4.5 Unsupervised Learning: Word Embedding
1. Introduction(引入)
词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用.
最经典的做法就是1-of-N Encoding,它指的就是每一个字都是以向量来表示,只有在自己所属的那个字词索引上为1,其余为0,因此如果世界上的英文字有十万个,那就会是一个十万维的向量,并且只有一个索引为1其余为0.
用这种方式表示的另一个缺点就是无法了解字词之间的关系.
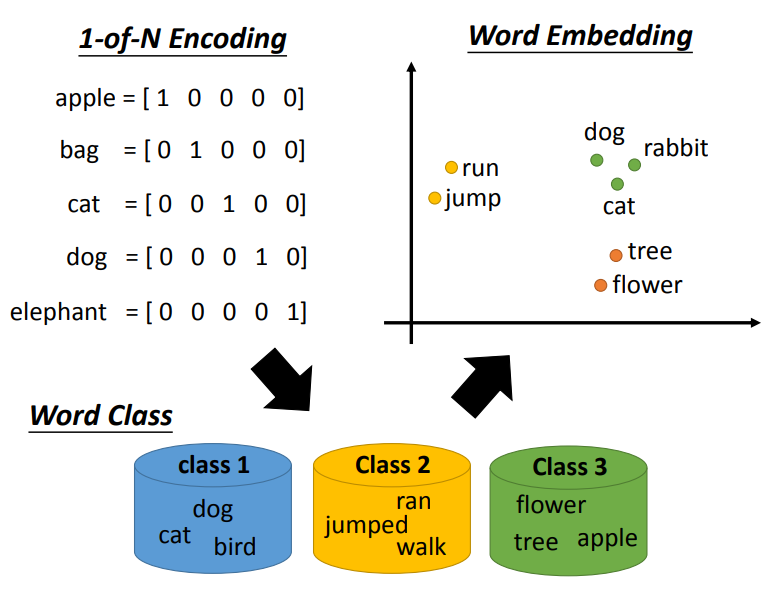
这时就有一个新的方法,称为\(Word\ Class\),就是将关联文字设置为同一类别,以类别来表示,但这种关联方式又有缺点,不能体现类之间的关系(如不能体现class 1与class 2之间的关系),因此有了现在的\(Word\ Embedding\).
Word Embedding是一种将词汇投影到高维度空间的方式,但它的维度依然远比1-of-N的编码方式来的低,也许50维,也许300维,但比起10万维还是低了许多.我们希望在Word Embedding上看到相关的词汇是接近的.
Word Embedding的每个维度都可能有一定含义.比如上图横轴代表生物行为和生物之间的差异.
2. 如何做Word Embedding
2.1 简要概念
Word Embedding是一个无监督学习的方法,只需要让机器阅读大量的文章,就可以知道每个词汇embedding的feature vector是什么样子.
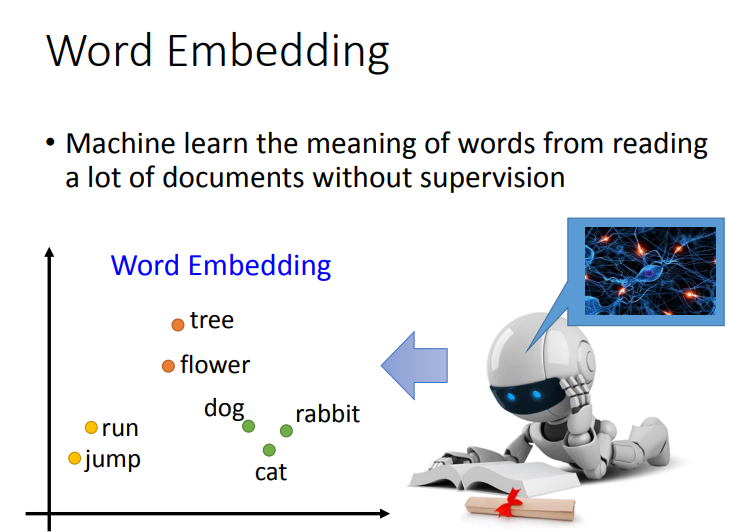
产生词向量是无监督的,我们需要做的就是训练一个神经网络,找到一个function,输入一个词,输出该词对应的word embedding 的 vector.训练数据是一大堆文字,即只有input,没有output.所以是一个无监督学习问题.
