2.1 类神经网路训练不起来怎么办 (一):局部最小值 (local minima) 与鞍点 (saddle point) - 李宏毅
1. When gradient is small
本小节主要讨论优化器造成的训练问题.
1.1 Critical Point(临界点)
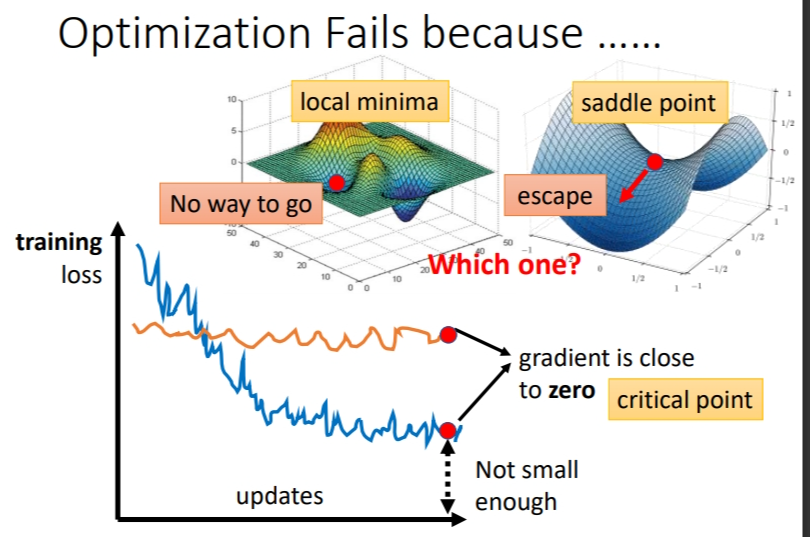
如果训练过程中经过很多个epoch后,loss还是不下降,那么可能是因为梯度(斜率)接近于 0,导致参数更新的步伐接近于0,所以参数无法进一步更新,loss也就降不下去.
这时或许有很多人会说陷入了局部最小值.但不是所有的导数为0的点都是局部最小值.saddle point(鞍点)同样是导数为0的点.所有导数为0的点统称为Critical Point(临界点).而临界点中的saddle point(鞍点)还能找到办法让loss降低,就是改变一下梯度下降的方向.
- local minima(局部极小值):如果是卡在local minima,那可能就没有路可以走了
- saddle point(鞍点):这个点在某一方向是最低点,但是在另一侧可能是最高点,卡在saddle point的话,saddle point旁边还是有路可以走的
- global minima(全局最小值):已经达成目标
![image]()
那么怎么判断临界点是哪种类型呢?
1.1.1 怎么判断临界点的类型
判断临界点需要看\(loss\)函数的形状.我们没办法完整地看function形状,但给定某组参数,在这组参数的\(loss\) \(function\)是有办法被写出来的.即利用泰勒展开式判断临界点的类型.

字数太多,直接放大佬的解释:
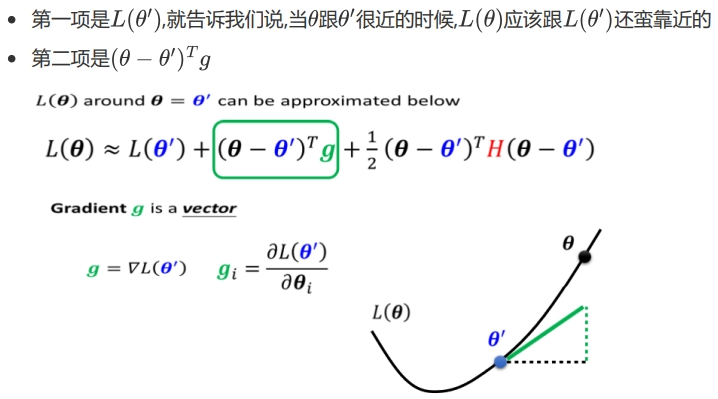
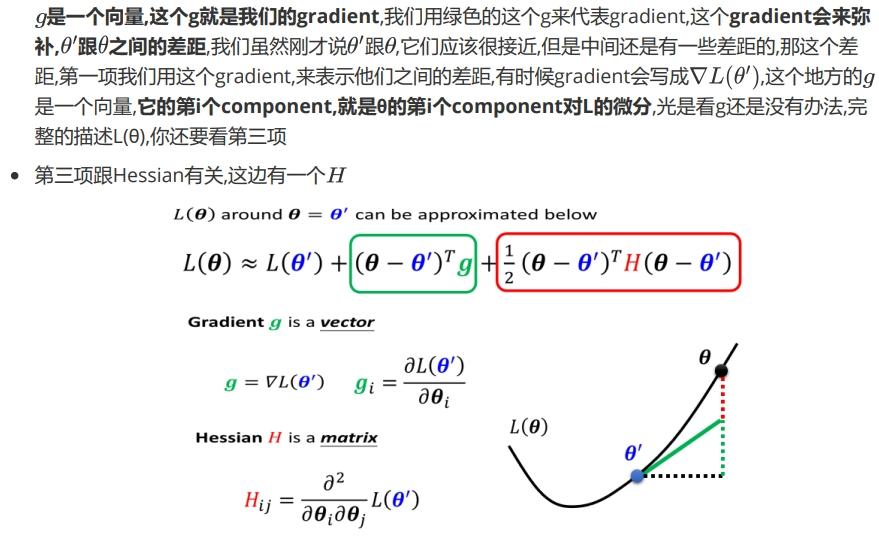

关于为什么是这也展开可以参考下这个Click.在 Critical point 附近时:第二项为0,只需考察H的特征值.
