LHY2022-HW02-Speech Recognition
1. 实验结果纪录
纪录一下调整参数带来的结果.不过语音识别这块完全不熟.
1.1 Simple Baseline
- acc>0.45797
直接上传助教代码

1.2 Middle Baseline
- acc>0.69747
助教给与了提示需要我们将frame拼接,可以达到更好的训练效果.进行了几轮尝试
(1) 拼接11维frame,将39维改为39 * 11 维
实际还是没过baseline,从后面的实验结果来看需要增加模型结构的复杂程度.
![image]()

(2) 拼接11维frame,将模型结构的结点层数定义为3层,增加dropout(0.5)
修改后欠拟合了,需要将dropout调小.
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.Dropout(0.5),
)

(3) 训练轮数调整到25,学习率不变,隐藏层增加到6,隐藏层维数调整到1024,dropout调整到0.1,其余与上一致
擦线过Middle Baseline,在训练的时候可以发现train set的acc过了0.8,而test set的acc只能保持在0.69.

1.3 Strong Baseline
- acc>0.75028
(1) dropout 调整到 0.25
因为之前的训练可以观察到明显的过拟合,因此将dropout调大至0.25,提高了一点.此处的train set的acc和test set的acc基本一致,保持在大约0.7的位置.

(2) batch_size调到2048,lr调至0.001
这里按李老师提示,实验判断模型宽浅以及窄深对训练哪个更好
- 超参数设置
# data prarameters
concat_nframes = 11 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.8 # the ratio of data used for training, the rest will be used for validation
# training parameters
seed = 0 # random seed
batch_size = 2048 # batch size
num_epoch = 25 # the number of training epoch
learning_rate = 0.001 # learning rate
model_path = './model.ckpt' # the path where the checkpoint will be saved
# model parameters
input_dim = 39 * concat_nframes # the input dim of the model, you should not change the value
hidden_layers = 6 # the number of hidden layers
hidden_dim = 1024 # the hidden dim
使用torchsummary看模型参数:
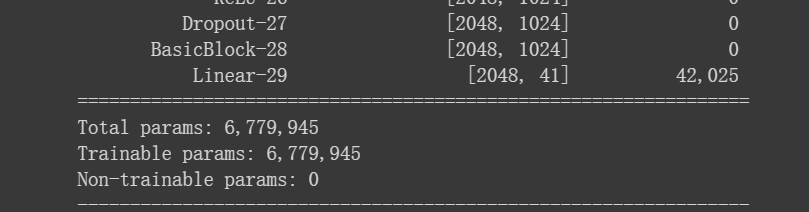
只有一个过了middle baseline.

观察模型变深对训练的影响,将隐藏层设置为8:
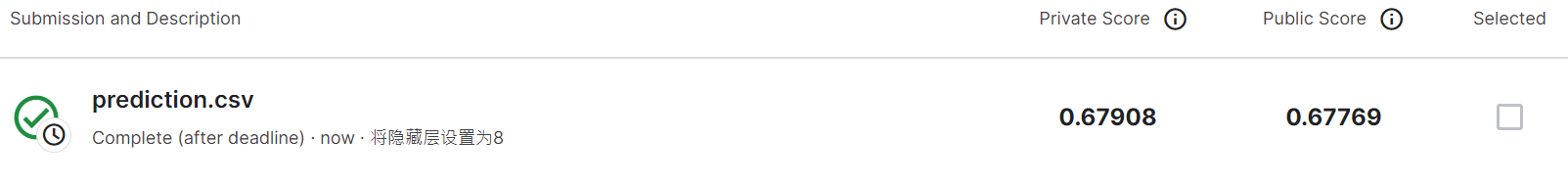
观察模型变窄对训练的影响,将隐藏维度设置为2048,比加深效果好点,但都不如原来:

(3) 按ppt提示试一下还没学的BN层
看起来效果很好,训练时train set和test set的准确率相近.

(4) 训练集验证集占比改为9:1,并把frame拼接从11改为13
效果变好了,考虑到训练集和验证集准确率差不多,考虑把模型改复杂点或者拼接frame变大.

(5) 试着把frame调大至15
把epoch数改到了30,从训练情况来看,早停法还没有停.但是效果更好了.

(6) frame = 17,层数加到8
过了线,模型还能变复杂一点.

1.4 Boss Baseline
- acc>0.82324
(1) 将layers=10
把模型变复杂又较小提升,助教提示使用RNN,这里还没学先放着.

2. 总结
2.1 train set与test set 的划分问题
分出训练集和测试集的策略:传统机器学习将整体20%-30%作为测试集,但这适用于总体数据量规模一般的情况(如100-10000个样本),在大数据时期,分配比例会发生变化,如100万数据时,训练:验证:测试=98:1:1;超过百万时,训练:验证:测试=95:2.5:2.5.
2.2 模型变宽还是变深
上面虽然测试过,但是当时我并没有看具体模型的参数规模,优化做得不好,这里有人做了实验,也是效果不是很好Click.
2.3 batch_size和learning rate
关于为什么将\(batch\ size\)调大需要调大学习率.参考这个深度学习中batch/lr/epoch三者的关系和为什么batch size增大之后,可以增加学习率而不发散?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号