那么这个问题怎么解决呢?一个基本思想就是每一个词汇的含义都可以根据它的上下文来得到.比如机器在两个不同的地方阅读到了"小明520宣誓就职"、"小红520宣誓就职",它就会发现"小明"和"小红"前后都有类似的文字内容,于是机器就可以推测"小明"和"小红"这两个词汇代表了可能有同样地位的东西,即使它并不知道这两个词汇是人名.

怎么用这个思想来找出word embedding的vector呢?
2.2 How to exploit the context?
有两种不同体系的做法.
2.2.1 Count based
- 假如\(w_i\)和\(w_j\)这两个词汇常常在同一篇文章中出现,它们的word vector分别用\(V(w_i)\)和\(V(w_j)\)来表示,则\(V(w_i)\)和\(V(w_j)\)会比较接近.
- 代表性例子:\(Glove\ Vector\).
- 两个向量做内积之后的值我们希望愈接近它们共同出现在文章的次数
![image]()

2.2.2 Prediction based
大致作法如下:
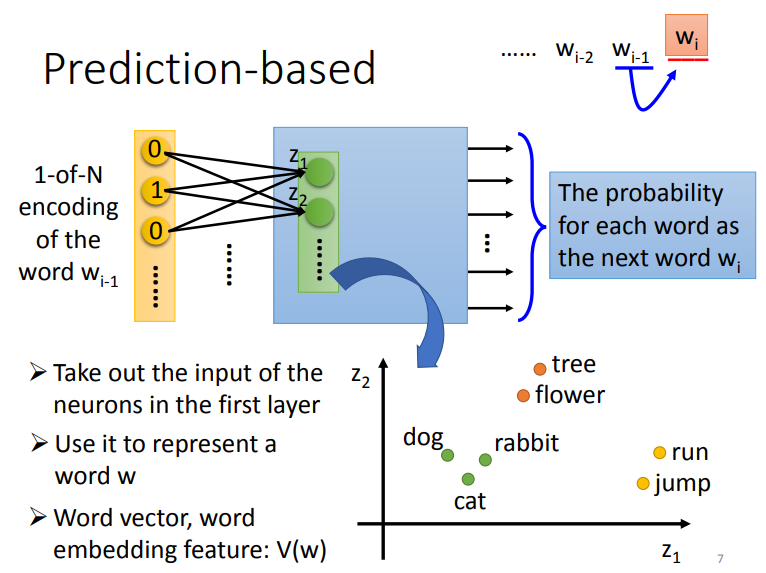
- 建置一个神经网路
- 给前一个字词\(w_{i-1}\),预测下一个字词\(w_i\)是什么
- 输入为1-of-N 的特征向量
- 输出为下一个字的机率(每一个维度都代表是不同字的机率)
- 将第一个hidden layer的input取出
- 每一个Z皆代表一个词(W)
- 因为每一个字都是1-of-N的编码,因此相同的字输出皆相同
- 将Z当做Word Embbeding
- 得到右下图般的向量
![image]()
- 得到右下图般的向量
2.2.2.1 Why prediction works
但是现在又有了新的疑问.为什么第一层的输入与word embedding中的vector是接近的?prediction-based方法是如何体现根据词汇的上下文来了解该词汇的含义这件事呢?
