
机器学习 吴恩达 第十五章 笔记
十五、推荐系统(Recommender Systems)
15.1 问题形式化
我们从一个例子开始定义推荐系统的问题:
假使我们是一个电影供应商,我们有 5 部电影和 4 个用户,我们要求用户为电影打分.
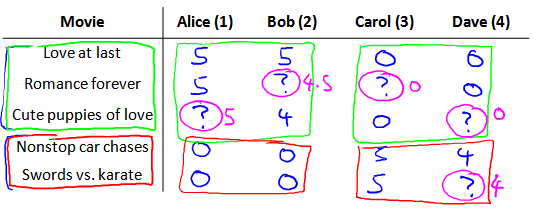
前三部电影是爱情片,后两部则是动作片,我们可以看出Alice和Bob似乎更倾向与爱情片,而 Carol 和 Dave 似乎更倾向与动作片.并且没有一个用户给所有的电影都打过分.我们希望构建一个算法来预测他们每个人可能会给他们没看过的电影打多少分,并以此作为推荐的依据.
下面引入一些标记:
- \(n_u\):用户的数量
- \(n_m\):电影的数量
- \(r(i,j)\):如果用户\(j\)给电影\(i\)评过分则 \(r(i,j) = 1\)
- \(y^{(i,j)}\):用户\(j\)给电影\(i\)的评分
- \(m_j\):用户\(j\)评过分的电影的总数
我们可以研制一个算法预测用户没看过电影的评分,然后将电影推荐给用户.
15.2 基于内容的推荐算法
本次介绍推荐系统的第一个方法:
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据是有关这些东西的特征.
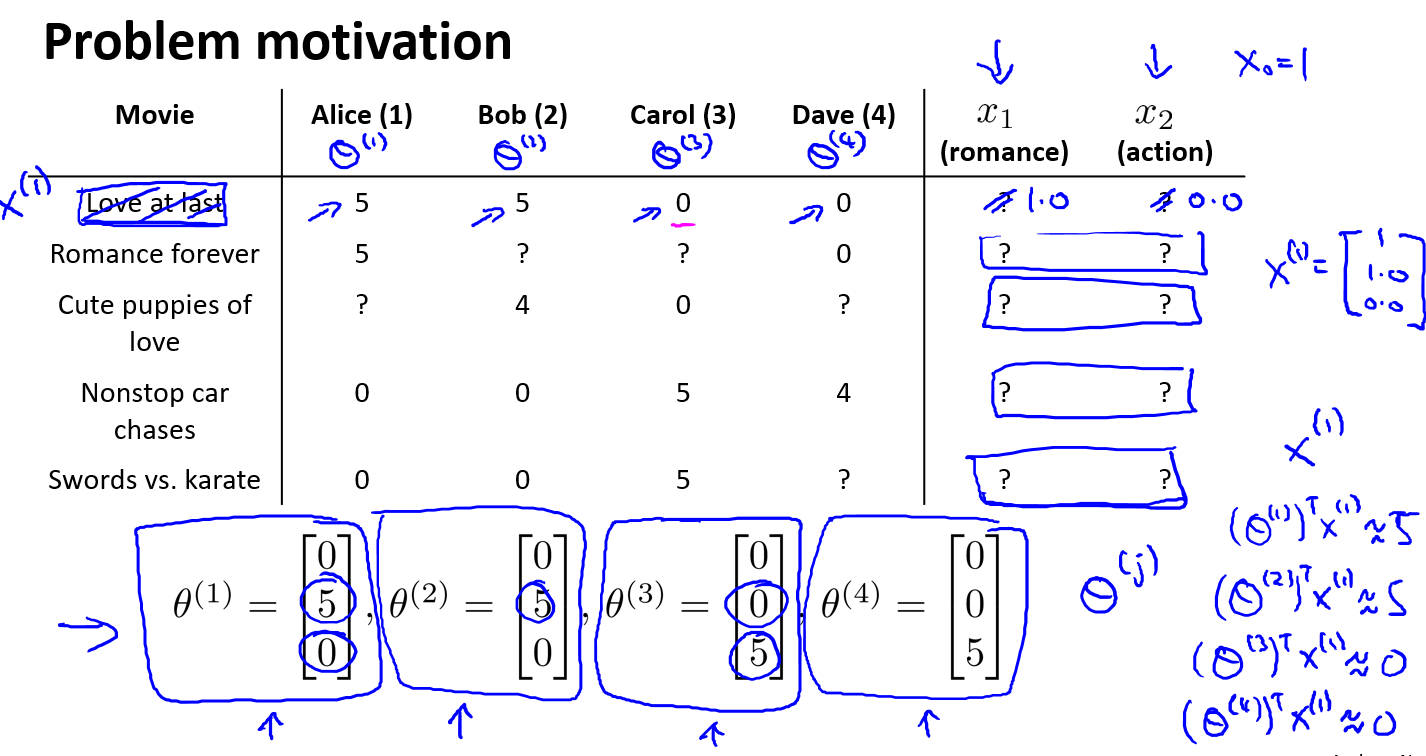
在我们的例子中,我们可以假设每部电影都有两个特征,如\(x_1\)代表电影的浪漫程度,\(x_2\)代表电影的动作程度:
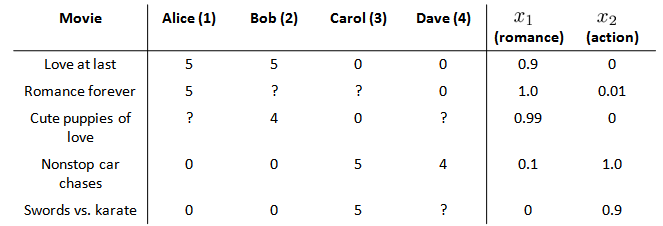
则每部电影都有一个特征向量,如\(x^{(1)}\)是第一部电影的特征向量为[0.9 0].\(n\)表示特征的数量,不包括\(x_0\)
下面我们要基于这些特征来构建一个推荐系统算法.假设我们采用线性回归模型,我们可以针对每一个用户都训练一个线性回归模型,如\(\theta^{(1)}\)是第一个用户的模型的参数.于是,我们有:

