
LHY2022-HW04-Speaker Identification
1. 实验
1.1 背景介绍
根据输入音频判断是哪个讲话者.
1.2 数据集
数据集采用的是\(VoxCeleb2\).可以看这个Click了解数据集.

1.2.1 Data formats
目录下有三个json文件和很多pt文件,三个json文件作用标注在下图中,pt文件就是语音内容.其中,n_mels表示The demission of mel-spectrogram(特征数是40).想了解各个文件,可以看这个Click

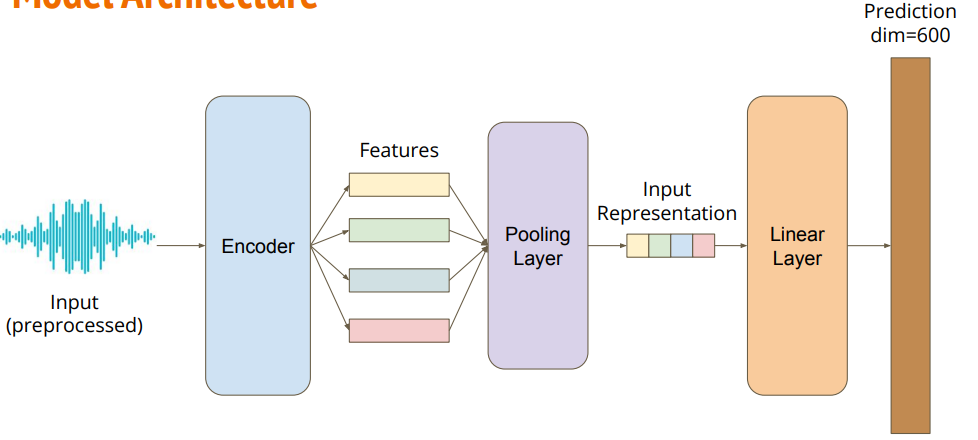
1.3 Model Architecture
模型结构如下图所示,输入最后变成一个600维的向量.
1.3 Hint
对于如何达到4条基本线,助教已经给予了提示.

1.3.1 Requirements - Simple
对于\(Simple\)线,直接输入助教代码即可.

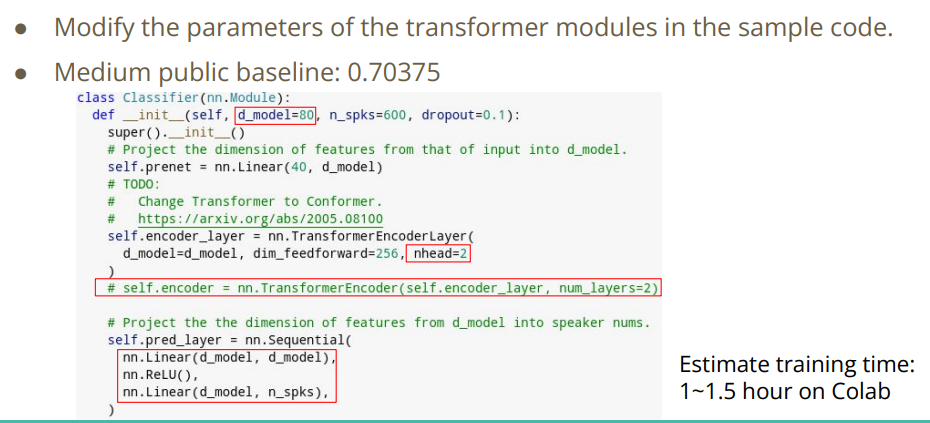
1.3.2 Requirements - Medium
当要达到Medium线时,需要调参.
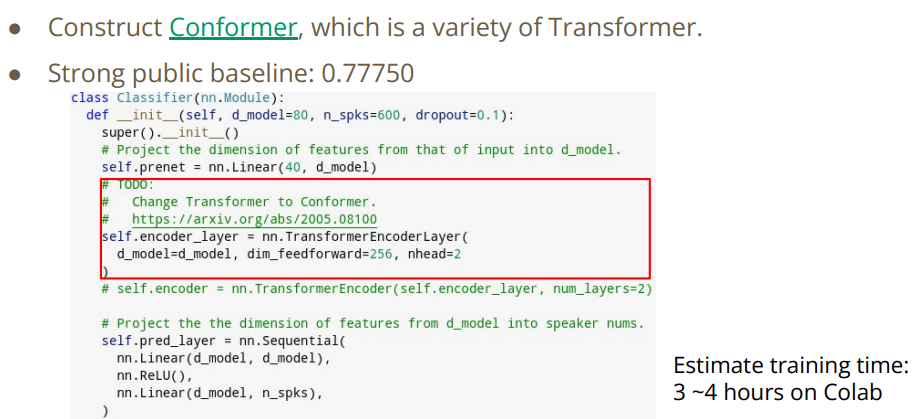
1.3.3 Requirements - Strong
改变模型结构,将Medium转为Strong.
1.3.4 Requirements - Boss