为了使这两个不同的input通过NN能得到相同的output,就必须在进入hidden layer之前,就通过weight的转换将这两个input vector投影到位置相近的低维空间上,也就是说,尽管两个input vector作为1-of-N编码看起来完全不同,但经过参数的转换,将两者都降维到某一个空间中,在这个空间里,经过转换后的new vector 1和vector 2是非常接近的,因此它们同时进入一系列的hidden layer,最终输出时得到的output是相同的。
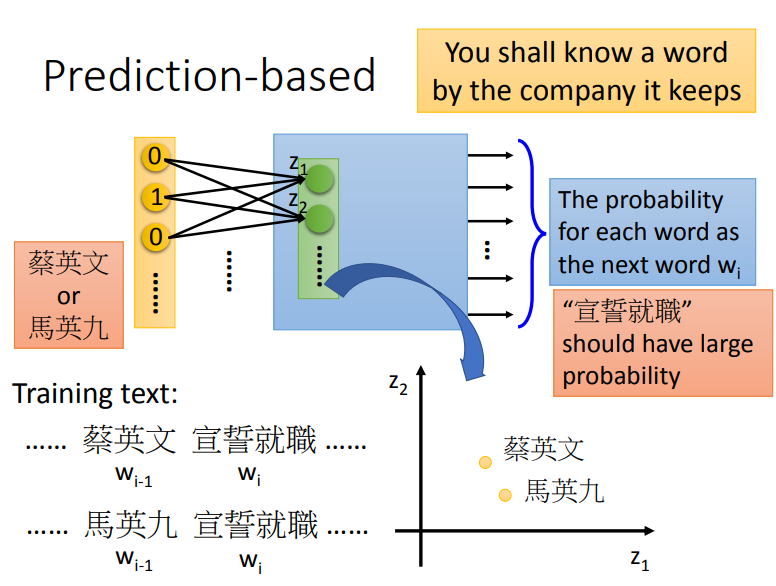
总结:对1-of-N编码进行Word Embedding降维的结果就是神经网络模型第一层hidden layer的输入向量\([z_1,z_2,z_3…]^T\),该向量同时也考虑了上下文词汇的关联,我们可以通过控制第一层hidden layer的大小从而控制目标降维空间的维数.
2.2.2.2 Sharing Parameters
前面仅仅通过前一个词来预测下一个词可能太差了,所以可以引申为通过前几个词来预测下一个词,通常10个是可以得到比较reasonable的结果.
