4.3 Recurrent Neural Network (RNN) II
1. RNN 怎么学习
1.1 Loss Function
如果要做learning的话,你要定义一个cost function来evaluate你的model是好还是不好,选一个parameter要让你的loss 最小.那在Recurrent Neural Network里面,你会怎么定义这个loss呢,下面我们先不写算式,先直接举个例子.
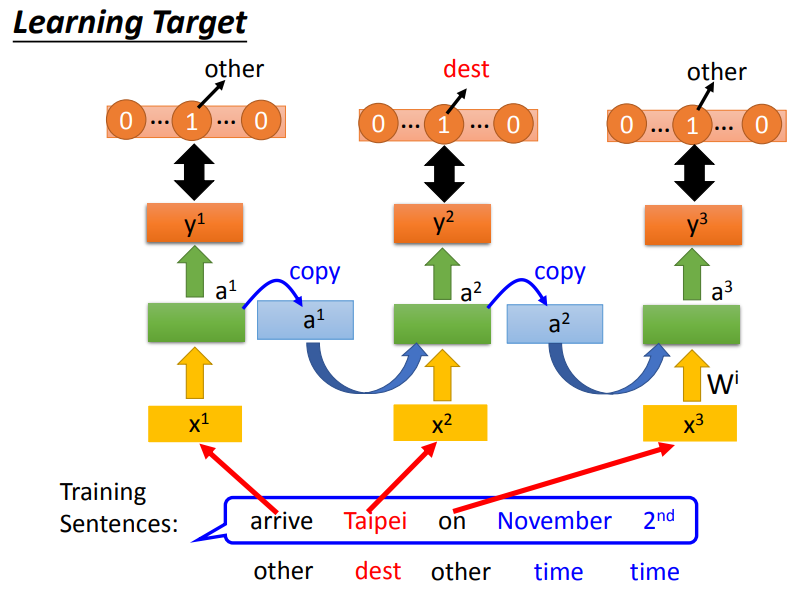
如下图所示,这是一个Slot Filling的例子,我们要将输出的y与映射到slot的reference vector做cross entropy.例如,Taipei对应到的slot是dest,那reference vector在dest上的值为1,其余的值都为0.RNN的输出与reference vector的cross entropy的和就是要minimize的对象.注意:句子里面的词语必须按照语序输入,不能打乱语序!
1.2 Training
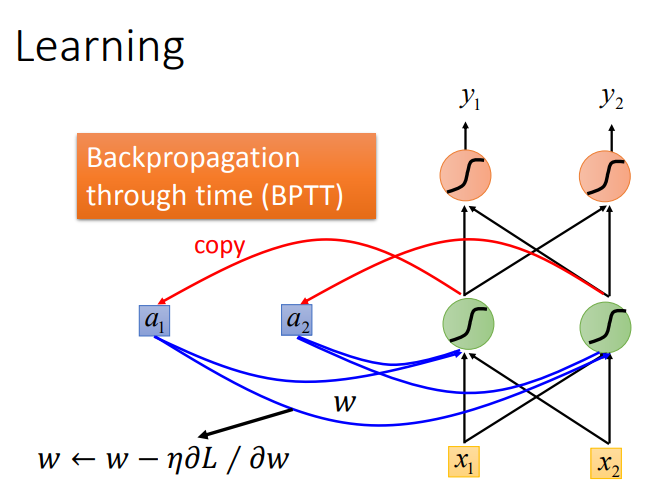
有了这个loss function以后,对于training,也是用梯度下降来做.也就是说我们现在定义出了loss function(L).我要update这个neural network里面的某个参数w,就是计算对w的偏微分,偏微分计算出来以后,就用GD的方法去update里面的参数。在讲feedforward neural network的时候,我们说GD用在feedforward neural network里面你要用一个有效率的算法叫做Backpropagation.那Recurrent Neural Network里面,为了要计算方便,所以也有开发一套算法是Backpropagation的进阶版,叫做BPTT.它跟Backpropagation其实是很类似的,只是Recurrent Neural Network它是在time sequence上运作,所以BPTT它要考虑时间上的information.
