10. 数据下载
1. 引入
当我们想比对测序数据与参考基因组时,先下载好参考基因组的数据,接下来就是准备测序数据.那么问题来了,测序数据是如何准备呢?
2. database
我们打开一篇论文,通常我们可以在论文尾部发现数据下载处.论文尾部会介绍数据上传位置或者数据出处.下图就是上传至GEO数据库中.
GEO数据库全称Gene Expression Omnibus database,是由美国国立生物技术信息中心NCBI创建并维护的基因表达数据库。 它创建于2000年,收录了世界各国研究机构提交的高通量基因表达数据.也就是说只要是目前已经发表的论文,论文中涉及到的基因表达检测的数据都可以通过这个数据库中找到.

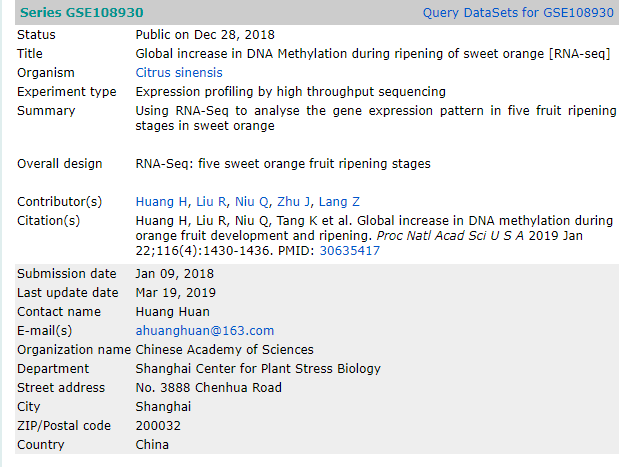
在NCBI的GEO数据库中搜索GSE108930,可以得到如下所示的页面.这是作者上传的甜橙RNA-seq数据,标题其实是论文名,也就是甜橙成熟期间DNA甲基化的全局增长.
在下面的Platforms可以看到作者使用什么测序工具:

\(Samples\)表示作者使用了多少样本,我们查阅可知是15个样本(作者测了甜橙5个时期,每个时期3个样本).GSM实际上是作者的样本编号.
下图的BioProject是项目编号,SRA是测序数据原始的编号.这里实际是存储在SRA数据库的编号.
SRA(Sequence ReadArchive)数据库是用于存储二代测序的原始数据,包括 454,Illumina,SOLiD,IonTorrent,Helicos 和 CompleteGenomics.除了原始序列数据外,SRA现在也存在raw reads在参考基因的比对信息.

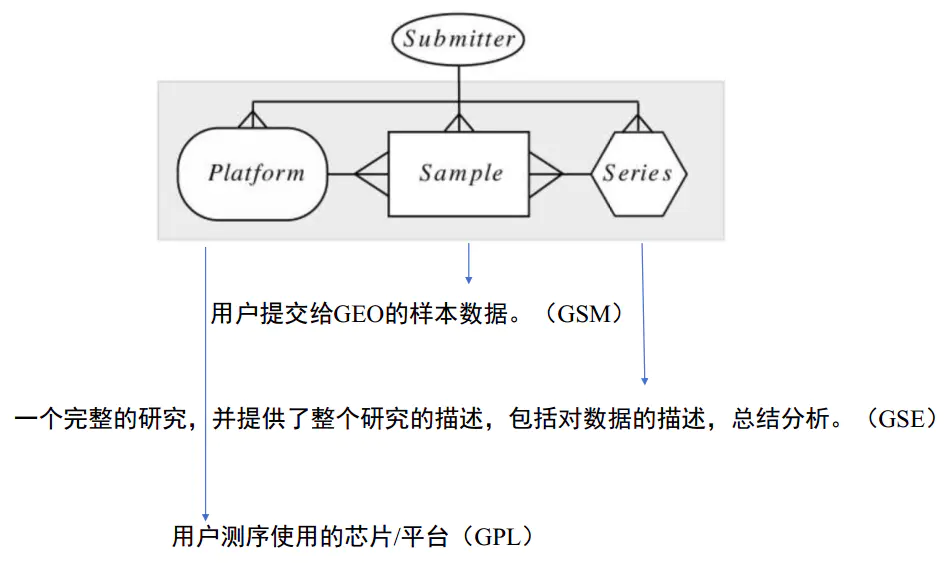
那么我们在前面的GSE的编号到底是什么呢?关于GEO数据库,我们只需要知道这三个概念就好:
- GEO Platform (GPL)
- GEO Sample (GSM)
- GEO Series (GSE)
在进行参考基因组比对时,我们要下载的数据是原始数据.因此要到\(SRA\)数据库中下载,通过左上角一次性全部下载.
进入后看见如下页面.\(Run\)可以理解为数据序号,\(BioSample\)是数据对应的样本编号,\(Base\)是测序的碱基数量.\(Byte\)是文件大小.\(Developmental\_Stage\)是样本描述.