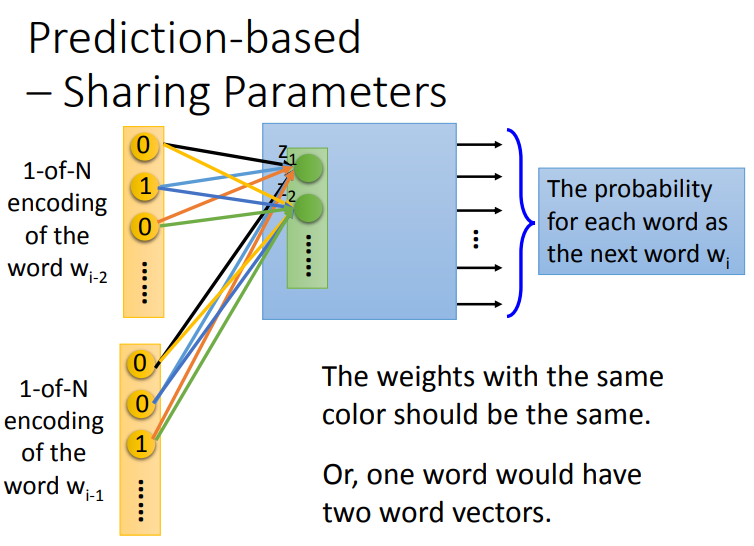
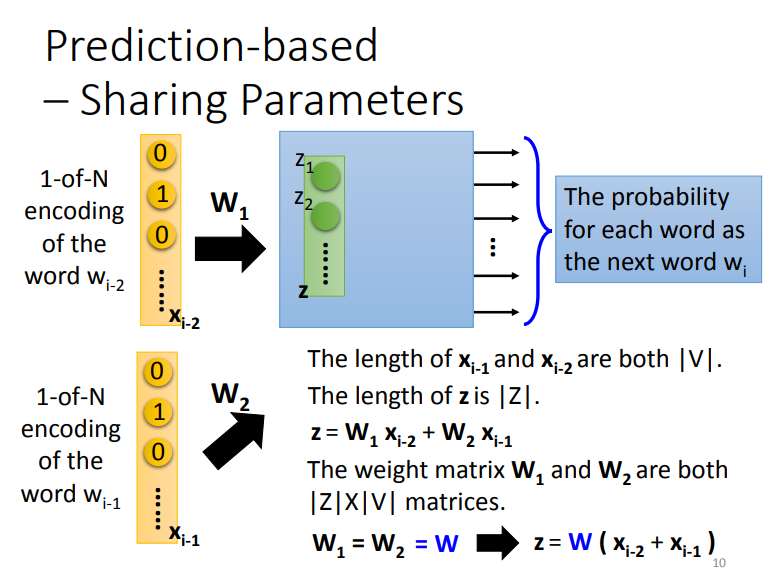
一般来说,就是将\(W_{i-2},W_{i-1}\)的向量串接在一起做为输入.但实际上我们会希望两个词汇的权重是紧密(tight)在一起的,意思就是\(W_{i-2},W_{i-1}\)与\(Z_!\)之间的权重单元是相同的.(因此简报上连接\(Z\)的线条颜色是两两相同的)
这种作法的优点就是可以减少参数值,每一个向量都是10万维的情况下,如果是\(W_{i-10}\)那就100万维的输入了.
请注意,每个维度连接到的weight必须是一样的.否则,一个词会对应有两个词向量.这里李老师说的疑似是当同一个\(word\)放在不同的位置上,如果每个维度对应\(weight\)不同,就会导致得到的同一个word的\(w_i\)的词向量不同.我这里个人理解是它没有考虑到位置关系???
我们将其公式化表示:
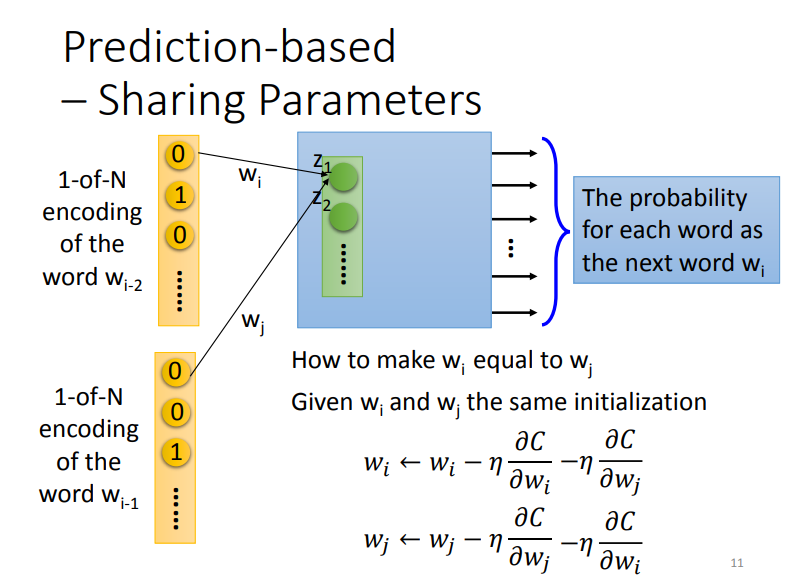
假设有两个\(weight\),分别是\(w_i\)和\(w_j\),那么我们如何让它们相等呢?
- 让\(W_i和W_j\)有相同的初始值.
