2.5 类神经网路训练不起来怎么办 (五):批次标准化 (Batch Normalization)简介
1. 提出背景
在前文,我们提过\(error\ surface\)在不同方向的斜率不一样,因此采用固定的学习率很难将模型\(train\)起来,上节提出了自适应学习率,这里还有一个方法就是直接将e\(rror\ surface\)铲平.
或许首先想要提出的是为什么会产生不同方向上斜率相差很大的现象.观察下图,假设\(Y = w_1x_1+w_2x_2\).则\(Loss = \hat y - Y\).
假设\(w_1\ change\)了,那么什么情况会导致Loss变化很小.一个可能的情况就是\(w_1\)配对的\(x_1\)取值都很小,所以计算出的\(Y\)改变也不大.
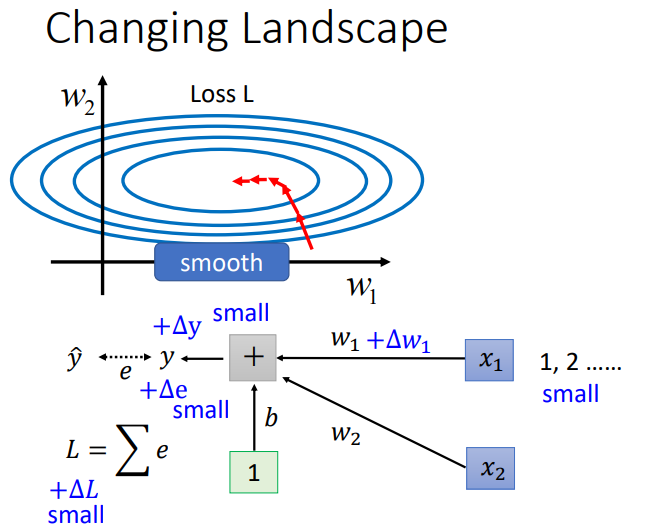
反之,假设\(w_2\)配对的\(x_2\)取值都很大,那么\(Y\)的变化就会很大,则\(loss\)变化也会很大.
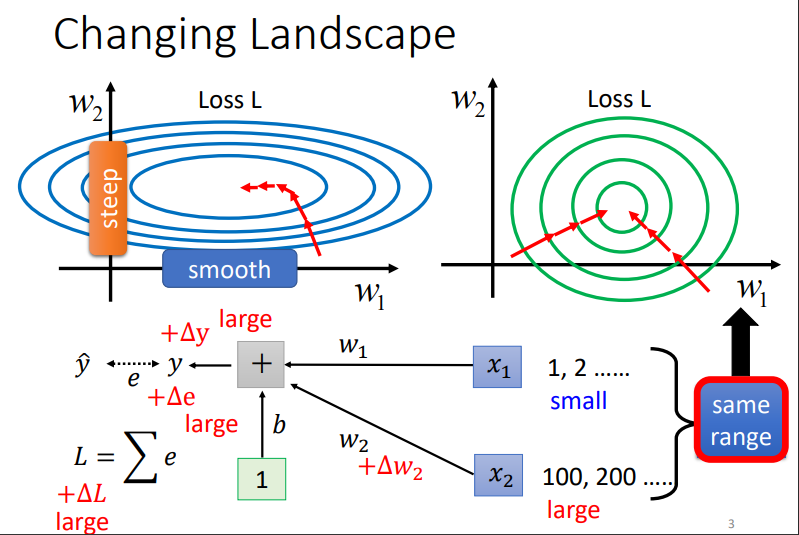
由于输入自变量 x 的量级不同,导致不同参数 w 的loss变化速度不同,也就形成了坡度不同的error surface.故而,为了使不同参数的loss 变化速度一样,我们只需要让自变量 x 全部处于同一量级上,这就叫做标准化!!!
2. Feature Normalization(归一化)
归一化有很多种方式.假设每个自变量都是一个向量,有多维.x的上标表示第R个自变量,x的下标表示第 i 维.

将每个自变量的第 i 维抽出来,计算平均值和标准差,再用来给第 i 维数值进行标准化.用标准化后的数值代表原来的数值,且平均值变为\(0\),标准差变为\(1\).所有\(\tilde{x}\)平均值都为 0,方差都为 1.自变量标准化能使梯度下降收敛更快!
也就是说,当特征化后,原来很大的\(x_i\)会变小,这样就不会引起一个梯度大,一个梯度小的问题.
\(update\):假设\(x\)是\([batch,feature]\),那么Feature Normalization是在每个样本的\(feature\)维度进行标准化,比如\(x[:,0]\)减去该列的均值,再除以方差.这样才能将取值范围大的特征变小.