找到了数据下载地址,接下来是下载数据.我们总共介绍三种方法.
3. How to download data from public database
3.1 prefetch
这个方法是\(NCBI\)官方提高的方法,它主要来源于NCBI的官方软件包sra‑tookit,也就是说\(prefetch\)是sra‑tookit的工具之一.但是请注意在\(conda\)的安装仓库中,这个软件的名字被改成了\(sra-tools\).
安装完成后,使用\(RUN\)的ID进行安装.
prefetch SRR6451531
这个方法用的不多,因为国内下载速度比较慢.
3.2 sra-explorer
\(sra-explorer\)是一个用于搜索\(sra\)数据的网页.它支持输入:GSE、SRA、SRP、PRJ(项目编号)、ERP,甚至直接通过物种+组织+测序技术搜索.
这里我们干脆整理一下\(sra\)数据库的编号意义.
SRA 数据库的组织架构
1,meta 数据是指与测序实验及其实验样品相关的数据, 如实验目的、 实验设计、 测序平台、 样本数据(物种, 菌株,个体表型等),在SRA数据库中,meta数据分如下层次来存储:
(1)研究课题(study). 在 SRA 数据库中, 研究课题的检索号(accession number)以前缀 DRP, ERP 或SRP 开头。
(2)样本信息(sample). 样本的检索号以前缀 DRS, ERS 或 SRS开头。 样本信息可以包括物种信息、 菌株(品系)信息、 家系信息、 表型数据、 临床数据, 组织类型等。
(3)实验信息(experiment). 实验的检索号以前缀DRX, ERX 或 SRX 开头。 实验是 SRA 数据库的最基本单元, 就像 PubMed 数据库的每一篇文献是 PubMed数据库的基本单元一样。 一个实验隶属于某个研究课题, 对一个或多个样本进行测序, 产生的测序数据以 runs 的形式存储于 SRA .
2,序列数据
包括序列及其质量信息等, 在 SRA 数据库中以run 为单元存储。 run 的检索号以前缀 DRR, ERR 或SRR 开头。
3。SRA 数据库中的测序数据来自四个测序平台
分别为: Roche_LS454,Illumina,ABI_SOLID和HELICOS。
我们把要下载的数据放在购物车后,页面显示如下.
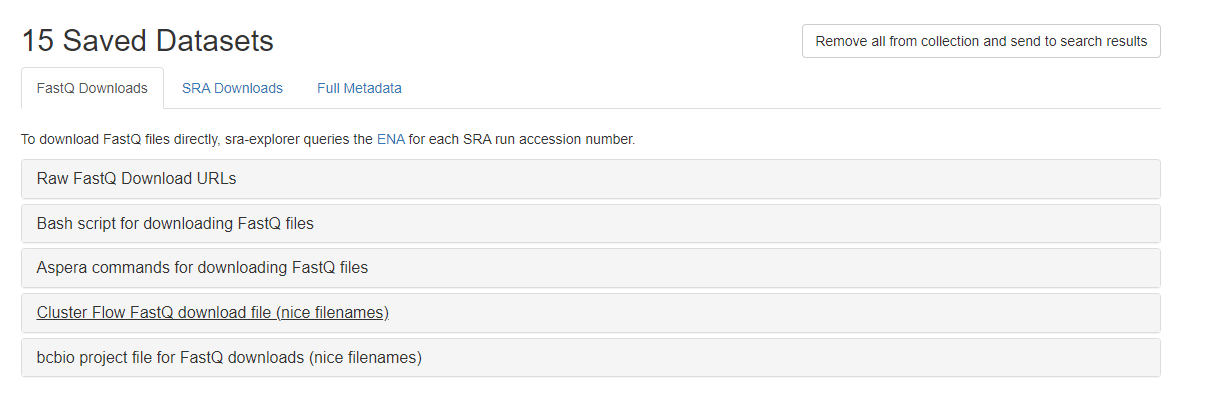
我们可以直接\(wget\)下载.一般情况是可以下载的,也不排除国内网络连不上的情况.
wget ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR645/001/SRR6451531/SRR6451531_1.fastq.gz
上图还有批量命令下载,写个脚本直接复制进去即可.
3.3 kingfisher
我们直接去官网查询.直接使用conda下载.下载后可以使用\(-h\)查看帮助.
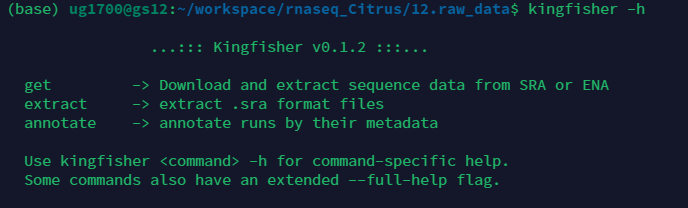
查阅文档可知-r后跟下载数据的编号,-m后跟下载数据的方法,备用方法用空格分割.
kingfisher -r SRR6451531 -m aws-http ena-ftp prefetch
这样下载数据是特别慢的,我们会将它放在后台运行.也可以使用htop -u 用户名来看具体进程运行情况.
nohup kingfisher get -r SRR6451531 -m aws-http ena-ftp prefetch &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号