我们将\(\theta-\theta^{'}\)看作\(v\),\(v\)当然是一个向量.
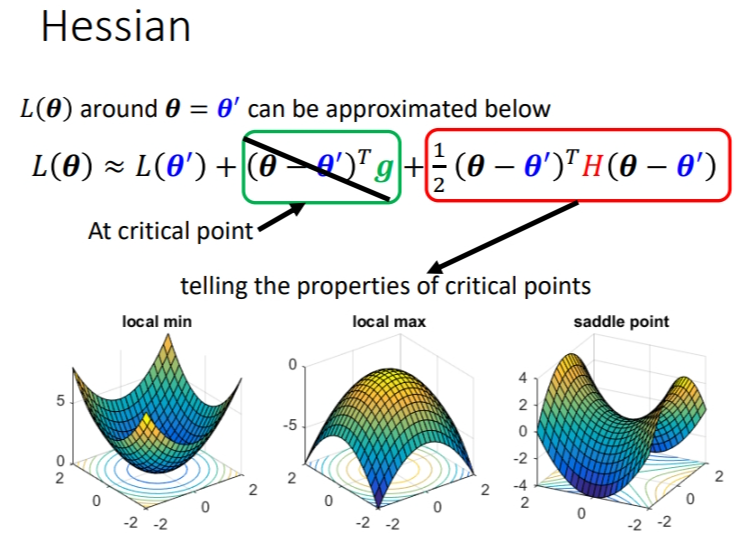
- 当\(\theta\)不论代任何值时,\(v^THv > 0\),即红色框里都\(>0\),那么在\(\theta^{'}\)附近,取任何值都比前者大,所以是局部最小值.
- 同理,当\(\theta\)不论代任何值时,\(v^THv < 0\),即红色框里都\(<0\),那么在\(\theta^{'}\)附近,取任何值都比前者小,所以是局部最大值.
- 当\(\theta\)不论代任何值时,\(v^THv\)有的\(>0\),有的\(<0\).此时是鞍点.
![image]()
但这个判断方法需要将所有的\(v\)代入测试,这是不切实际的.但有一种方法利用线性代数可以解决.

(1) 正定矩阵
下面是它的定义.它有一个特点是它的特征值全都是正的.

(2) 负定矩阵
下面是它的定义.它有一个特点是它的特征值全都是负数.

所以我们不需要计算所有的\(v^THv\),只需要计算\(H\)的特征值,就可以判断属于哪种情况.
如果不理解的话,可以看下面例子.假设模型只有两个神经元,可以表示为\(y = w_1w_2x\).我们可以画出\(w_1\)和\(w_2\)与\(loss\)的等高线图.可以发现很多Critical Point.中间的是是saddle point,从原点出发,左上和右下都是\(loss\)越来越大.往左下和右上是先减小后增大.
据说这个图是越亮,\(loss\)越大,越蓝越小.