- 更新权重的时候一方偏微分有多少的变动,另一方就要同步进行
![image]()
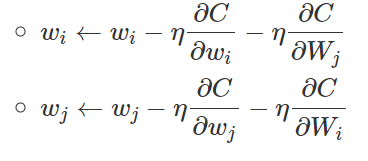
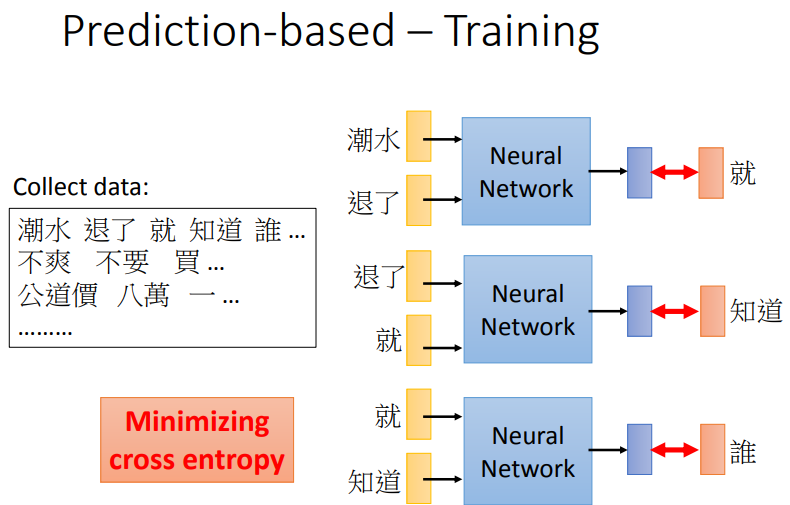
2.2.2.3 How to train model
模型属于非监督式学习,因此你需要大量文本资料,上图为例,潮水退了后面是接'就',我们希望预测的就是'就'.
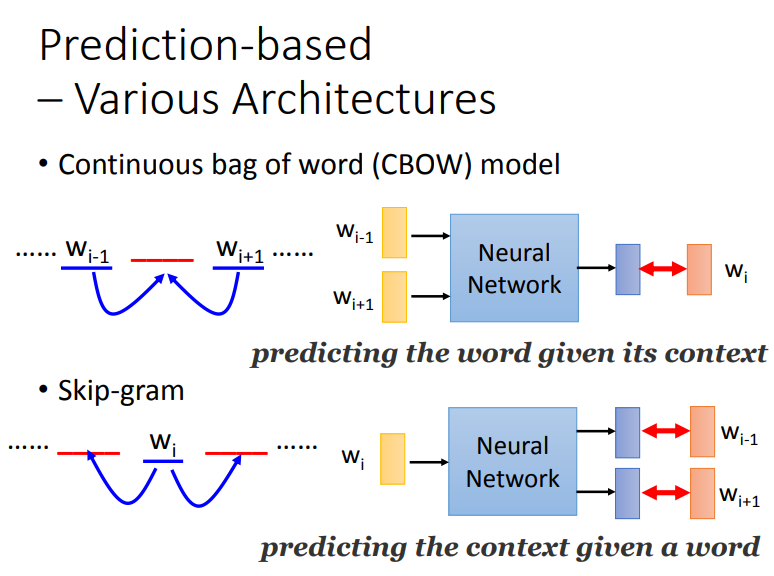
2.2.2.4 Various Architectures
Prediction-based方法还可以有多种变形:
-
CBOW(Continuous bag of word model)
- 拿前后的词汇去预测中间的词汇
-
Skip-gram
- 拿中间的词汇去预测前后的词
![image]()
- 拿中间的词汇去预测前后的词
注意:Word vector并不需要用DNN
各种模型没有一个绝对,只能依自己案例来实作确认那一种符合需求。
3. Word embedding——Application
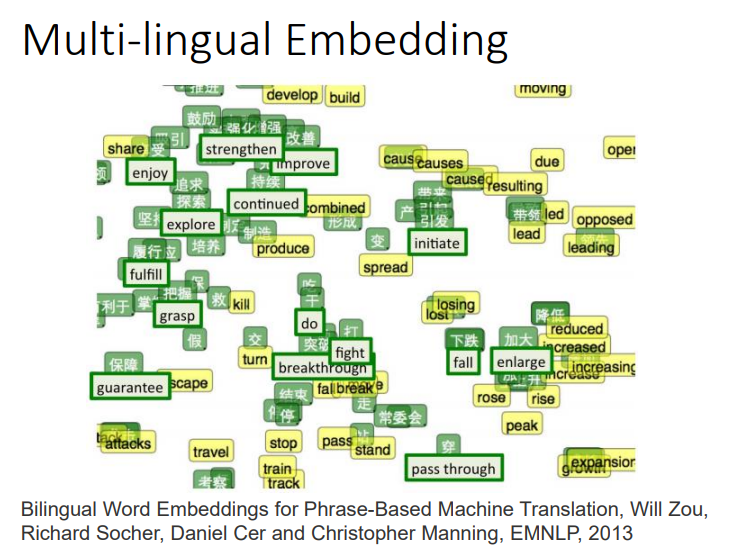
3.1 Multi-lingual Embedding(类似实现翻译)
如果你要用上述方法分别训练一个英文的语料库(corpus)和中文的语料库,你会发现两者的word vector之间是没有任何关系的,因为Word Embedding只体现了上下文的关系,如果你的文章没有把中英文混合在一起使用,机器就没有办法判断中英文词汇之间的关系。
