机器学习 吴恩达 第十三章 笔记
十三、降维(Dimensionality Reduction)
13.1 目标一:数据压缩
本节讨论第二类无监督学习问题,降维.有几个不同的的原因使你可能想要做降维,一是数据压缩.数据压缩不仅允许我们压缩数据,从而使用较少的计算机内存或磁盘空间,它也让我们加快我们的学习算法.
那么,什么是降维?假设我们收集了一些数据,它有很多特征,这里只画出其中两个特征.假设我们未知两个的特征:\(x_1\),某物体的厘米长度;\(x_2\),同一物体的英寸长度.可以看出这两个特征是冗余的,我们需要将数据从二维降到一维.
再举一个例子:将数据从三维降至二维,这个例子中我们要将一个三维的特征向量降至一个二维的特征向量.过程是与上面类似的,我们将三维向量投射到一个二维的平面上(二维到一维就是投射到一个直线上),强迫使得所有的数据都在同一个平面上,降至二维的特征向量.
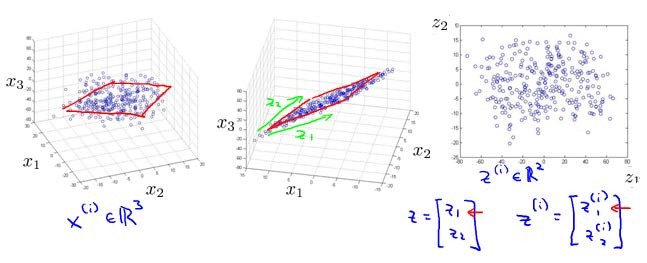
降维的首要条件是需要降维的特征有相关性.这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维.
13.2 目标二:数据可视化
本节讲述降维的第二个目的:数据可视化.
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等).如果要将这个50维的数据可视化是不可能的.使用降维的方法将其降至2维,我们便可以将其可视化了.
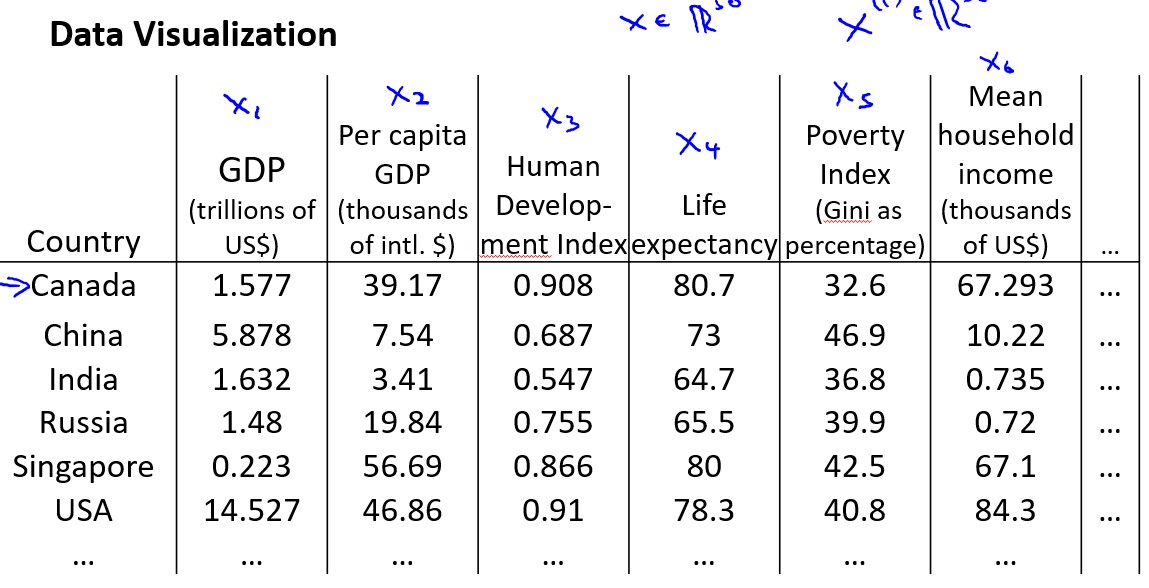
我们将50维特征降为\(z_1\)和\(z_2\).
