第三次作业
作业①
1)、爬取网站所有图片实验
单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count = count + 1
# 提取文件后缀扩展名
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
imageSpider(start_url)

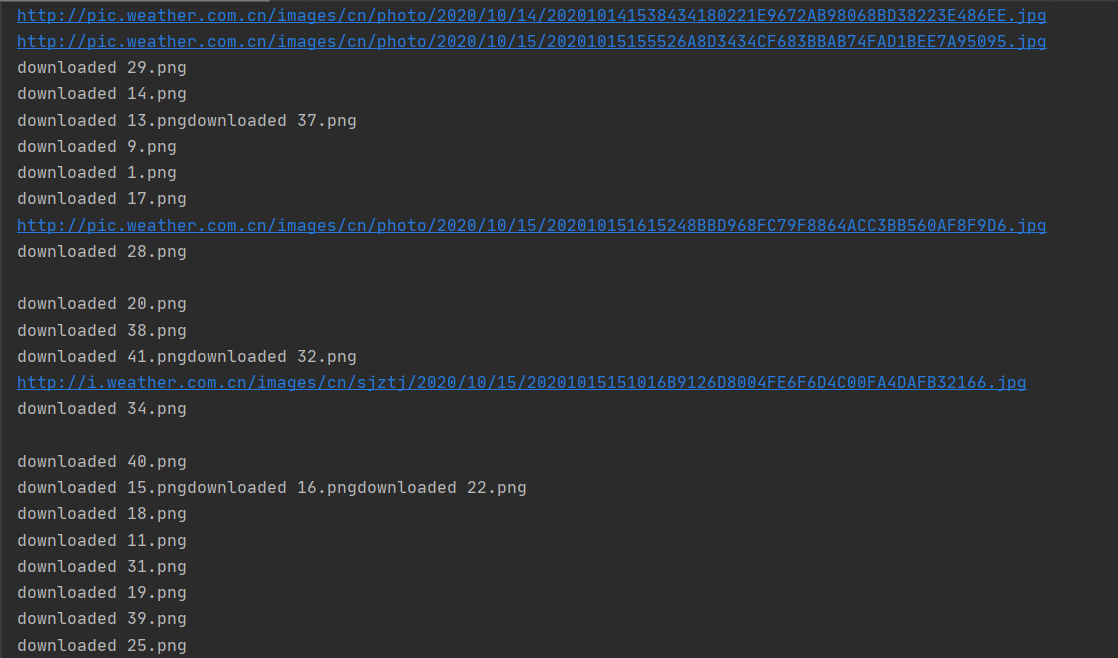
多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count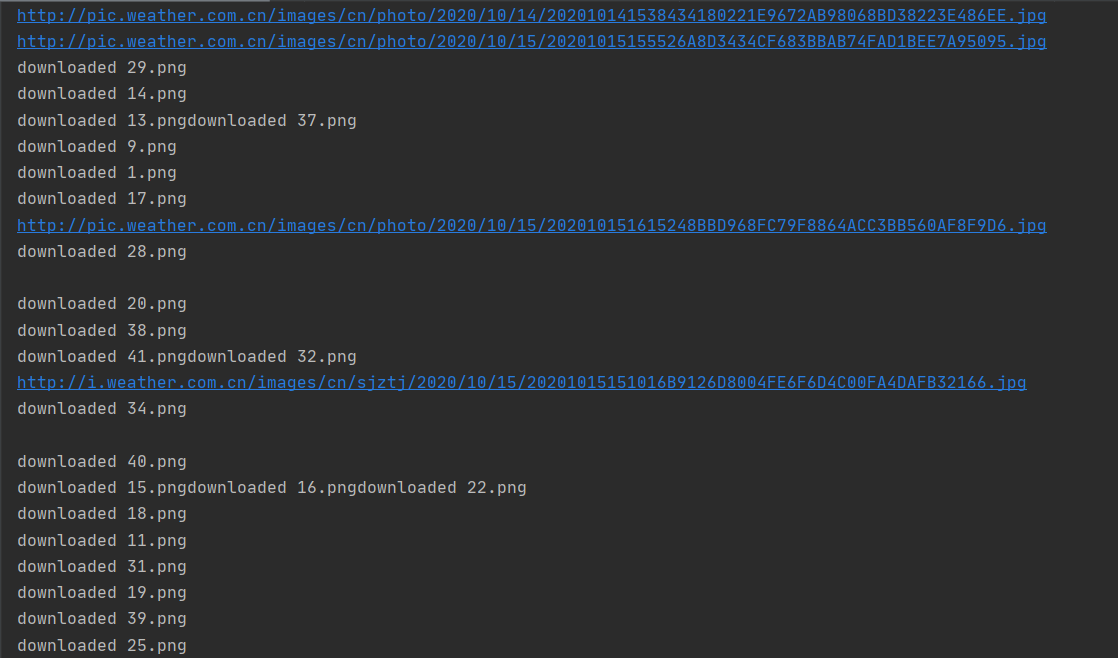
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
2)、心得体会
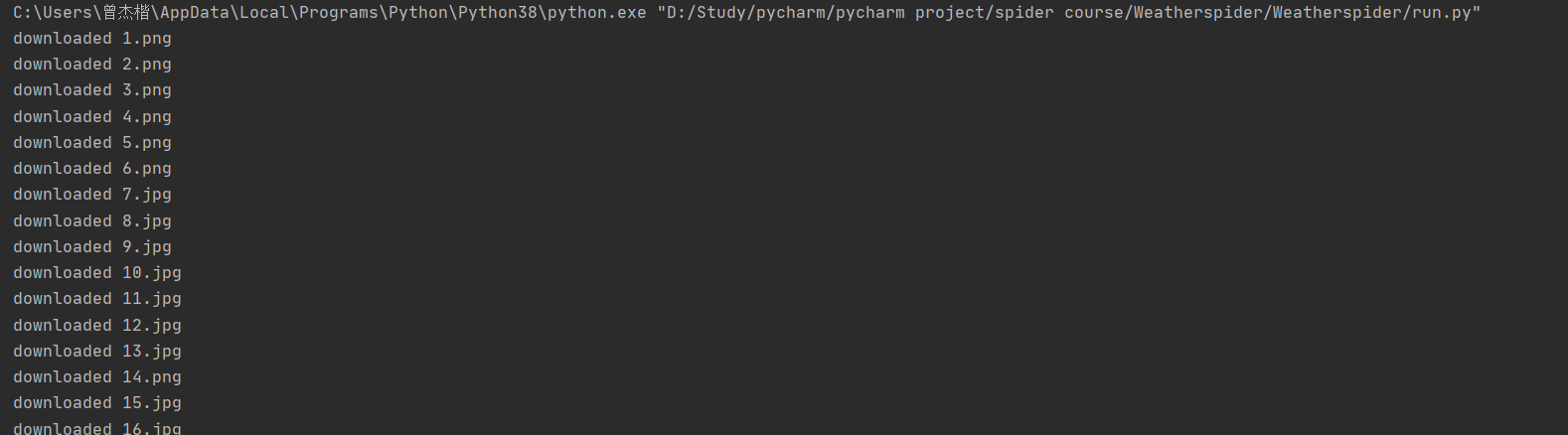
这一实验主要是对课本上的代码的复现,通过此次实验,我更好地体会到单线程和多线程的区别。从实验的结果可以明显地看出,单线程下载图片是一张一张按顺序下载的,而多线程下载图片并不是按照顺序来的,而且多线程下载的速度会稍微快一些。
作业②
1)、使用scrapy框架复现上一个实验
jpgspider.py
import scrapy
from Weatherspider.items import WeatherspiderItem
class JpgspiderSpider(scrapy.Spider):
name = 'jpgspider'
allowed_domains = ['weather.com']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data = response.body.decode()
selector = scrapy.Selector(text=data)
images = selector.xpath("//img")
for image in images:
try:
item = WeatherspiderItem()
item["picture"] = image.xpath("./@src").extract_first()
yield item
except Exception as err:
print(err)
pipelines.py
import urllib.request
class WeatherspiderPipeline:
count = 0
def process_item(self, item, spider):
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