从上面看出,评分就是电影特征 \(\times\) 用户偏好.
其次,代价函数就是对于用户\(j\),求出所有他看过电影的实际评分与预测评分的差的和的平方,再加上正则项.在一般的线性回归模型中,误差项和正则项应该都是乘以\(\frac1{2m}\),在这里我们将\(m\)去掉.并且我们不对方差项\(\theta_0\)进行正则化处理.

上面的代价函数只是针对一个用户的,为了学习所有用户,我们将所有用户的代价函数求和.
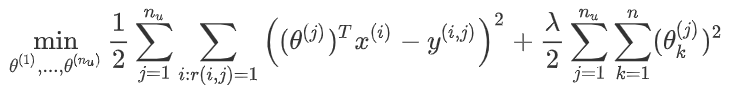
如果我们要用梯度下降法来求解最优解,我们计算代价函数的偏导数后得到梯度下降的更新公式为:

这个方法建立在我们用于电影特征的数据.
15.3 协同过滤
协同过滤算法可以自行学习要使用的特征.
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征.
那么是怎么学习的呢?假设我们已知用户的电影偏好,又知道用户对电影的评分.下面的\(\theta_1\)是第一个用户的偏好矩阵(第二个5的参数表示浪漫电影偏好),我们已知第一部评分是5,那么这部电影在浪漫特征值上就可能比较高.
对于给出所有的用户参数\(\theta^{j}\),学习\(x^{(i)}\),就要最小化下面的代价函数.


已知\(x\)可以求\(\theta\),已知\(\theta\)也可以求\(x\).我们最开始一般是设置\(\theta\)的初始值,然后求\(x\),再套娃优化\(\theta\).这样不断循环,这样可以得到较好的\(\theta\)和\(x\).(建立在有每位用户对数个电影进行评价,每个电影都有用户评价)
但是如果我们既没有用户的参数,也没有电影的特征,这两种方法都不可行了.协同过滤算法可以同时学习这两者.
15.4 协同过滤算法
按上节,我们需要不断循环算\(\theta\)和\(x\).这里有一个更好的方法,让我们不用不停计算\(\theta\)和\(x\).
协同过滤优化目标:
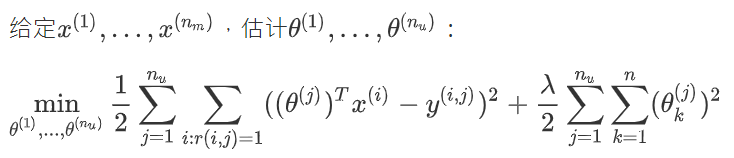
算法就是将他们结合起来:
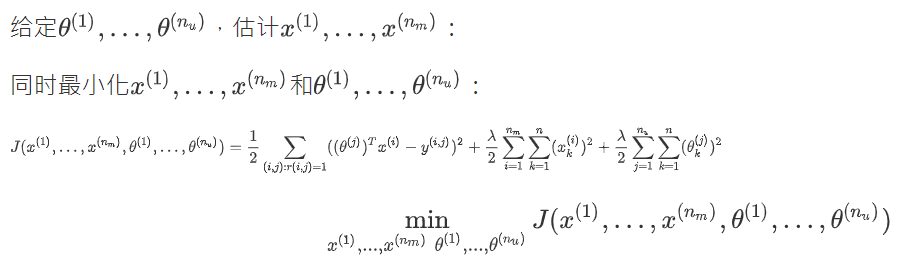
\(j:r(i,j)=1\)是对于每个用户\(j\),举例每个评价过的电影\(i\).\(i:r(i,j)=1\)表示对于每个电影i,举例所有对它评价的用户.而\((i,j):r(i,j)\)是每一个\(r(i,j) = 1\)的用户-电影求和.
新版本的协同过滤不需要来回折腾,而是仅仅使用上面的函数对\(\theta\)和\(x\)同时化简.顺带一提,以这种方式学习特征量\(x\),不需要设置\(x_0 =1\),让\(x\)保持\(n\)维,同样\(\theta\)也不需要\(\theta_0\).