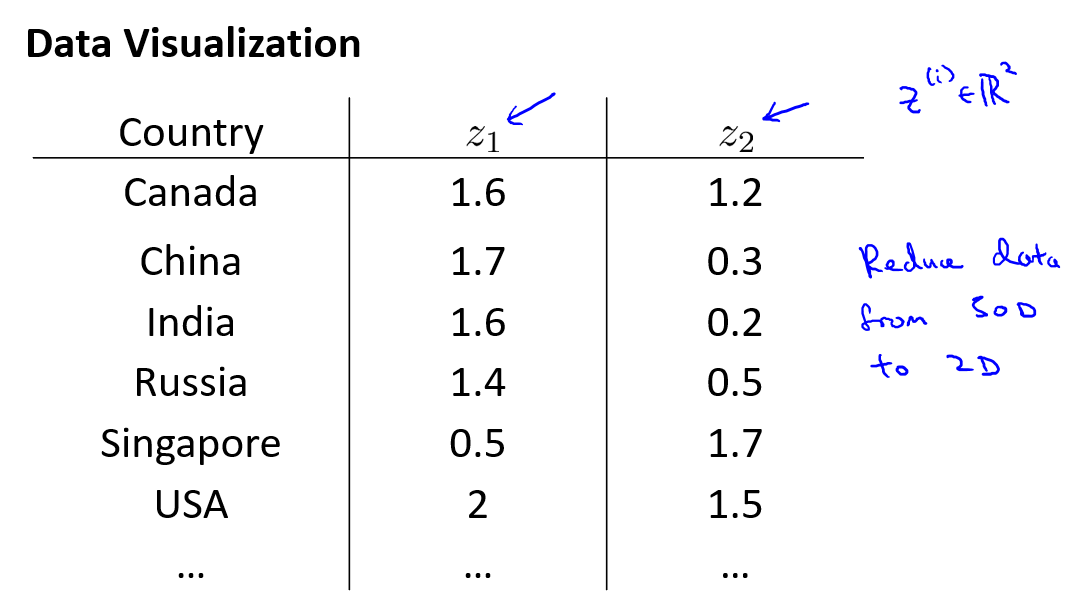
这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了.
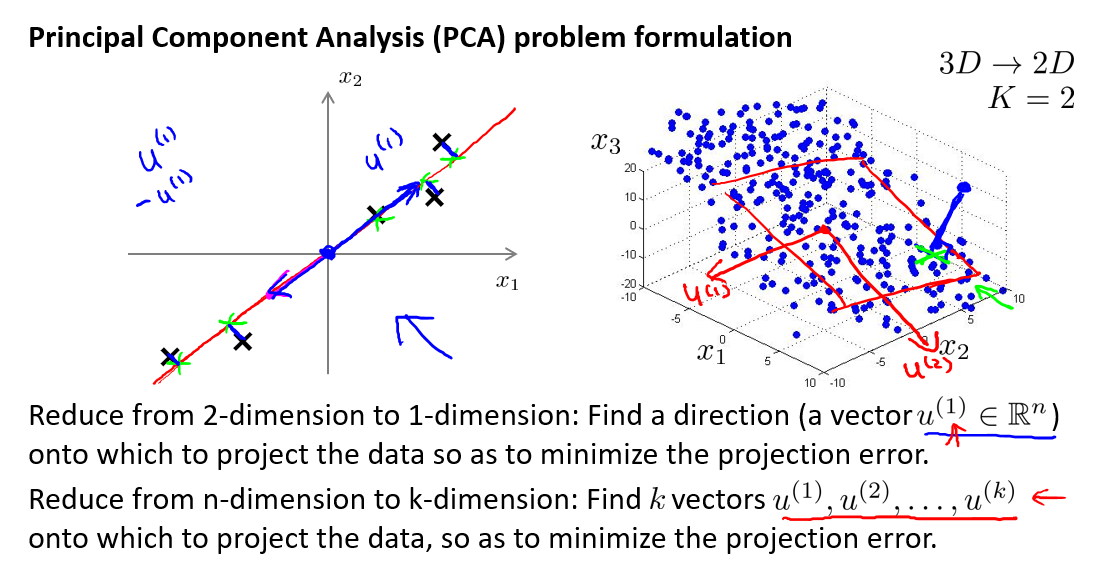
13.3 主成分分析问题
主成分分析(PCA)是最常见的降维算法.