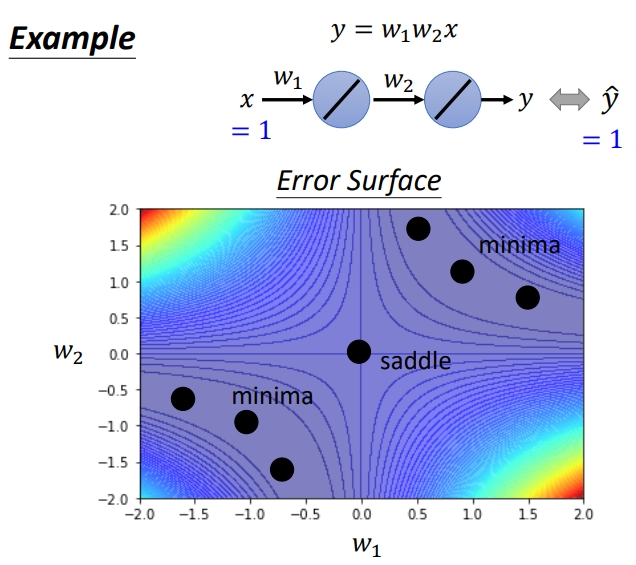
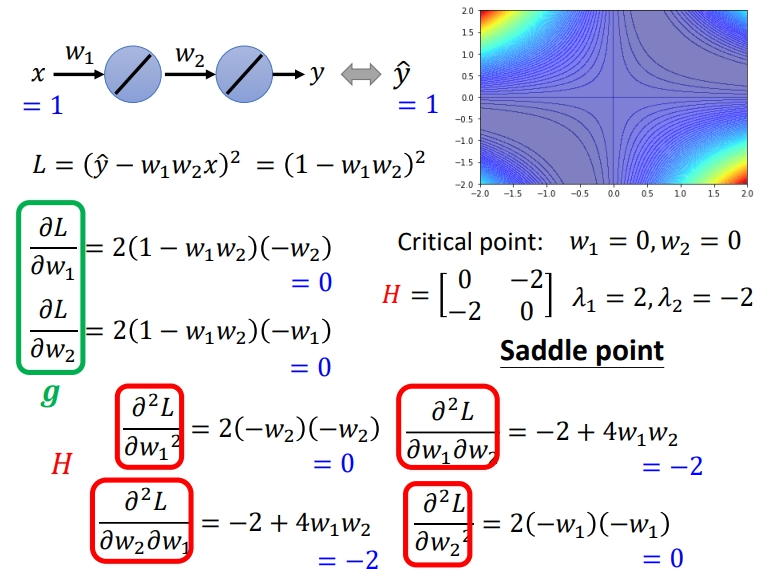
上面的图是枚举所有\(w\)的取值绘制,如果不暴力搜索,而是蛋蛋一个点,应该怎么判断是哪种Critical Point呢?举例\(x=1,y=1\)的样本点,可以求出梯度.当\(w_1=0,w_2=0\)的时候显然是一个Critical Point.接下来就是具体解它是哪种Critical Point.我们可以具体求出它的\(H\),并求出特征值.可以发现\(\lambda\)有正有负,所以是鞍点.
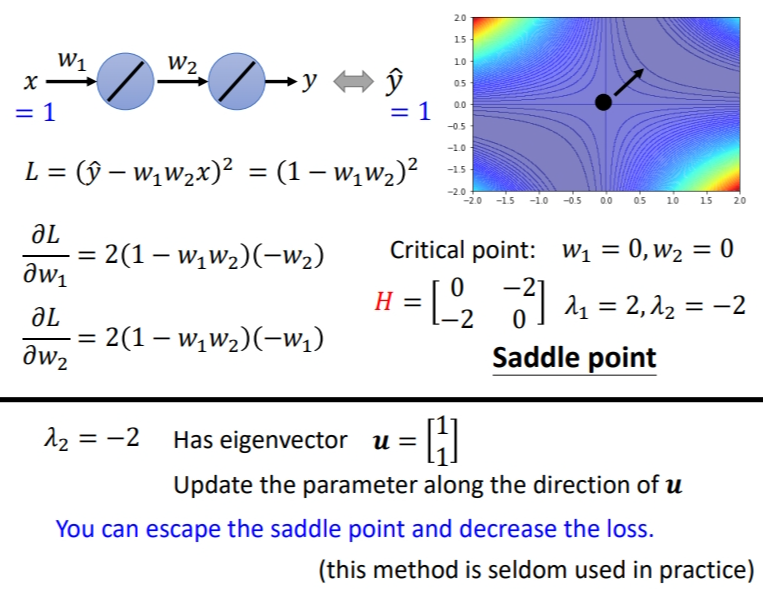
1.1.2 如果在鞍点怎么办
如果走到鞍点,可以利用\(H\)的特征向量确定参数的更新方向.这里利用的是特征值和特征向量的知识.由下图中间式子推导可知,当特征值小于 0,则红色框框里面的值始终小于 0,也就是说\(L(\theta) < L( \theta^′)\),这就是鞍点处\(loss\)能继续下降的方向。所以我们只要令\(v = u\) 即可,也就是\(\theta − \theta^′ = u\),\(\theta= \theta^′ + u\),此时\(\theta\)处的 L 比 \(\theta^{'}\) 处的 L要低。

因此,当梯度\(=0\)时,也不一定不能训练,只需要找到负数的特征值即可.