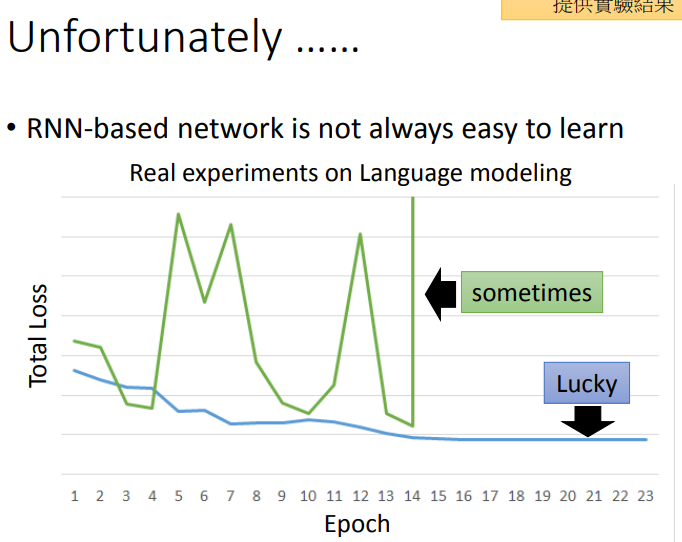
如下图所示,RNN的Training是比较困难的,我们希望随着Epoch地增加,loss跟图中蓝色线一样慢慢下降,但是很不幸的是我们在训练过程中会出现绿色线的结果.
为什么会这样呢?如下图所示,RNN的error surface(Total Loss对参数变化)是非常崎岖的,这里的意思就是loss在某些地方比较平坦,在某些地方又比较陡峭。假如把橙色点当作起始点,用Gradient Descent调整参数,然后更新参数,可能会得到loss猛增的结果。最坏的情况是一脚踩在悬崖上,由于之前一直处在平坦区域,gradient很小,那么就会把learning rate调的比较大,因此踩在悬崖上时gradient变得很大,就会整个飞出去,可能会变成\(NaN\).
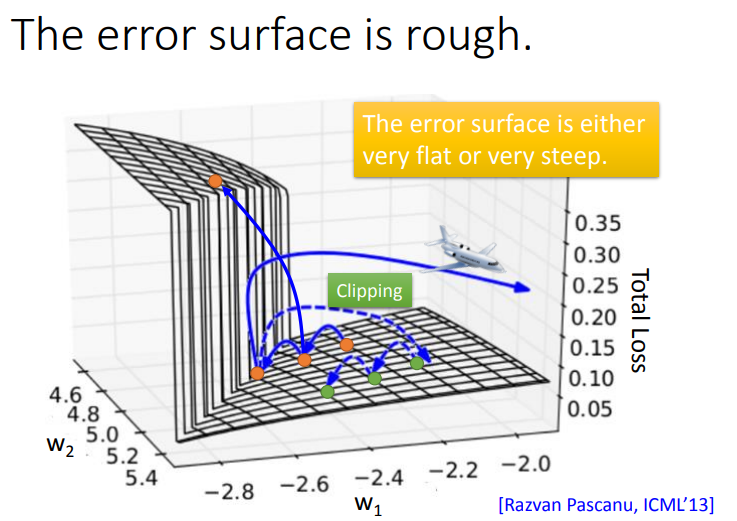
这种问题怎么解决的呢?RNN的创作者使用了Clipping来解决这个问题.Clipping就是当gradient大于某个threshold时,就让\(gradient = threshold\).
1.2.1 Why RNN has the trait?
那么,为什么RNN会有这种奇特的特性?我们用一个直观方法来了解.把某一个参数做小小的变化,看它对network output的变化有多大,你就可以测出这个参数的gradient的大小.
举一个简单的例子.只有一个neuron,这个neuron是linear.input没有bias,input的weight是1,output的weight也是1,transition的weight是w.也就是说从memory接到neuron的input的weight是w.
现在我假设给neural network的输入是(1,0,0,0),那这个neural network的output会长什么样子呢?比如说,neural network在最后一个时间点(1000个output值是\(w^{999}\))

当w从1变到1.01后,y^1000从1变到了20000,此时L对w的微分值很大,所以需要较小的Learning rate;当w从0.99变到0.01后,y^1000从0变到了0,此时L对w的微分值很小,所以需要较大的Learning rate.这样导致设置learning rate很麻烦,你的error surface很崎岖,你的gardient是时大时小的,在非常小的区域内,gradient有很多的变化.