2.1 每层都需要一次 Normalization
经过\(feature\ normalization\)后的 \(\tilde{x}\) 都在同一量级,但是\(W_1\)的不同维度可能有不同的量级,因此计算出来的 z 在不同维度也可能有不同的量级.所以隐藏层 \(z\)或\(a\) 也需要进行标准化.
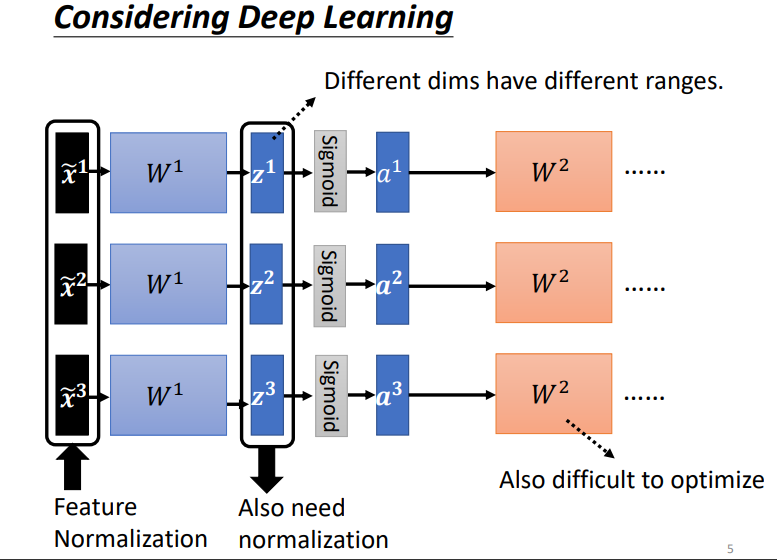
可能会提出疑问,到底是在激活函数层前使用Normalization还是激活函数层后使用Normalization.但一般而言,normalization 步骤要放在 activation function 之前或之后都是可以的.如果选择的是 sigmoid,比较推荐对 \(z\) 做 feature normalization.因为 Sigmoid 在 0 附近斜率比较大,所以如果对 \(z\) 做 feature normalization,把所有的值都挪到 0 附近,算 gradient 时,出来的值会比较大.
怎么对\(z\)做Normalization呢?方法也差不多.
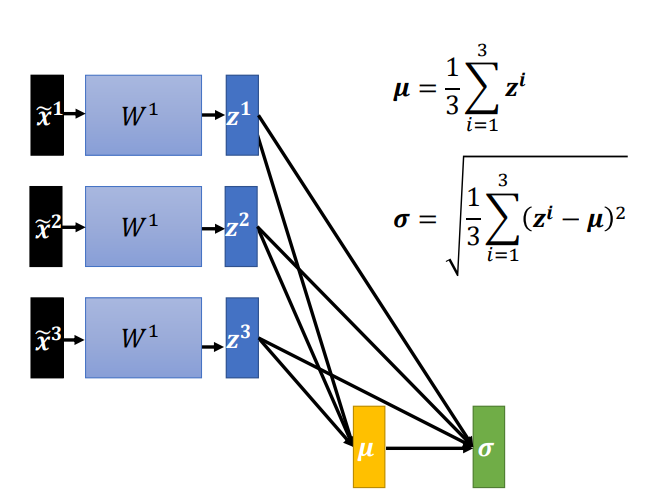
2.2 对一批 \(z\) 数据进行归一化
通过Normalization,模型变为需一次处理一批 features 的模型,数据之间相互关联.
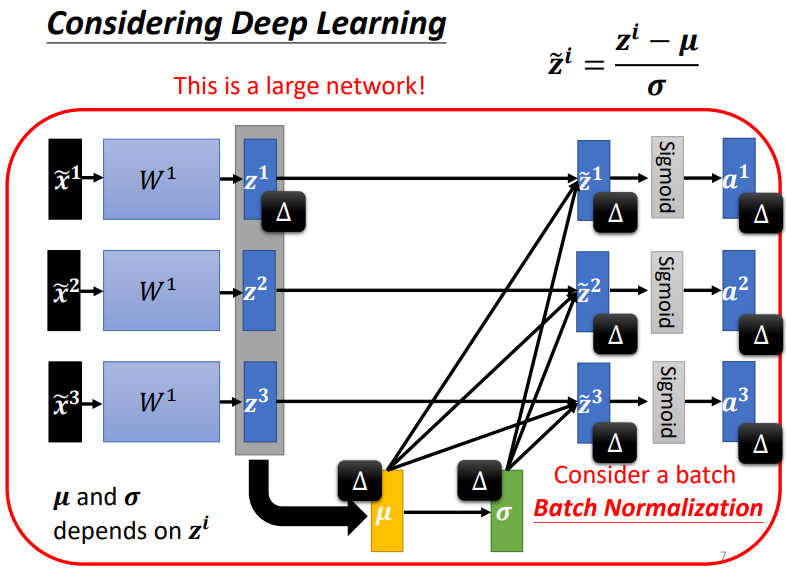

这也就是\(Batch\ Normalization\).计算出来的平均值向量和标准差向量大小取决于 z,所以这是一个大型网络,假如将所有的资料输入进去,GPU的内存不够存所有的训练资料,所以分批次输入资料,保证一次只对一个batch 进行标准化.但是批次标准化适用于 batch size 大的,因为只要batch够大就能足以代表全部分布.
