摘要:
# 1. Some Nitations 在本小节开始之前,需要知道的符号含义. 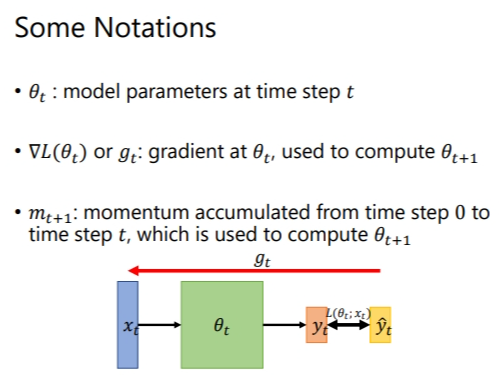 # 2. What is 阅读全文
摘要:
# 1. When gradient is small 本小节主要讨论优化器造成的训练问题. ## 1.1 Critical Point(临界点) 如果训练过程中经过很多个epoch后,loss还是不下降,那么可能是因为梯度(斜率)接近于 0,导致参数更新的步伐接近于0,所以参数无法进一步更新,lo 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号