1.1.3 举例说明
还是刚刚那个例子,求出负的特征值对应的特征向量,沿着特征向量的方向更新参数就可以减低 loss。特征向量有无穷多个,取一个即可。
上面讲的利用泰勒展开式判断临界点类型,并用 H矩阵确定参数更新方向的方法。在实际中很少用到,因为二次微分和找特征值、特征向量,深度学习模型有很多参数,需要很大的运算量,不值得.
但除了这个方法,还有其他方法解决鞍点的问题,计算量比这个小一些.
1.2 local minima 和 saddle point 哪个比较常见
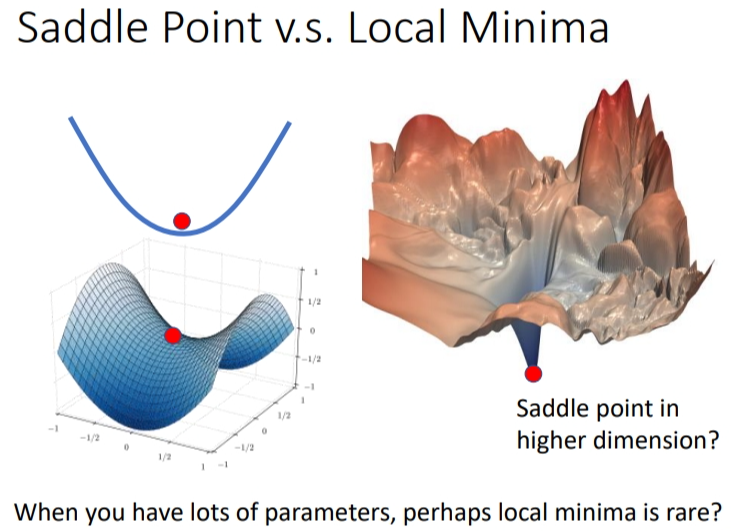
我们在二维空间看起来像 local minima的点,在三维空间只是一个鞍点.当我们网络参数越多,维度越多,低维的local minima在高维只是一个鞍点,因此就会有一个猜测:高维度空间本身就有很多路可以走,这导致它们local minima很少.
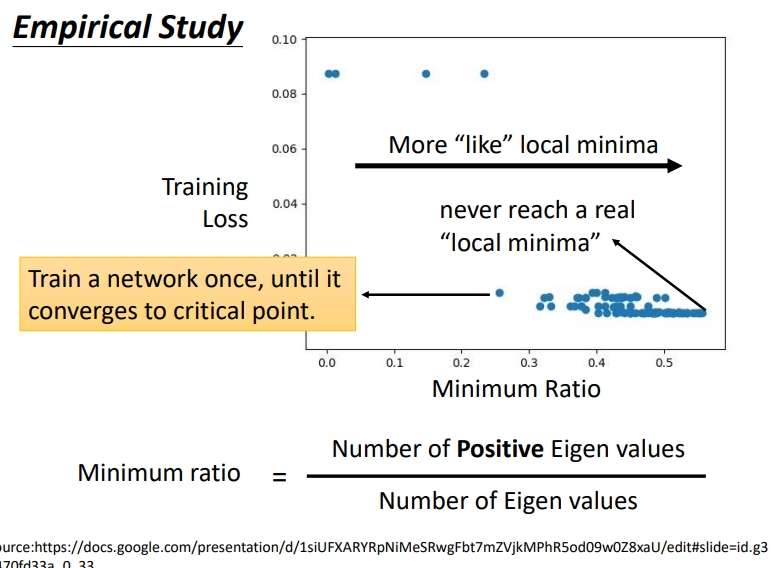
具体训练范例如下图所示,这是训练某一个network的结果,每一个点代表训练某个network训练完之后把它的 Hessian 拿出来进行计算.所以这边的每一个点都代表一个network.
纵轴代表 training 的时候的 loss,就是卡住的那个loss.很多时候,loss在还很高的时候就训练不动了,卡在critical point;很多时候 loss 可以降得很低才卡在 critical point
横轴的部分是minimum ratio(最小比率).minimum ratio是 eigen value 是正数的数目 / eigen value的总数目,如果所有的 eigen value 都是正的,代表我们的 critical point 是 local minima;如果有正有负代表 saddle point.(但是在实际操作中几乎找不到所有 eigen value 都是正的critical point).因为矩阵可能有多个特征值,所以用了ratio.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号