再次强调,\(x,\theta\)都是n维
15.5 矢量化:低秩矩阵分解
本节我们会讲述协同过滤的向量化实现,再介绍使用该算法可以实现的功能.
举例子:
- 当给出一件产品时,你能否找到与之相关的其它产品.
- 一位用户最近看上一件产品,有没有其它相关的产品,你可以推荐给他.
我将要做的是:实现一种选择的方法,写出协同过滤算法的预测情况.我们有关于五部电影的数据集,我将要做的是,将这些用户的电影评分,进行分组并存到一个矩阵中.


推出评分:
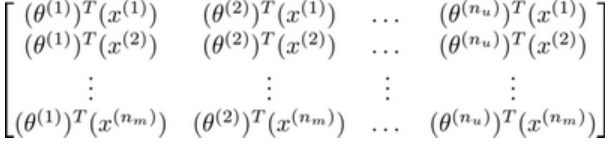
这个评分矩阵可以写出\(X\theta^T\):

这个协同过滤算法也称作低秩矩阵分解算法.因为\(X\theta^T\)在数学上也有低秩性质.低秩矩阵是表示行列具有相关性,比如\(A\)是\(m \times n\)矩阵,当\(r(A) < m,n\),则称为低秩矩阵.
现在既然你已经对特征参数向量进行了学习,那么我们就会有一个很方便的方法来度量两部电影之间的相似性.例如说:电影\(i\)有一个特征向量\(x^{(i)}\),你是否能找到一部不同的电影\(j\)与\(i\)相似?我们已知\(x^{(i)}\),当|| x{(i)}-x ||很小时,说明\(i\)与\(j\)很相似.

15.6 实施细节:均值规范化
为了了解均值归一化的作用,我们考虑这样一个例子,让我们来看下面的用户评分数据:
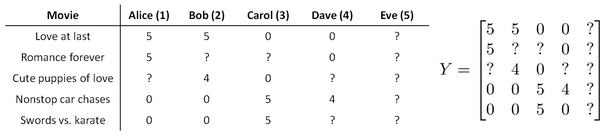
如果我们新增一个用户Eve,并且Eve没有为任何电影评分,那么我们以什么为依据为Eve推荐电影呢?
我们以最小化下式为前提,在无评分前提下,\(r(i,j)\)都等于0,蓝色线项完全不影响.所以影响\(\theta^5\)的只有最后一项.那么结果就是\(\theta^5 = [0 , 0]\),这样就会预计出\(Eve\)给所有电影0分,这样对推荐是没有什么帮助的.但均值归一化可以帮助我们解决这个问题.
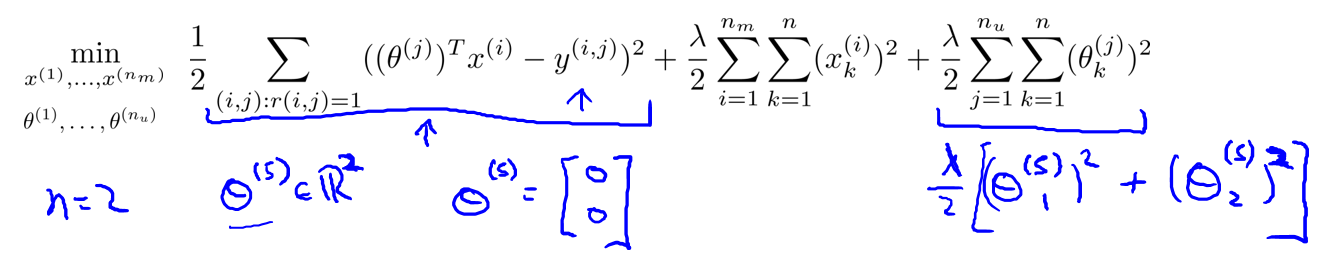
我们首先需要对结果Y矩阵进行均值归一化处理,将每一个用户对某一部电影的评分减去所有用户对该电影评分的平均值,使得电影评分的均值归一化:
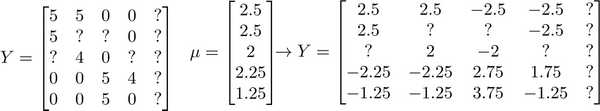
然后我们利用这个新的\(Y\)矩阵来训练算法,学习参数\(\theta\)和\(X\).如果我们要用新训练出的算法来预测评分,则需要将平均值重新加回去,预测\((\theta^{(j)})^Tx^{(i)}+\mu_i\).对于Eve,我们的新模型会认为她给每部电影的评分都是该电影的平均分.
可能有人问为什么不直接给\(Eve\)设均值,我们归一化是统一处理所有数据,不需要特别找没有评分的用户.