1.4 Submission Format
提交的文件格式如下.

2. 实验过程
2.1 Simple Baseline
- acc > 0.60824
(1) 直接交助教代码
甚至过不了\(simple\)线.
![image]()
2.2 Medium Baseline
- acc > 0.70375
助教提示修改模型参数.
(1) 尝试将dmodel调整到160,nhead调整到8,dim_feedforward改为256
但还是没过\(Medium\)线.
![image]()
(2) 尝试将dim_feedforward改为1024
测试集的准确率反而降低.
![image]()
(3) 将dim_feedforward改为512,然后构造encoder,包含两个encoder_layer
![image]()
(4) 将total_steps=100000,encoder改为3层.
擦线过.
![image]()




2.3 Strong Baseline
(1) 将transformer 改为 Conformer
这里的Conformer是调包.其余不变.Conformer的结点Block结构如下所示:

而Conformer完整结构如下所示
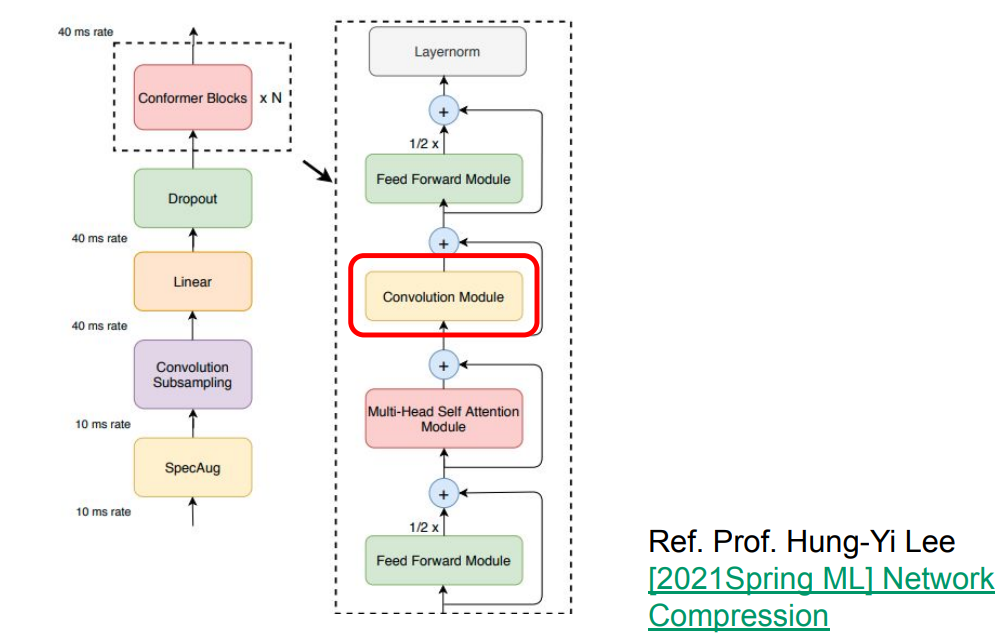
这里解释一下下采样,这里刚好可以使用卷积或者池化实现.

结果:

添加了conformer效果反而下降,因此考虑引入助教的其他提示.
(2) 添加Self-Attention Pooling
单单添加这个效果不好,参考Click调了参.
实验结果如下:

(3) amsoftmax
按道理是加入这个作为新的损失函数,但我实在是无法理解为什么这么写,暂时搁置.
3. 结论与心得
3.1 关于tqdm
在长时间的程序运行中,检查程序的运行情况的函数.
(1) 基于迭代对象运行
这是tqdm的基本用法
下面是给进度条前缀描述.
也可以使用tqdm函数返回迭代器,然后再添加前缀描述.
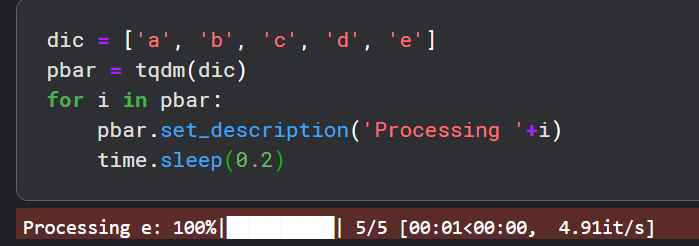
(2) 手动运行
我们可以让tqdm函数返回的迭代器,然后让自己决定进度条一次变动更新多少步.

具体也可以参照tqdm函数的说明.
class tqdm(object):
"""
Decorate an iterable object, returning an iterator which acts exactly
like the original iterable, but prints a dynamically updating
progressbar every time a value is requested.
"""
def __init__(self, iterable=None, desc=None, total=None, leave=False,
file=sys.stderr, ncols=None, mininterval=0.1,
maxinterval=10.0, miniters=None, ascii=None,
disable=False, unit='it', unit_scale=False,
dynamic_ncols=False, smoothing=0.3, nested=False,
bar_format=None, initial=0, gui=False):

3.2 百分位数
以前应该看过这个知识,这里复习一下.numpy.percentile使用(多用于去除离群点).
numpy.percentile(a, q, axis)
- a:输入数组
- q:要计算的百分位数,在0 ~ 100 之间
- axis:沿着它计算百分位数的轴,二维取值0,1.
![image]()

a = range(1,101)
np.percentile(a, 90) #90%的分位数
#90.1 #表示有百分之九十的数小于90.1。
这里我们可以收集讲话人音频的长度,用百分位数查看他们的长度范围分布.据大佬所说音频不能选得太长,因为太长会混入杂音.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号