2. General Guidance - 李宏毅
1. Framework of ML
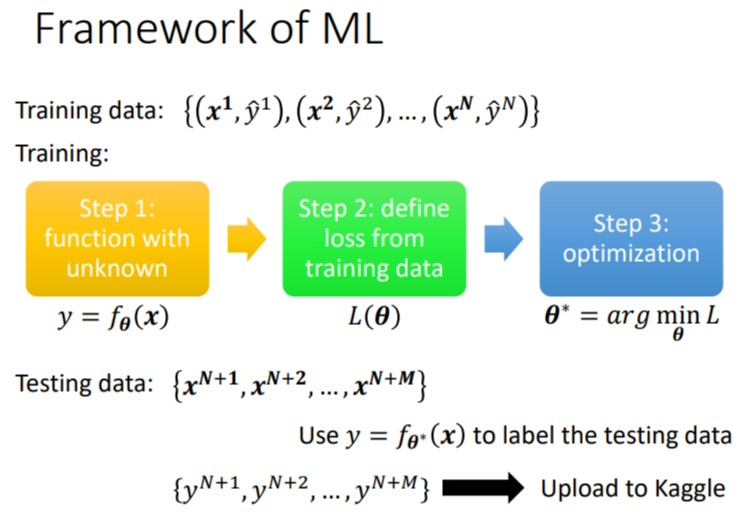
训练的过程之前已经讲过了,训练主要是三个步骤.
-
第一步,你要先写出一个有未知数的function,这个未知数都用\(\theta\)来代表一个Model裡面所有的未知函数,所以\(f_{\theta}(x)\)的意思就是说,我现在有一个function叫f(x),它里面有一些未知的参数,这些未知的参数表示成\(\theta\),它的input叫做x,这个input叫做feature.
-
第二步,你要定一个东西叫做loss,loss是一个function,这个loss的输入就是一组参数,去判断说这一组参数是好还是不好
-
第三步,你要解一个Optimization的problem,你要去找一个θ,这个θ可以让loss的值越小越好,可以让loss的值最小的那个\(\theta\),我们叫做\(\theta^*\)
有了\(\theta^*\)以后,那你就把它拿来用在测试集上,也就是你把\(\theta^*\)带入这些未知的参数,将输出的结果上传到kaggle.
但是训练总会有一些问题.训练完一次模型后,根据训练集的损失以及测试集的损失来确定网络需要进行模型改进还是优化函数改进.
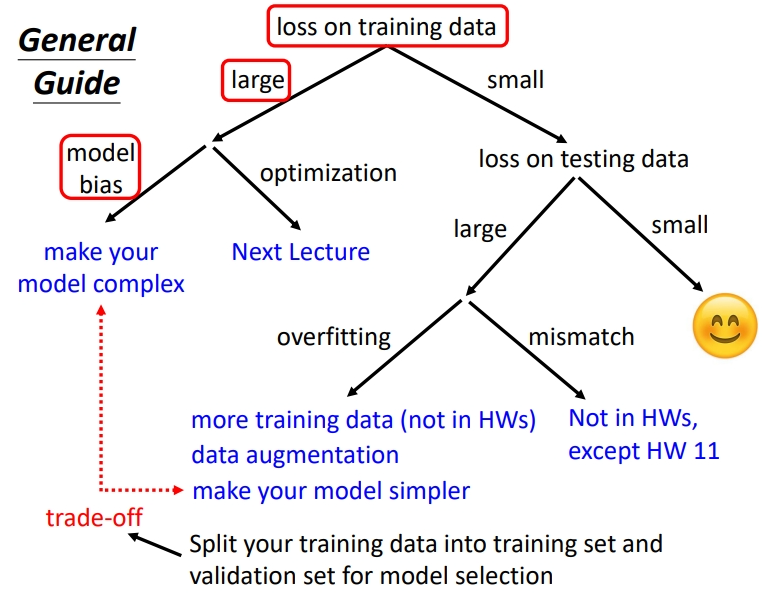
如果你觉得模型预测的结果不满意的话,第一件事情你要做的事情是,检查你的training data的loss,看看你的model在training data上面有没有学起来,再去看testing的结果。如果你发现你的training data的loss很大,显然它在训练集上面也没有训练好。有两个可能的原因,第一个可能是Model Bias(模型偏差),第二个是Optimization Issue(优化问题)
1.1 Model Bias
原因:适用的模型太简单,不足以让loss足够低(太简单的模型没法精确描述复杂的问题).也就是说在选用的模型组成的function set(函数集)中没有一个最优的function可以让 Loss 足够低.