2.3 Batch Normalization 加入限制
往往在批次标准化后还要加一层网络,这时因为\(Normalization\)后,\(z\)的均值会是0,可以视作是给network一些限制,但这个限制可能会带来负面的影响,因此就加入\(\beta\)和\(\gamma\)(可以理解为噪音),用于调整 z 的分布.
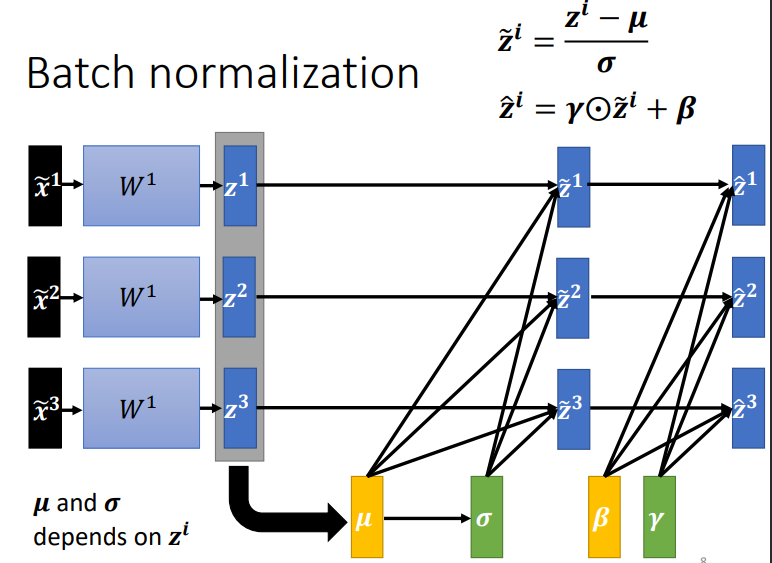
但会有人质疑,这样操作与\(Normalization\)的初衷相违背.但通常我们会将\(\gamma\)设为\(1\),\(\beta\)设为\(0\).所以刚开始训练时,每个\(dimension\)的分布还是比较接近的.到后来根据训练调整\(\gamma\)和\(\beta\)的值.
2.4 Testing 时会遇到的问题
如果我们已经有了给定的\(Testing\)数据集,可以将数据集分批次\(Normalization\).但实际上我们获得\(Testing\ dataset\)的大小是不固定的,不可能每次都等数据凑齐\(batch\)后再\(testing\).但是没有\(\mu\)难以标准化.这个问题的解决依赖\(train\ dataset\).在testing中没有batch,而training时有 t 个batch,就有 t 个μ.所以Pytorch通过计算training中的 moving average(滑动平均)来代替testing的μ和\(\sigma\)!

滑动平均是计算\(train\ set\)每个\(batch\)的μ,使用上图的公计算基于\(train\ set\)的μ.
2.5 Batch Normalization对比实验
黑线是没有做BN的结果,而红色即是做了BN后的结果.虽然红线和黑线差不多的\(acc\),但显然红线更快.一般激活函数选择RELU.
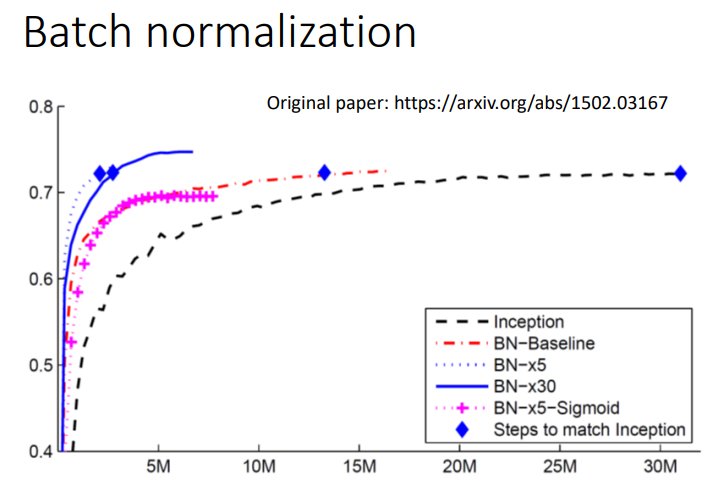
当做了BN后,error surface会比较容易训练,因此可以将\(lr\)调大.
2.6 其他Normalization 方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号