从这个例子你可以看出来说,为什么RNN会有问题.RNN training的问题其实来自它把同样的东西在transition的时候反复使用.所以这个w只要一有变化,它完全由可能没有造成任何影响,一旦造成影响,影响都是天崩地裂的(所以gradient会很大,gradient会很小).
1.2.2 How can RNN solve the problem?
有什么样的技巧可以告诉我们可以解决这个问题呢?其实广泛被使用的技巧就是LSTM,LSTM可以让你的error surface不要那么崎岖.它可以做到的事情是,它会把那些平坦的地方拿掉,解决gradient vanish的问题,不会解决gradient explode的问题.有些地方还是非常的崎岖的(有些地方仍然是变化非常剧烈的,但是不会有特别平坦的地方).
如果你要做LSTM时,大部分地方变化的很剧烈,所以当你做LSTM的时候,你可以放心的把你的learning rate设置的小一点,保证在learning rate很小的情况下进行训练.
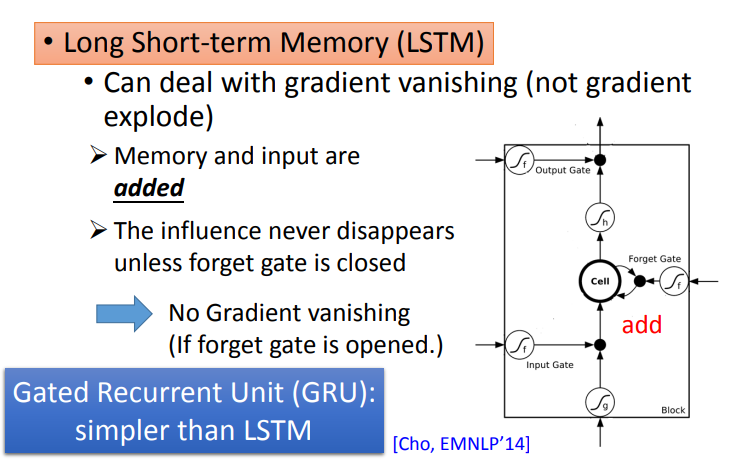
那为什么LSTM可以解决梯度消失的问题呢?为什么可以避免gradient特别小呢?
因为在RNN里面,在每一个时间点,memory里面的信息都会被清理掉;在LSTM里面,会把原来memory里面的值乘上一个值,然后再加上input的值放到Cell里面.对LSTM来说,除非forget gate被使用,否则不会把memory之前的信息给清除掉.
所以今天它和RNN不同的是,如果今天你的weight可以影响到memory里面的值的话,一旦发生影响会永远都存在.不像RNN在每个时间点的值都会被format掉,所以只要这个影响被format掉它就消失了.但是在LSTM里面,一旦对memory造成影响,那影响一直会被留着(除非forget gate要把memory的值洗掉),不然memory一旦有改变,只会把新的东西加进来,不会把原来的值洗掉,所以它不会有gradient vanishing的问题.
另外一个版本是GRU(Gated Recurrent Unit),只有两个gate操作memory,需要的参数少,不容易过拟合.它秉承的是只有memory里面的信息被清除掉,才会新的信息给添加进来.它会把input gate跟forget gate联动起来,也就是说当input gate打开的时候,forget gate会自动的关闭(format存在memory里面的值),当forget gate没有要format里面的值,input gate就会被关起来.
1.2.3 其他方法解决gradient vanish
其实还有其他的technique是来handle gradient vanishing的问题。比如说clockwise RNN或者说是Structurally Constrained Recurrent Network (SCRN)等等.
