2.4 类神经网路训练不起来怎么办 (四):损失函数 (Loss) 也可能有影响
1. classification 与 regression 的区别
1.1 classification 与 regression 输出的区别
classification中,我们用 one-hot 向量表示不同的类别(一个向量中只有1 个 1 ,其余都为 0,1 在不同的位置代表不同类别).在regression中的神经网络输出只有一个,而classification则有多个输出.
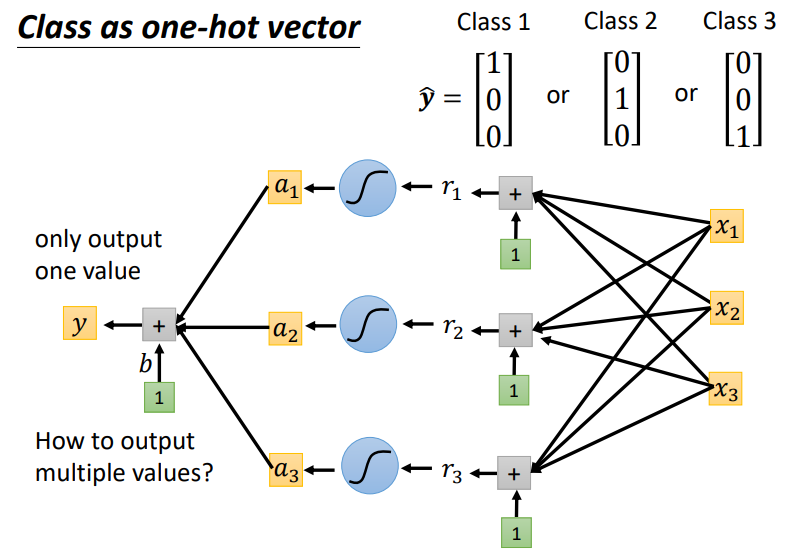
如何由一个输出变成多个输出呢:在最后一层乘上不同的 w ,加上不同的 b。将下图中的数值y1、y2、y3组合在一起形成新的向量 y。

1.2 classification 与 regression 计算 loss 的处理区别
在regression中,直接拿输出数值 y和真实数值计算接近度;而在 classification中,是将多个输出数值组成一个向量,向量经过 softmax 后形成新的向量,再拿新的向量去和不同类别计算接近度.softmax的含义可以简单理解成将含有各种各样数值的向量y 转变成只含有 0 和 1 的向量\(y^{'}\)
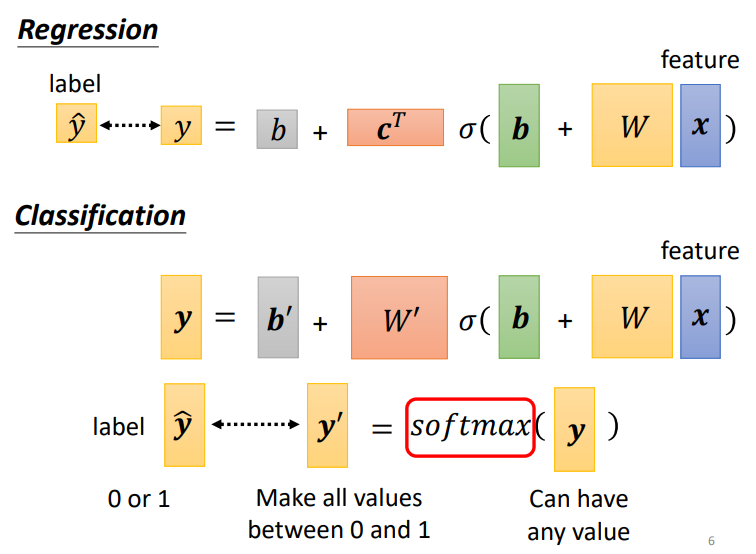
1.2.1 softmax的运作机制
下面式子就是softmax,分子是用来将 y都变成正值!分母是用来归一化,保证输出 y′ 在0 与 1之间!

