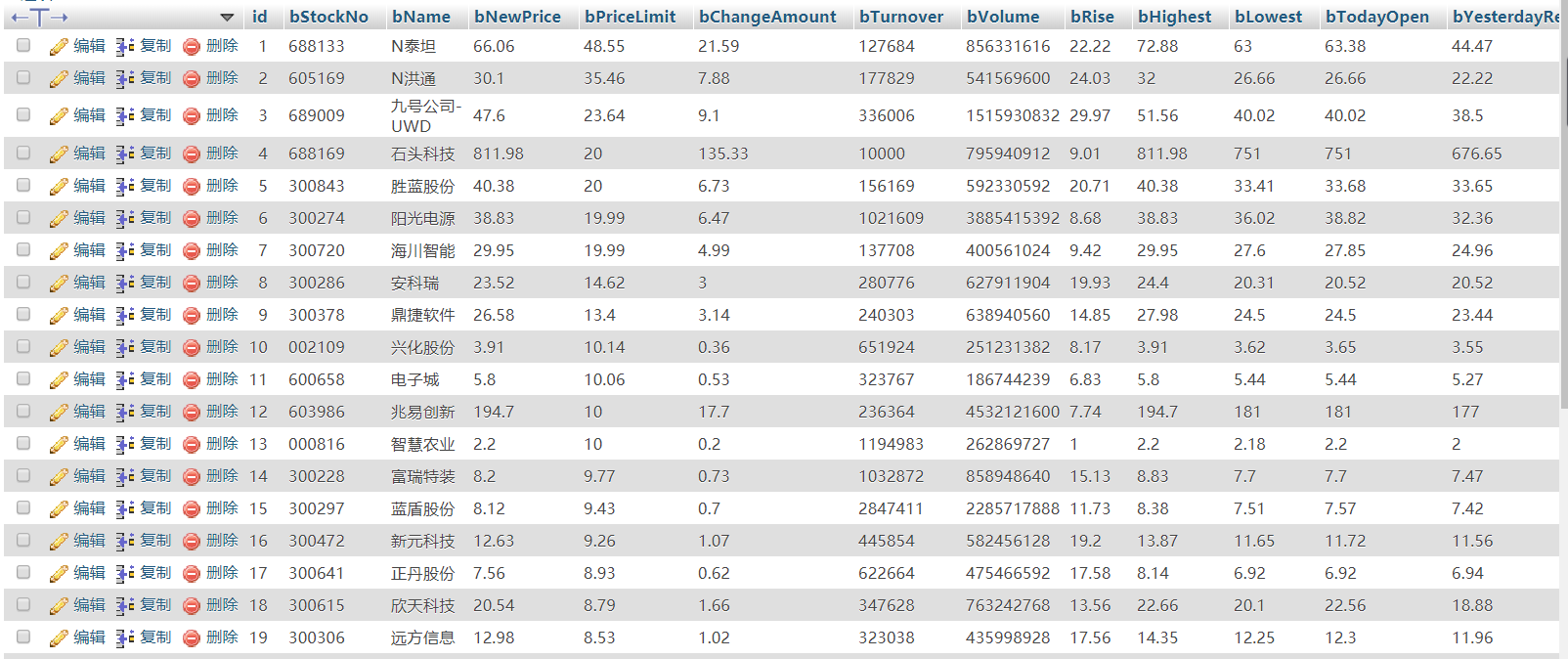
2)、心得体会
本次作业的内容是上次股票爬取的升级版,其实就是比上次多了个要求——使用数据库来存储爬取的信息。Myspider的内容基本不变,主要是要对pipelines的内容进行编写,实现与数据库的对接。因为采用的是通过抓取json格式的数据包来获取数据,因此没有使用xpath来获取数据。代码上的编写基本是没有太大的问题,问题基本是出现在对于数据库的相关操作上。比如,一开始我对于表是这样定义的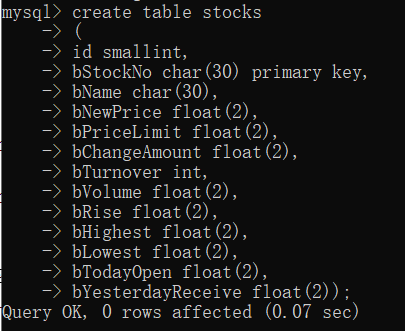 ,看起来似乎是没有问题的,但是当我开始爬取股票信息时,由于有些股票行的某些列是空的即显示'-',这时就会出现这样的报错 (1265, "Data truncated for column 'bNewPrice' at row 1") ,即将'-'插入float类型,此时便会出现错误导致此行信息插入数据库失败。因此表的定义需要改成
,看起来似乎是没有问题的,但是当我开始爬取股票信息时,由于有些股票行的某些列是空的即显示'-',这时就会出现这样的报错 (1265, "Data truncated for column 'bNewPrice' at row 1") ,即将'-'插入float类型,此时便会出现错误导致此行信息插入数据库失败。因此表的定义需要改成 ,这时无论该列有没有数据,都能成功插入该行数据。
,这时无论该列有没有数据,都能成功插入该行数据。
(PS.小声bb,调这些bug时我一度以为我在做的是数据库的作业而不是爬虫课作业=.=)
作业③
1)、使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
change.py
import scrapy
from bs4 import UnicodeDammit
from money.items import MoneyItem
class ChangeSpider(scrapy.Spider):
name = 'change'
def start_requests(self):
url = 'http://fx.cmbchina.com/hq/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
money = selector.xpath("//div[@id ='realRateInfo']//tr")
for moneyitem in money[1:]: # 处理表头
currency = moneyitem.xpath("./td[@class='fontbold']/text()").extract_first()
TSP = moneyitem.xpath("./td[@class='numberright'][position()=1]/text()").extract_first()
CSP = moneyitem.xpath("./td[@class='numberright'][position()=2]/text()").extract_first()
TBP = moneyitem.xpath("./td[@class='numberright'][position()=3]/text()").extract_first()
CBP = moneyitem.xpath("./td[@class='numberright'][position()=4]/text()").extract_first()
Time = moneyitem.xpath("./td[@align='center'][position()=3]/text()").extract_first()
item = MoneyItem()
item["currency"] = currency.strip() if currency else "" # 处理空标签
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
pipelines.py
import pymysql
class MoneyPipeline(object):
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "", db = "money", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from changes")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
print("序号\t", "交易币\t", "现汇卖出价\t", "现钞卖出价\t ", "现汇买入价\t ", "现钞买入价\t", "时间\t")
try:
self.count = self.count + 1
print("{:^2}{:^10}{:>10}{:>10}{:>10}{:>12}{:>13}".format(self.count,item["currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
if self.opened:
self.cursor.execute("insert into changes(bId,bCurrency,bTSP,bCSP,bTBP,bCBP,bTime)values(%s,%s,%s,%s,%s,%s,%s)",(self.count,item["currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
except Exception as err:
print(err)
return item
items.py
import scrapy
class MoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
settings.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'money.pipelines.MoneyPipeline': 300,
}

2)、心得体会
本次实验是对scrapy框架+Xpath+MySQL使用的巩固练习,爬取的是静态网页,不像上一个作业那么多花里胡哨的,直接朴实无华地根据网页源代码对标签进行解读从而进行爬取就行了,就是注意一些细节,比如注意处理空标签,注意处理表头。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号