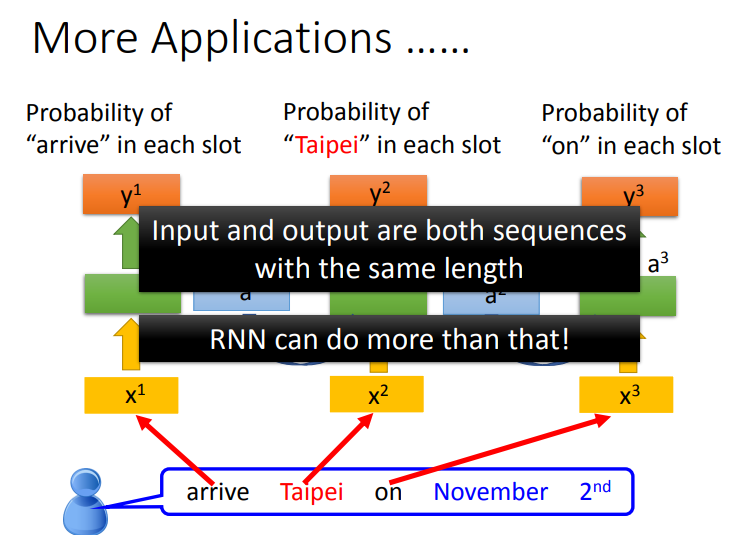
2. RNN 的其他应用
其实RNN有很多的application,前面举得那个solt filling的例子。我们假设input跟output的数目是一样的,也就是说input有几个word,我们就给每一个word slot label.那其实RNN可以做到更复杂的事情.
2.1 Many to one
RNN可以做到更复杂的事情,比如说input是一个sequence,output是一个vector.
(1) sentiment Analysis
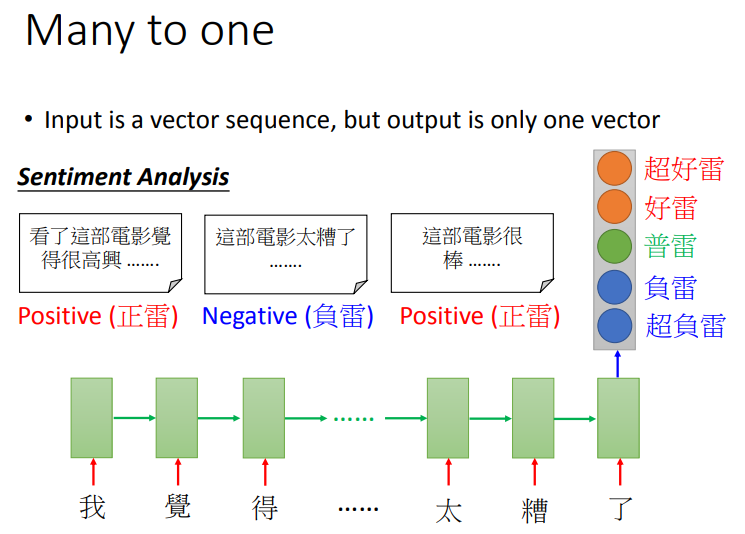
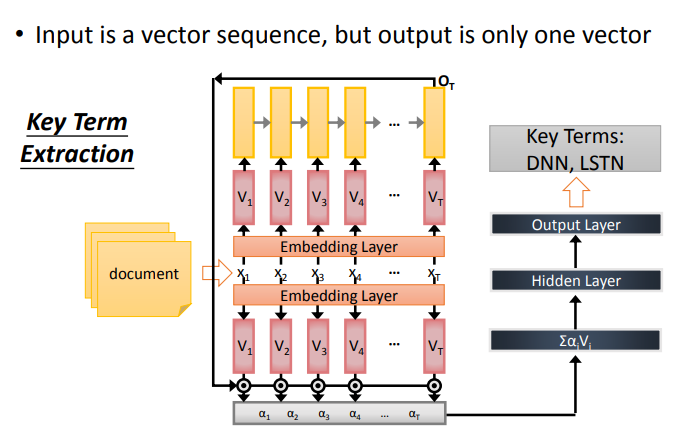
(2) Key Term Extraction
这里是一个关键词分析系统,给它一篇文章,提取出文章中的关键词,然后把含有关键词标注的文章作为RNN的训练资料.
2.2 Many to Many
如果input和output都是sequence,但output比input更短时,RNN可以解决这类问题.
(1) 语音辨识
在语音辨识这个任务里面input是acoustic sequence(说一句话,这句话就是一段声音讯号)。我们一般处理声音讯号的方式,在这个声音讯号里面,每隔一小段时间,就把这小段时间用vector来表示。这个一小段时间是很短的(比如说,0.01秒).那output sequence是character sequence.