解决方法:调整模型,让模型变复杂变得有弹性,使模型能够包含更多情况.使模型变复杂的方法:
- 使用更多的特征作为自变量.
- 加深神经网络,用到更多的神经元和层数.
1.2 Optimization Issue
在训练资料上的 loss 大有两种可能,一种是model bias,另一种是优化没有做到位.
Optimization Issue 是指我们猜测的含未知参数的模型是好的,里面包含能使 loss 低的可能,但是没有找到使 loss 低的最佳参数.优化问题就相当于针在海里,可是我们没捞着.最典型的就是 gradient descent 遇到了局部最小值,没有找到能使 loss 很小的参数.

1.3 如何区分 model bias 和 Optimization issue
遇到某一任务目标可以先跑一些比较小、比较浅的 network,或甚至用一些不是 deep learning 的方法(比较容易做Optimize的,避免出现优化失败的情况)
如果发现在这基础上增加复杂度后的层数深的\(model\)跟浅的 \(model\)比起来,深的model明明弹性更大更复杂,但训练集的\(Loss\)却没有办法比浅的model压得更低,那就代表optimization有问题.
以下面的实验结果图为例,单看左边在测试资料上的 loss 很大,很多人以为是overfitting,但实际上不是!因为还没有观察在训练资料上的 loss.右边的 56层神经网络在训练资料上的\(loss\)很大,是优化问题而不是 model bias问题,为什么?model bias 是因为模型太简单导致 loss 大,假如 56层是 model bias 的问题,那么比 56层更简单的 20层的 loss应该更大,因为 20层的弹性更小,更不能描述复杂问题,而56层只要前20层保持一致,后36层直接输出20层的结果就可以模拟20层模型.可是20层的 loss 比 56层的 loss要低,所以56层的网络是由于没有做好优化导致 loss 偏高。
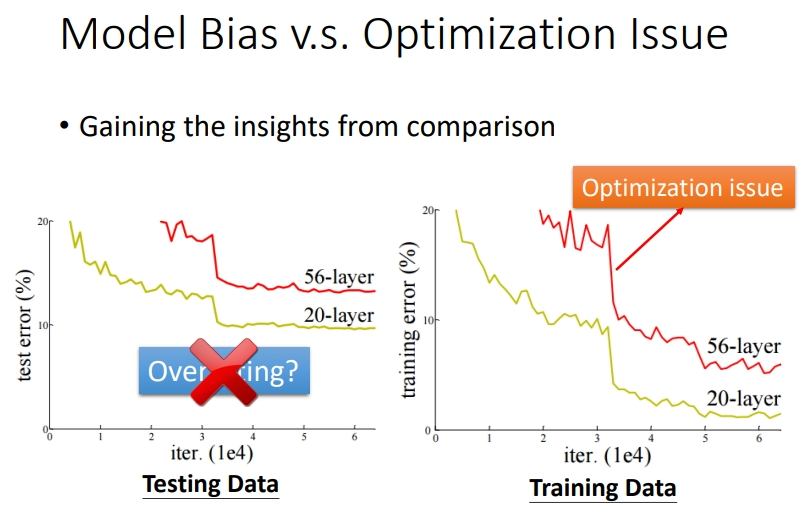
这个问题应该怎么解决呢?下小节就会讲解.
1.4 Overfitting(过拟合)
假设在 training data 的loss变小了之后,接下来可以来看 testing data loss,如果testing data loss也小,比strong baseline还要小,那训练就结束了.但是如果training data上面的loss小,testing data上的loss大,那可能就是真的遇到\(overfitting\)的问题。
表现形式:training的loss小,testing的loss大.极端情况进行解释原因:训练出的模型只是记住了训练集中的输入和输出的对应关系,对于未知的部分输出是一个随机的,这种情况下在训练集中的损失为0,测试集中的损失极高.

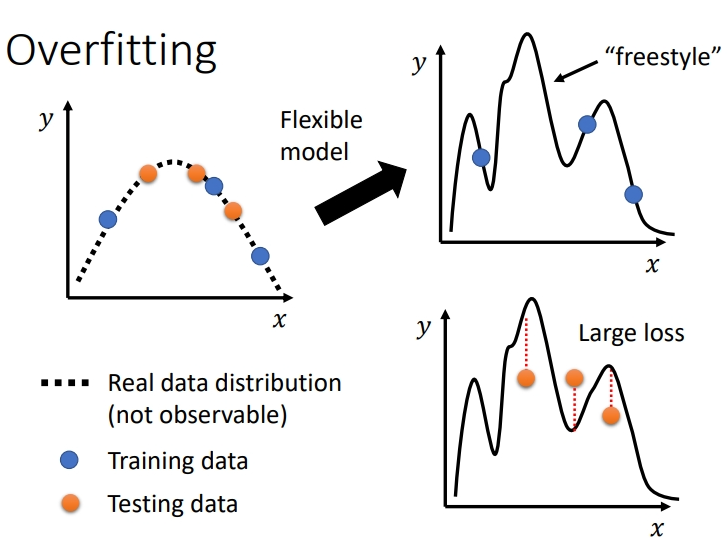
假设真实分布是一个二次函数,但我们通过训练资料并不知道是二次函数。我们用一个很复杂的函数去模拟,虽然该模型能很好地吻合训练资料的分布,但是该模型却并不符合真实分布。一旦我们将该模型用于测试资料上,就会产生很大的 loss(如曲线三)。过拟合的原因就是实验者为了逼近训练资料而拟合,眼睛里只有training loss 要小,导致使用了过于复杂的模型。