PCA就是要找坐标系,使得投影点损失最小(保留信息最多),也就是投影点越分散越好(方差最大)
假设我们有样本数据集如下所示:
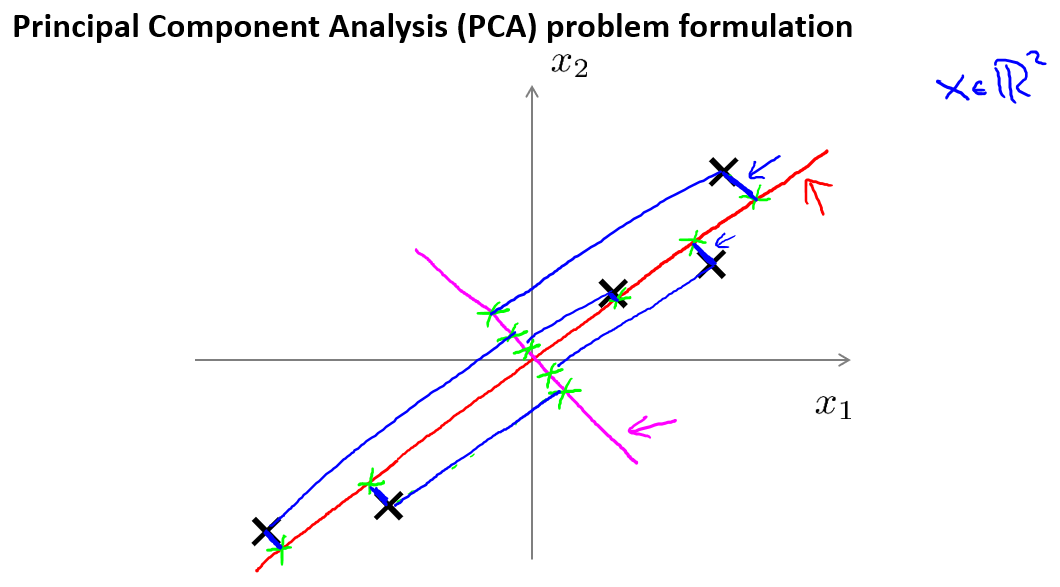
现在,我们要将二维降至一维(找到一条能将数据投影到上面的直线),在上图中,我们将数据投影到红线处.同时可以发现黑色点到投影直线的距离很短(蓝色线),这实际是PCA的思想.在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差(蓝色线)能尽可能地小.另外,在进行PCA之前,我们要做的是进行均值归一化和特征规范化,使得均值为0,且数值在可比较范围内.
PCA给出的直线方向无关紧要,最重要的是找到直线
更常见的是将\(n\)维数据降至\(k\)维,目标是找到向量\(u^{(1)},u^{(2)},...,u^{(k)}\)使得总的投射误差最小.
最后,我们看上面的第一幅图,可以发现画的线很像线性回归.主成分分析与线性回归是两种不同的算法.主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差.线性回归的目的是预测结果,而主成分分析不作任何预测.
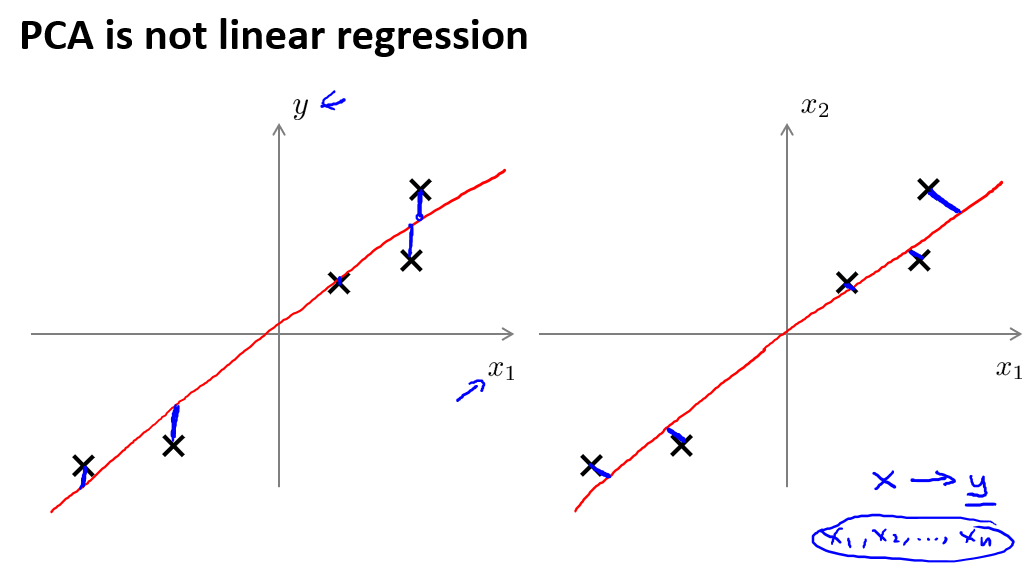
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影).