try:
self.count = self.count + 1
url = item['picture']
# 提取文件后缀扩展名
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(self.count) + ext)
except Exception as err:
print(err)
return item
items.py
import scrapy
class WeatherspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
picture = scrapy.Field()
pass
settings.py
ITEM_PIPELINES = {
'Weatherspider.pipelines.WeatherspiderPipeline': 300,
}
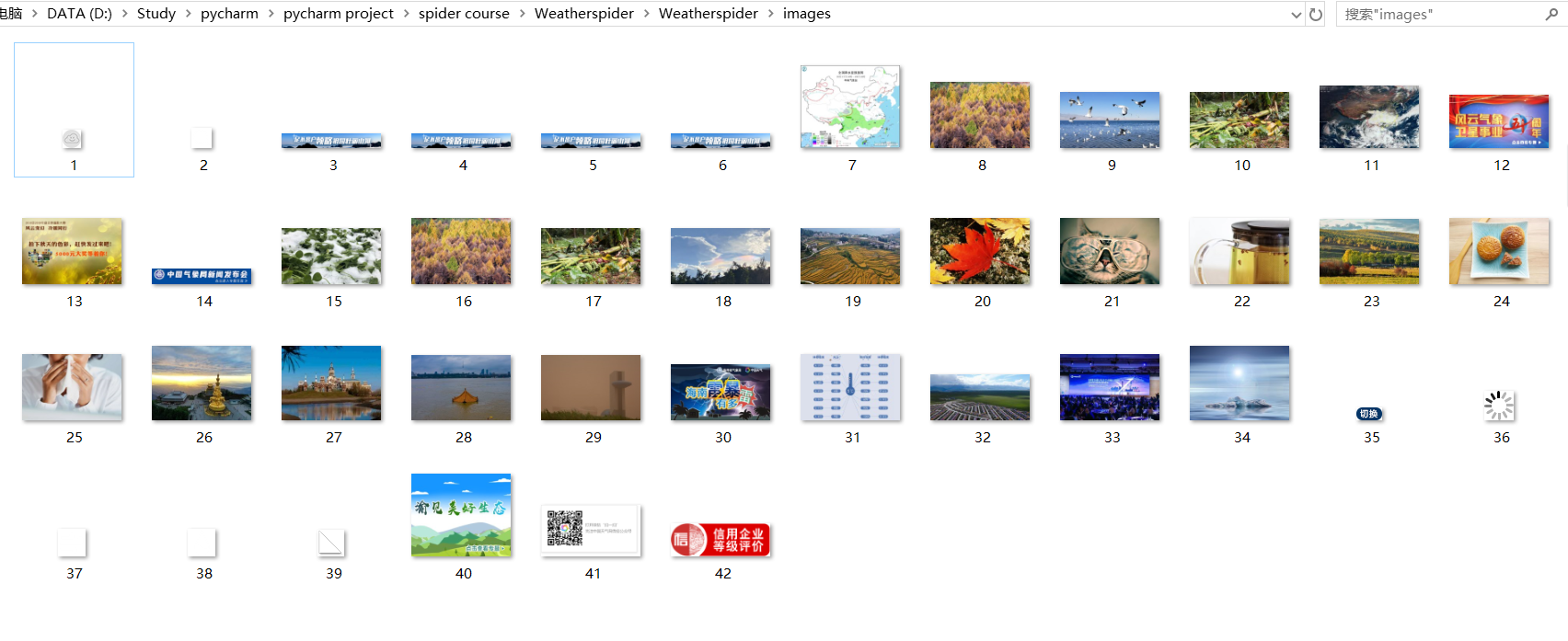
2)、心得体会
这一实验主要是对上一个实验使用scrapy框架进行复现。上一个实验主要是通过request和beautifulsoup等方法来实现爬虫的,通过这次的实验,锻炼了我使用scrapy框架的能力,对scrapy框架各部分的功能更加理解了,学习到了爬虫的另一种思路,并熟悉了xpath的使用方法。
作业③
1)、使用scrapy框架爬取股票信息实验
stocks.py
import json
import urllib
from stockspider.items import StockspiderItem
import scrapy
class StocksSpider(scrapy.Spider):
name = 'stocks'
page = 1
start_urls = [
'http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240821834413285744_1602921989373&pn=' + str
(page) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,'
'm:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,'
'f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602921989374']
def parse(self, response):
try:
data = response.body.decode('utf-8')