我们在多分类问题常常在最后一层套softmax,但在二分类问题使用sigmoid比较多.但实际上这两个可以看作是一样的.sigmoid为什么可以视为概率是从条件概率的公式推导而来,而softmax的公式可以由多类问题的条件概率推导而来.具体参考Click.还有为什么两者可以看作相同可以看这个Click.
1.3 classification 与 regression 计算 loss 的方法不同
regression采用 MSE 和 MAE的方法计算loss函数;而classification则采用cross entropy(交叉熵)的方法计算loss函数,最小交叉熵等价于maximizing likelihood(最大似然),两者没有区别!!
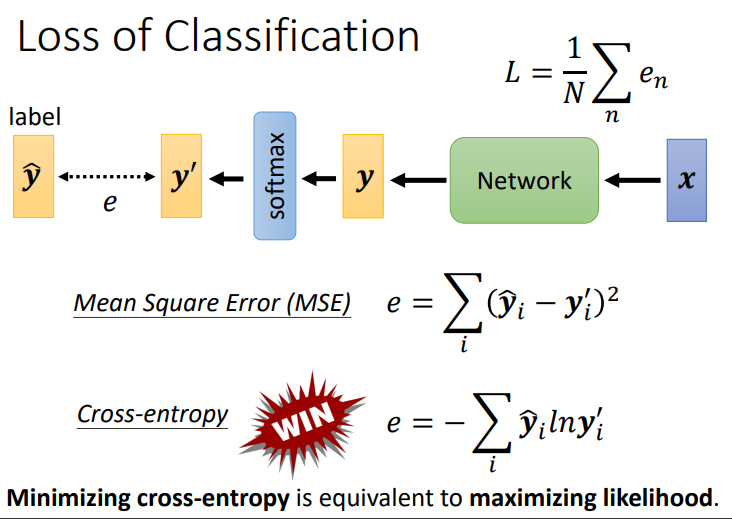
1.3.1 为什么交叉熵适用于分类问题
我们举一例子说明,我们将\(y_3\)的值设定很小,以此避免对\(loss\)有大影响.下面两幅图是\(y_1\)和\(y_2\)对Loss的影响.图上红色表示\(Loss\)很大,蓝色则表示很小.所以在training时,我们希望\(loss\)可以走到右下角的地方.如果我们从左上角开始,\(MSE\)在红色处梯度很小不易变化,而$ cross\quad entropy$却很容易梯度下降.
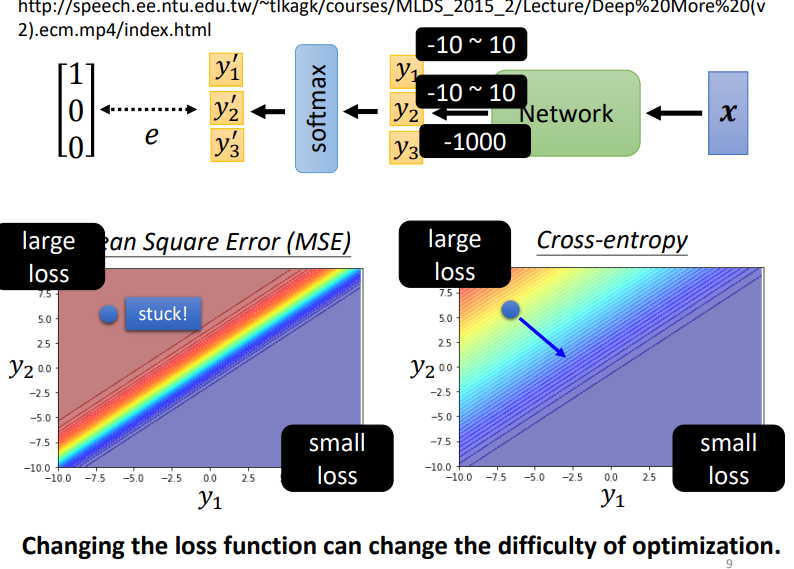
所以即使是loss function的定义,都可能影响training的效果.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号