13.4 主成分分析算法
PCA减少\(n\)维到\(k\)维:
(1) 均值归一化.我们需要计算出所有特征的均值,然后令\(x_j=x_j-u_j\).如果特征是在不同的数量级上,我们还需要将其除以标准差\(\sigma^2\).(这样有利于更好地寻找投影的方向)
(2) 计算协方差矩阵(covariance matrix)\(\sum\):\(\sum = \frac1m\sum_{i=1}^{m}(x^{(i)})(x^{(i)})^T\).
协方差矩阵满足正定特征的性质:特征向量都是正数
(3) 计算协方差矩阵\(\sum\)的特征向量(eigenvectors):
在 Octave 里我们可以利用奇异值分解(singular value decomposition)来求解[U, S, V]= svd(sigma).顺带一提,这个Sigma会是一个nxn的矩阵,因为\(x^{(i)}\)是\(n \times 1\)的矩阵

上式中的\(U(n\times n)\)是一个具有与数据之间最小投射误差的方向向量构成的矩阵.如果我们希望将数据从\(n\)维下降到\(k\)维,我们只需要从\(U\)中选取前\(k\)个向量,获得一个\(n \times k\)维度的矩阵,我们用\(U_{reduce}\).表示,然后通过如下计算获得要求的新特征向量\(z^{(i)} = U_{reduce}^T x^{(i)}\) .
其中\(x\)是\(n \times 1\)维不需要\(x_0\),因此结果为\(k\times1\)维.
我们不对方差特征进行处理
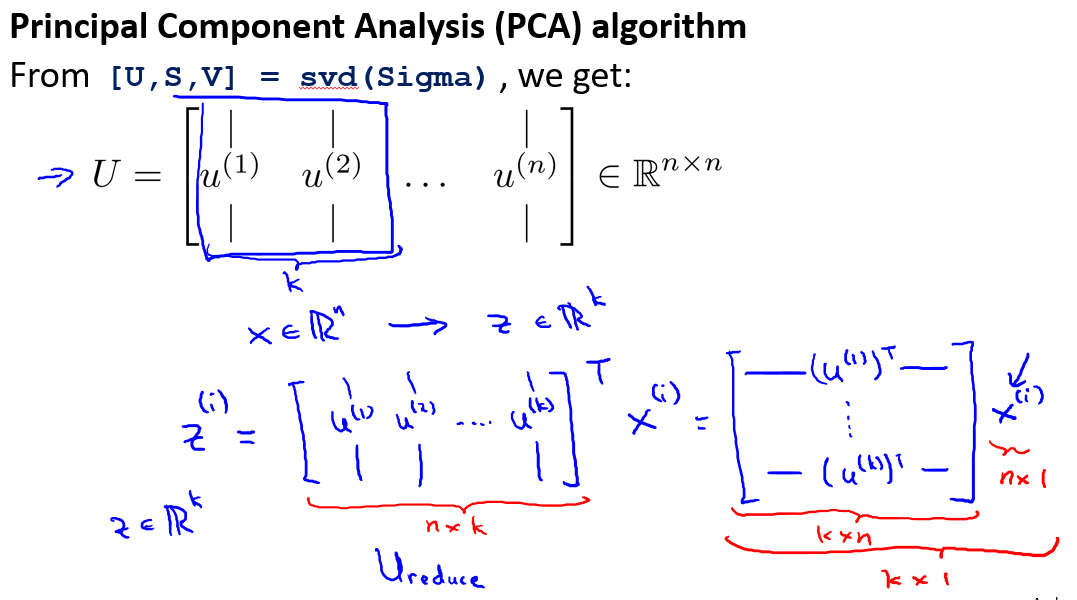
我们可能不理解协方差公式的\(\sum\),实际是累加的结果,\(X^{(1)} \times (X^{(1)})^T\)累加到\(X^{(n}\).