解决方式:
-
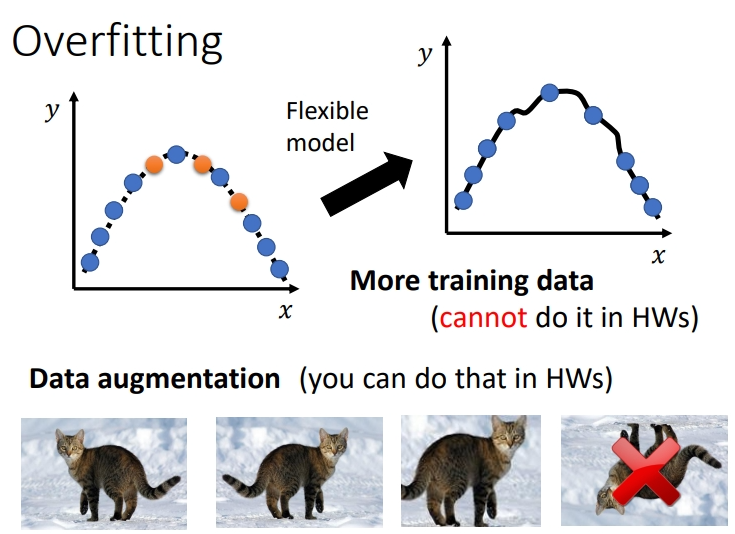
增加训练集:可以使用data augmentation的方式进行数据扩充,例如图像中的旋转、放缩等操作(上下颠倒的操作很有可能会造成数据在真实世界中的无意义,所以很少用,要根据你对资料的特性,对你现在要处理的问题的理解来选择合适的data augmentation的方式)
![image]()
-
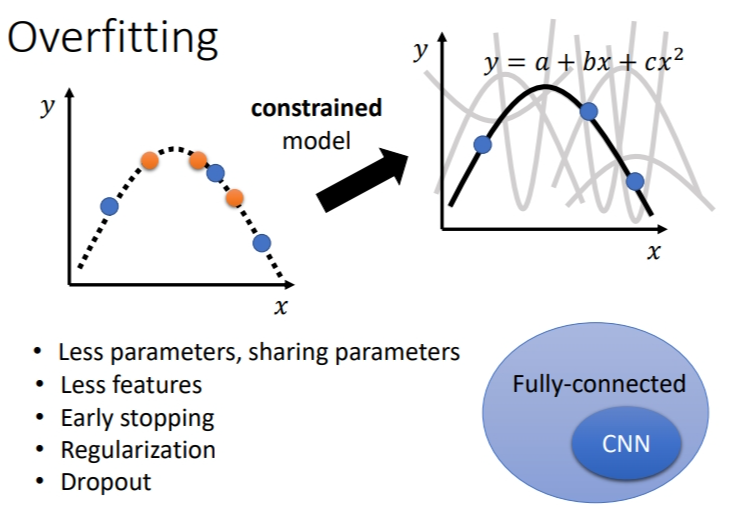
限制模型的弹性:有很多方法限制.
-
给较少的参数:如果是deep learning的话,就给它比较少的神经元的数目。本来每层一千个神经元,改成一百个神经元之类的;或者是你可以让 model 共享参数,让一些参数有一样的数值.
![image]()
-
使用较少的features.
-
Early stopping:训练设置提前结束的条件.(另还有Regularization正则化的方式)
-
Dropout:将部分神经元进行禁用.
![image]()