如果用原来的RNN(slot filling的那个RNN)来处理这个问题,把这一串input丢进去,它充其量只能做到说,告诉你每一个vector对应到哪一个character。加入说中文的语音辨识的话,那你的output target理论上就是这个世界上所有可能中文的词汇,常用的可能是八千个,那你RNNclassifier的数目可能就是八千个.虽然很大,但也是没有办法做的。但是充其量只能做到说:每一个vector属于一个character。每一个input对应的时间间隔是很小的(0.01秒),所以通常是好多个vector对应到同一个character.所以你的辨识结果为"好好好棒棒棒棒棒".
这时可能会考虑一个方法"trimming"(把重复的东西拿掉),就变成"好棒".这这样会有一个严重的问题,因为它没有辨识"好棒棒".
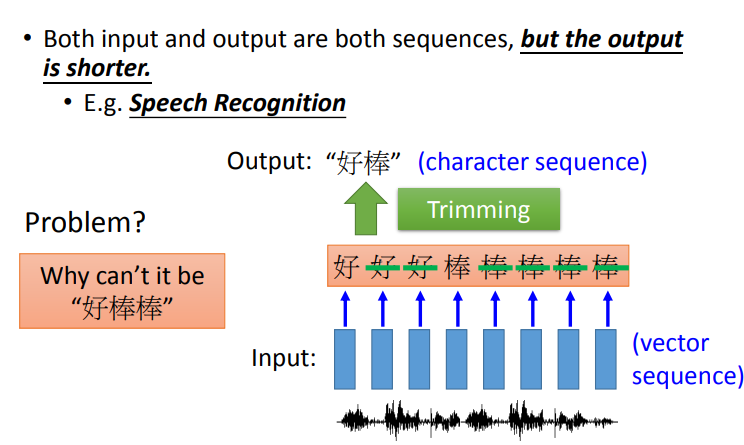
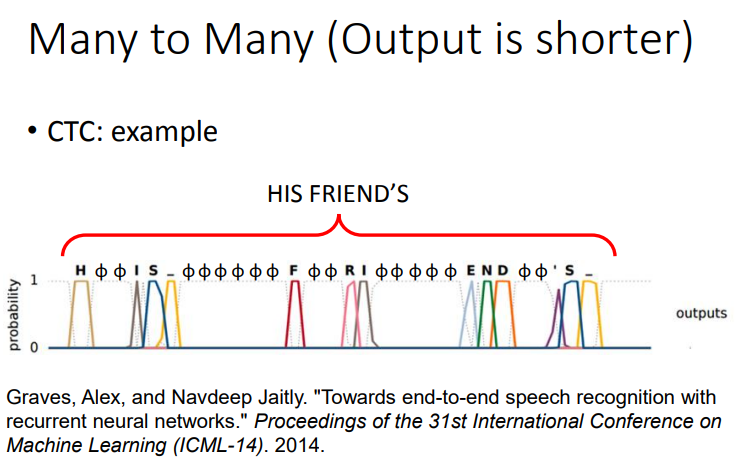
将"好棒"与"好棒棒"区别开的一个方法是CTC.这个方法是:我们在output时候,我们不只是output所有中文的character,我们还有output一个符号,叫做"null"(没有任何东西)。所以我今天input一段acoustic feature sequence,它的output是"好 null null 棒 null null null null",然后我就把"null"的部分拿掉,它就变成“好棒”。如果我们输入另外一个sequence,它的output是“好 null null 棒 null 棒 null null”,然后把"null"拿掉,所以它的output就是"好棒棒".这样就可以解决叠字的问题了.

那么CTC怎么训练呢?CTC在做training的时候,train data就会告诉你说,这一串acoustic features对应到这一串character sequence,但它不会告诉你说"好"是对应第几个frame 到第几个frame.那么解决方法就是使用穷举法.简单来说就是,我们不知道"好"对应到那几个frame,"棒"对应到哪几个frame.假设我们所有的状况都是可能的。可能第一个是"好 null 棒 null null null",可能是"好 null null 棒 null null",也可能是"好 null null null 棒 null".我们不知道哪个是对的,那假设全部都是对的.在training的时候,全部都当做是正确的,然后一起train.但是穷举所有的可能,那可能性太多了,有没有巧妙的算法可以解决这个问题呢?那今天我们就不细讲这个问题.