这里的推导建议看b站视频:用最直观的方式告诉你:什么是主成分分析PCA
PCA的缺点是离群点对向量方向影响很大.
13.5 压缩重现
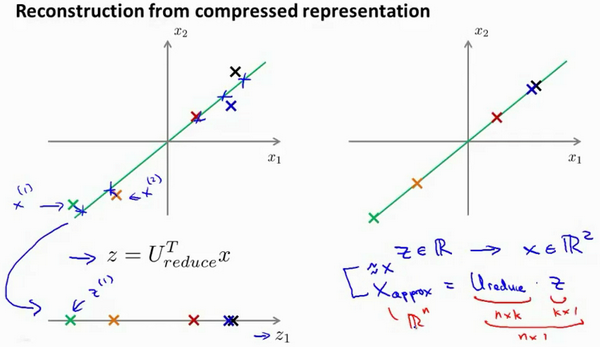
PCA是一个压缩算法,既然可以将\(n\)维压缩至\(k\)维,也可以将\(k\)维回到原来的\(n\)维.
假设有这样一个样本\(x^{(i)}\),我们做的是,我们把这些样本投射到图中这个一维平面.给定一个点\(z^{(1)}\),我们怎么能回去这个原始的二维空间呢?\(x\)为2维,\(z\)为1维,\(z = U_{reduce}^Tx\),\(x_{appox} = U_{reduce} z\),\(x_{appox} ≈ x\).
在奇异值分解中,有\(UU^T = E\)
约等于是因为压缩是损失数据.
酉矩阵是其共轭矩阵恰好等于逆矩阵
13.6 选择主成分的数量
本节讨论如何选择\(k\),也就是低维度的维数.为了介绍这个,先解释一下下面的概念.
PCA的目的是最小化\(\frac1m \sum_{i=1}{m} || x^{(i)} -x_{appox}^{(i)}||\).
训练集的方差为:\(\frac1m\sum_{i=1}{m}|| x^{(i)}||^2\),它显示了训练集\(x\)与\((0,0)\)的距离.
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的\(k\)

大多数人讨论选择\(k\)实际是讨论右边的概率选择.如果我们希望这个比例小于1%,就意味着原本数据的差异有99%都保留下来了(一组数据差异越大,越能包含更多的信息).如果我们选择保留95%的差异,便能非常显著地降低模型中特征的维度了(k越大,分子越小).
95%~99%都是选择比较多的.
那么如何实现它呢?我们可以先令\(k=1\),然后计算\(U_{reduce},z^{(1)}\)等,检测是否满足等式.不符合就再令\(k=2\)...

但上面左侧的方法效率不高,调用"svd"函数的时候,我们获得三个参数:[U, S, V] = svd(sigma).其中的\(S\)是一个\(n \times n\)的矩阵.只有对角线上有值,而其它单元都是0.因此,当得到一个\(k\),我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
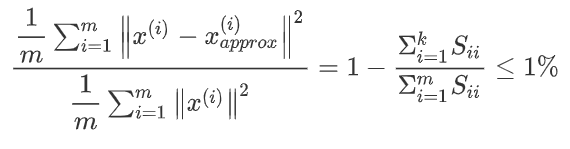
总结一下,最后步骤如下:

红色圈出来的字可以表示你的\(k\)选得好不好.
13.7 主成分分析法的应用建议
本节讲述如何应用PCA.
假使我们正在针对多张100×100像素的图片(监督学习问题)进行某个计算机视觉的机器学习,即总共有10000 个特征.

第一步就是去掉标签\(y\),给\(x\)进行PCA降维至1000维.因此新训练集就变成了\((z^{(1)},y^{(1)})\).
第二步,对训练集运行学习算法
在预测时,采用之前学习而来的\(U_{redece}\)将输入的特征\(x\)转换成特征向量,然后再进行预测\(y\).
注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的\(U_{reduce}\)
虽然这里举的是减到1000维的例子,可能有人觉得不切实际,但实际上大多数情况我们能减少到\(\frac{1}{10} \~ \frac{1}{5}\).
错误的主要成分分析情况:一个常见错误使用主要成分分析的情况是,将其用于减少过拟合(减少了特征的数量).这样做非常不好,不如尝试正则化处理.原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量(\(y\))有关的信息,因此可能会丢失非常重要的特征(\(X\)与\(y\)的关系).然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据.

另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号