但是,如果你知道某些中文词汇和英文词汇的对应关系,你可以先分别获取它们的word vector,然后再去训练一个模型,把具有相同含义的中英文词汇投影到新空间上的同一个点。
接下来遇到未知的新词汇,无论是中文还是英文,你都可以采用同样的方式将其投影到新空间,就可以自动做到类似翻译的效果了。
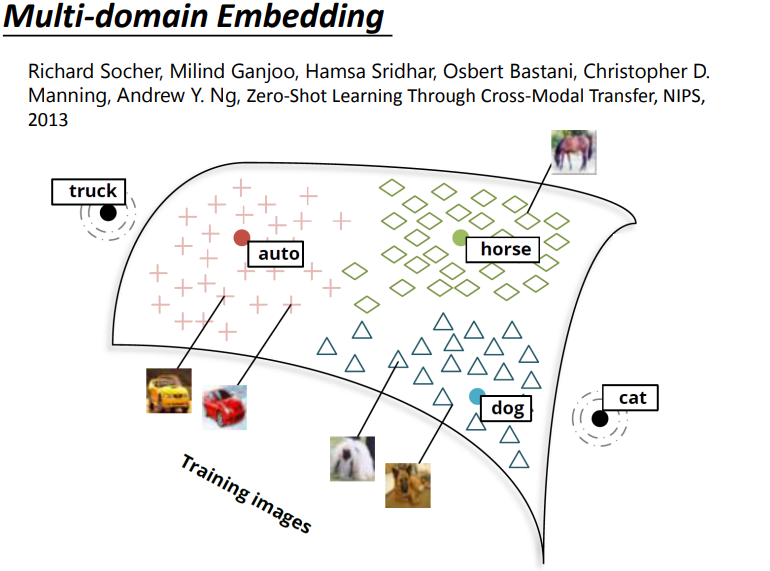
3.2 Multi-domain Embedding(应用于影像分类)
例如,先找一组word vector,比如dog、horse、auto、cat等的vector,这时候我们learning一个model,这个model的input是一张图片,output是一个跟word vector一样维度的vector,这时候我们只需要将一部分图片进行训练使得狗的图片对应dog的word vector,车的图片对应car的word vector这样。
应用训练好的model会找到image(pixel vector)与word vector之间的映射关系,所以即使这个model之前没见过cat图,但是还是能将猫图投影到猫的word vector,对training时没出现的类别也可以进行分类!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号