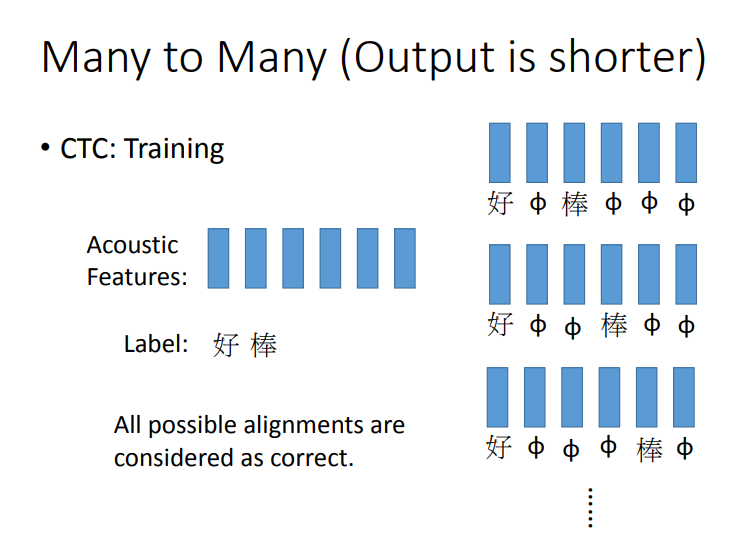
下图是一个CTC的例子.
(2) Sequence to sequence learning
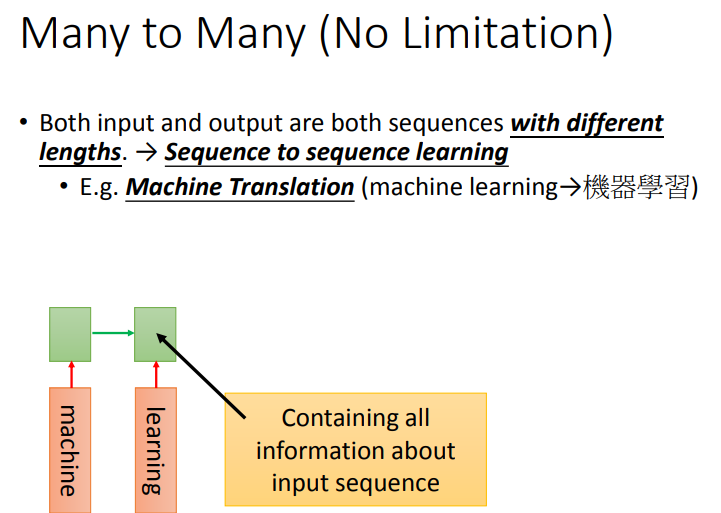
另外一个神奇RNN的应用叫做sequence to sequence learning,在sequence to sequence learning里面,RNN的input跟output都是sequence(但是两者的长度是不一样的).
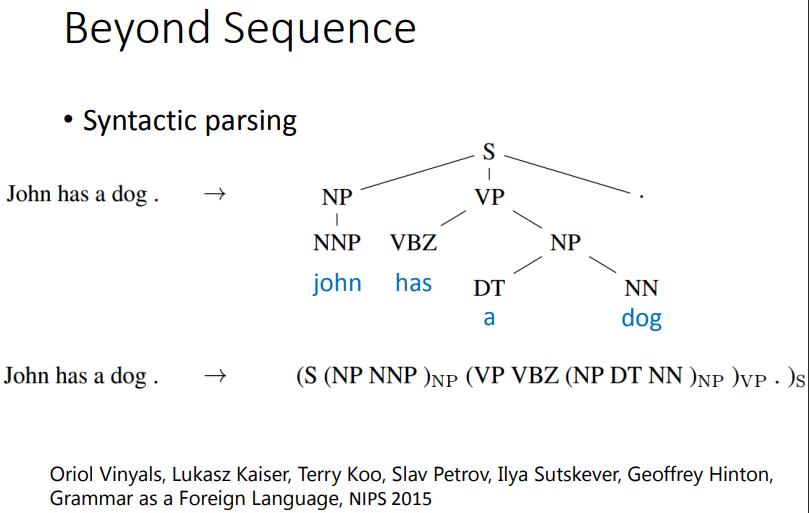
利用sequence to sequence的技术,甚至可以做到Beyond Sequence。这个技术也被用到syntactic parsing。synthetic parsing这个意思就是说,让machine看一个句子,它要得到这个句子的结构树,得到一个树状的结构。怎么让machine得到这样的结构呢?,过去你可能要用structured learning的技术能够解这个问题。但是现在有了 sequence to sequence learning的技术以后,你只要把这个树状图描述成一个sequence(具体看图中 john has a dog)。所以今天是sequence to sequence learning 的话,你就直接learn 一个sequence to sequence model。它的output直接就是syntactic parsing tree。这个是可以train的起来的,非常的surprised.