2. Bias-Complexity Trade-off——模型偏置与弹性
当模型复杂度增加时,training loss是一直降低的,但是 testing loss 是先下降再上升.当复杂度超过下图虚线处,就产生了过拟合,当复杂度远低于虚线处,就产生了 model bias 问题.所以模型复杂度最好是在虚线附近.
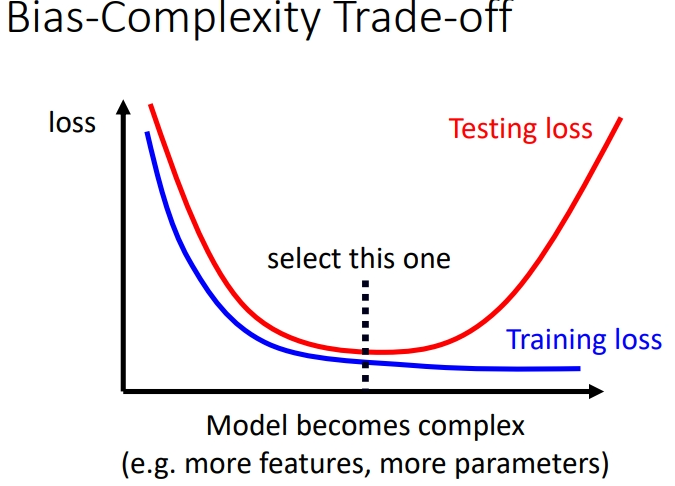
产生了model bias 问题就想增加模型复杂度,产生了overfitting 问题就想降低模型复杂度,这其中就存在一个权衡,那我们要怎么选择合适的模型,既不会太复杂也不会太简单?一个想法是将训练资料分成训练集和验证集,从而选择合适的模型.
可能有人会将\(Kaggle\)的\(public\)的测试集当作训练的好坏.但仍然拿之前极端的例子来说,如果模型在\(kaggle\)的public集上恰好\(random\)表现很好,到private集上就会悲剧了.

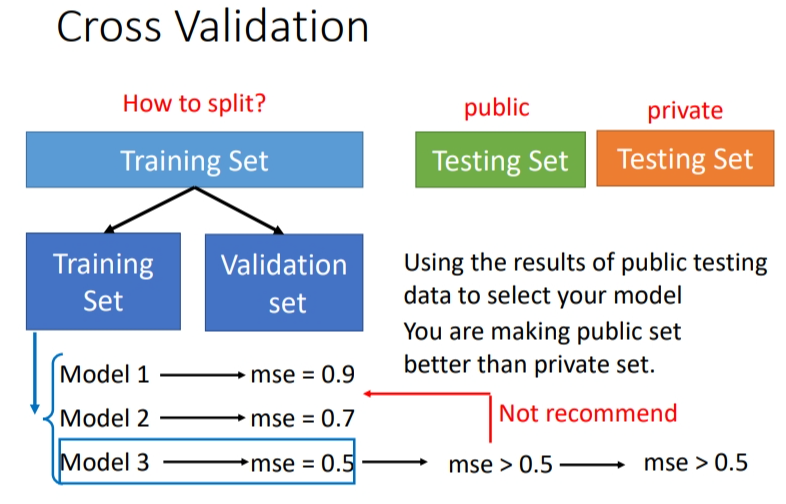
如何选出有较低testing-loss的模型?⇒ Cross Validation(交叉验证)
2.1 Cross Validation
方法:把Training的资料分成两半,一部分叫作 Training Set(训练集),一部分是Validation Set(验证集).比如,在这组数据里,有90%的资料放在 Training Set 里面,有10%的资料会被拿来做Validation Set.
在Training Set上训练出来的模型拿到 Validation Set 上面,衡量它们的 Loss 值,根据 Validation Set 计算出的数值从而挑选选用哪个模型,理想上不要管在public testing set上的结果,尽可能避免overfiting.
2.2 N-fold Cross Validation(N-重交叉验证)
到底要怎么划分训练集呢?这里可以使用N-fold Cross Validation方法.
- 先把训练集切成 N 等份,在上图例子里我们切成三等份.切完以后,拿其中一份当作 Validation Set,另外两份当 Training Set,然后要重复三次.
- 将组合后的三个 model,相同环境下,在 Training data set 和 Validation data set 上面通通跑一次。然后把这每个 model 在这三类数据集的结果都平均起来,看看哪个 model 计算出的结果最好
- 如果你用这三个fold(层)得出来的结果是 model 1 最好,便把 model 1 用在全部 Training Set 上,然后训练出来的模型再用在 Testing Set 上面.
![image]()

3. MisMatch —— 训练集跟测试集的分布是不一样的
mismatch 就是训练资料和测试资料有着不同的分布。简单地增加训练资料对这个问题是没有帮助的,增加资料只能降低 training loss 而不能降低 testing loss.因为两笔资料产生方式不同,就不能通过training data的规律去预测testing data的规律.

判断是否是\(mismatch\)的情况要看对数据集的理解.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号