data = data[41:-2] # 将获取到的json文件字符串去掉前面的jQuery.....一大串东西,截取为标准的json格式,传入处理
responseJson = json.loads(data)
stocks = responseJson.get('data').get('diff')
for stock in stocks:
item = StockspiderItem()
item['code'] = stock.get('f12')
item['name'] = stock.get('f14')
item['new_price'] = stock.get('f2')
item['price_limit'] = stock.get('f3')
item['change_amount'] = stock.get('f4')
item['turnover'] = stock.get('f5')
item['volume'] = stock.get('f6')
item['rise'] = stock.get('f7')
yield item
url = response.url.replace("pn=" + str(self.page), "pn=" + str(self.page + 1)) # 实现翻页
self.page = self.page + 1
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
pipelines.py
class StockspiderPipeline:
count = 0
print("{:^2}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:>10}".format("序号", "代码", "名称", "最新价", "涨跌幅", "跌涨额", "成交量","成交额", "涨幅"))
def process_item(self, item, spider):
try:
self.count = self.count + 1
print("{:^2}{:>10}{:>10}{:>10}{:>10}{:>12}{:>13}{:>15}{:>12}".format(self.count, item['code'], item['name'],
item['new_price'], item['price_limit'],
item['change_amount'], item['turnover'],
item['volume'], item['rise']))
except Exception as err:
print(err)
return item
items.py
import scrapy
class StockspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
price_limit = scrapy.Field()
change_amount = scrapy.Field()
turnover = scrapy.Field()
volume = scrapy.Field()
rise = scrapy.Field()
pass
settings.py相关配置
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
#'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
#'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Host': '41.push2.eastmoney.com',
'Connection': 'keep-alive',
'Accept': '*/*',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'qgqp_b_id=b12cd1da193f892cee63c6eb376e704e; intellpositionL=1215.35px; intellpositionT=4102.2px; em_hq_fls=js; waptgshowtime=20201014; st_si=99061805158124; st_asi=delete; st_pvi=38642806579130; st_sp=2020-09-30%2009%3A43%3A24; st_inirUrl=https%3A%2F%2Fwww.eastmoney.com%2F; st_sn=5; st_psi=20201014092424930-113200301321-6300356575'
}
ITEM_PIPELINES = {
'stockspider.pipelines.StockspiderPipeline': 300,
}
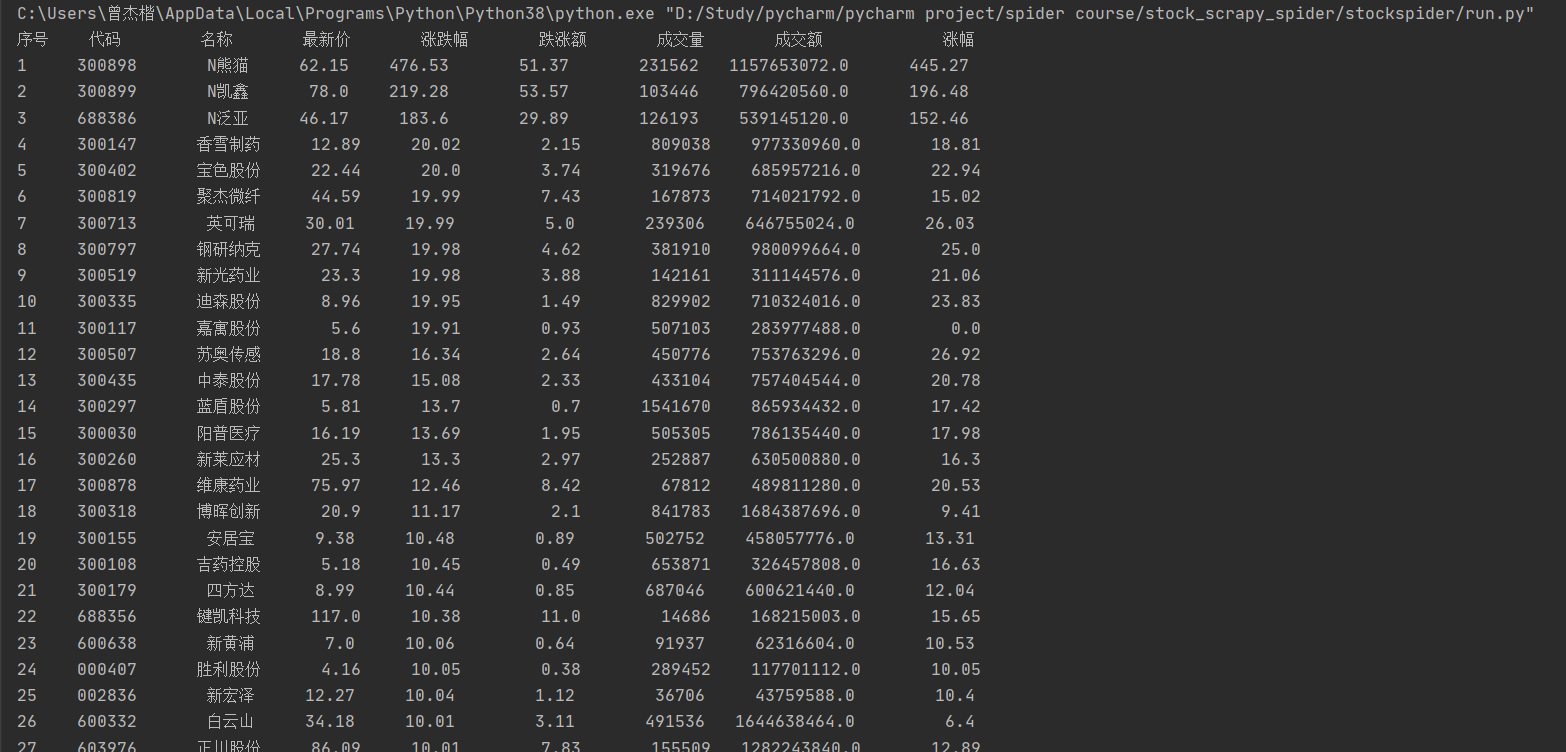
2)、心得体会
本次实验是使用scrapy框架来对上次股票信息爬取实验的代码进行修改,针对scrapy框架的特点来修改代码,在这个过程中让我很好地对比了使用scrapy框架和使用request和beautifulsoup方法来爬虫的区别,加深了对了scrapy框架的理解。同时,对于有保护机制的网站,记得在settings.py的配置里的ROBOTSTXT_OBEY 改成False,否则会被反爬。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号