3. RNN v.s. Structured Learning
3.1 Comparsion
使用deep learning跟structure learning的技术有什么不同呢?首先假如我们用的是unidirectional RNN/LSTM,当你在 decision的时候,你只看了sentence的一半,而你是用structure learning的话,比如用Viterbi algrithm你考虑的是整个句子。从这个结果来看,也许HMM,SVM等还是占到一些优势的。但是这个优势并不是很明显,因为RNN和LSTM他们可以做Bidirectional ,所以他们也可以考虑一整个句子的information.
在HMM/SVM里面,你可以explicitly的考虑label之间的关系
举例说,如果做inference的时候,再用Viterbi algrithm求解的时候(假设每个label出现的时候都要出现五次)这个算法可以轻松做到,因为可以修改机器在选择分数最高的时候,排除掉不符合constraint的那些结果,但是如果是LSTM/RNN,直接下一个constraint进去是比较难的,因为没办法让RNN连续吐出某个label五次才是正确的。所以在这点上,structured learning似乎是有点优势的。如果是RNN/LSTM,你的cost function跟你实际上要考虑的error往往是没有关系的,当你做RNN/LSTM的时候,考虑的cost是每一个时间点的cross entropy(每一个时间的RNN的output cross entropy),它跟你的error不见得是直接相关的。但是你用structure learning的话,structure learning 的cost会影响你的error,从这个角度来看,structured learning也是有一些优势的。最重要的是,RNN/LSTM可以是deep,HMMM,SVM等它们其实也可以是deep,但是它们要想拿来做deep learning 是比较困难的。在我们上一堂课讲的内容里面。它们都是linear,因为他们定义的evaluation函数是线性的。如果不是线性的话也会很麻烦,因为只有是线性的我们才能套用上节课讲的那些方法来做inference.
最后总结来看,RNN/LSTM在deep这件事的表现其实会比较好,同时这件事也很重要,如果只是线性的模型,function space就这么大,可以直接最小化一个错误的上界,但是这样没什么,因为所有的结果都是坏的,所以相比之下,deep learning占到很大的优势.

3.2 Integerated Together
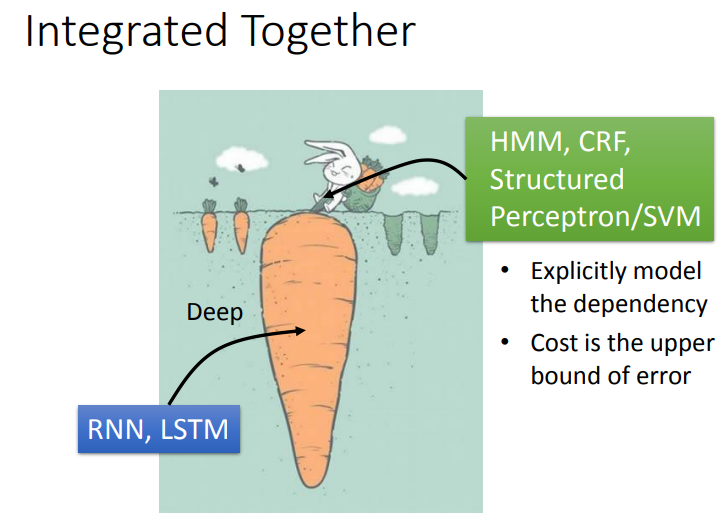
如下图所示,其实两者是可以结合起来的.input features 先通过RNN/LSTM,然后RNN/LSTM的output再做为HMM/svm的input.用RNN/LSTM的output来定义HMM/structured SVM的evaluation function,如此就可以同时享有deep learning的好处,也可以有structure learning的好处.
=说实话,后面没听懂=======

 浙公网安备 33010602011771号
浙公网安备 33010602011771号