机器学习 吴恩达 第八章 笔记
八、神经网络的学习(Neural Networks: Learning)
在本节,我们学习一个新的神经网络算法.它能在给定训练集的同时,为神经网络拟合参数.与其他算法一样,我们从代价函数开始.
8.1 代价函数
首先引入一些便于稍后讨论的新标记方法:
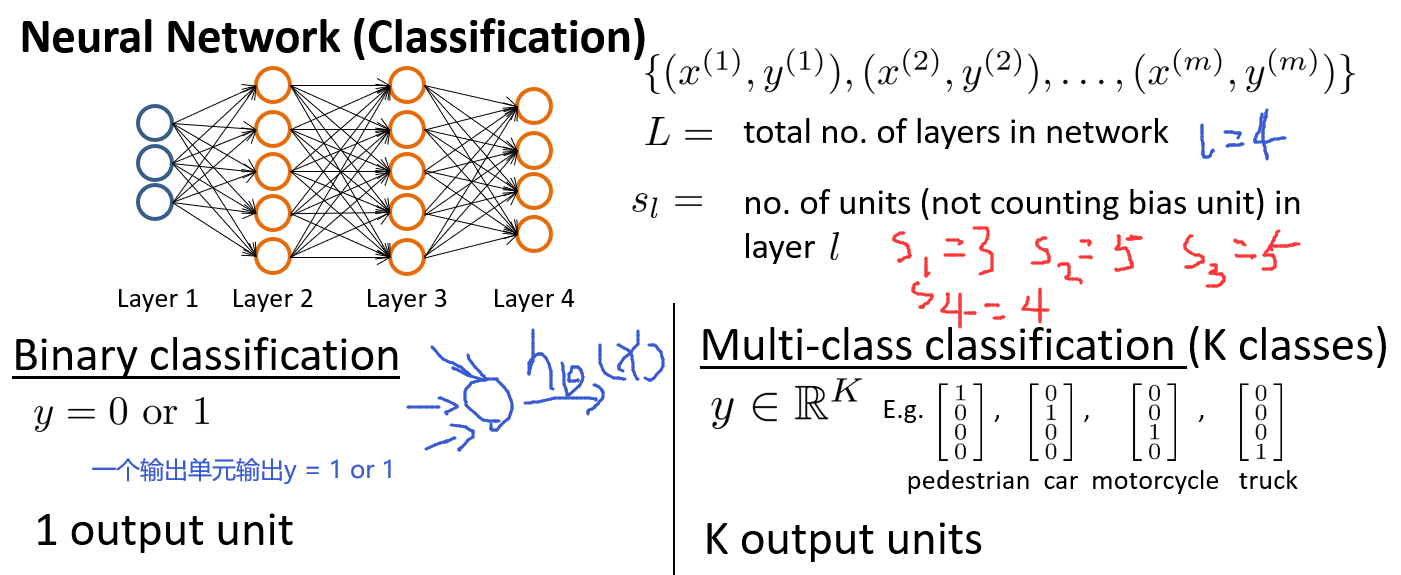
假设神经网络的训练样本有\(m\)个,每个包含一组输入\(x\)和一组输出信号\(y\),\(L\)表示神经网络层数,\(s_l\)表示第\(l\)层的单元(神经元)数,但不包括偏差单元,\(S_L\)(因为\(L\)=4)代表最后一层中处理单元的个数.
将神经网络的分类定义为两种情况:二类分类和多类分类.
现在来为我们的神经网络定义代价函数.我们回顾逻辑回归问题中我们的代价函数为:
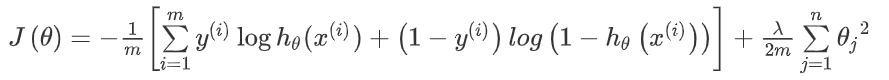
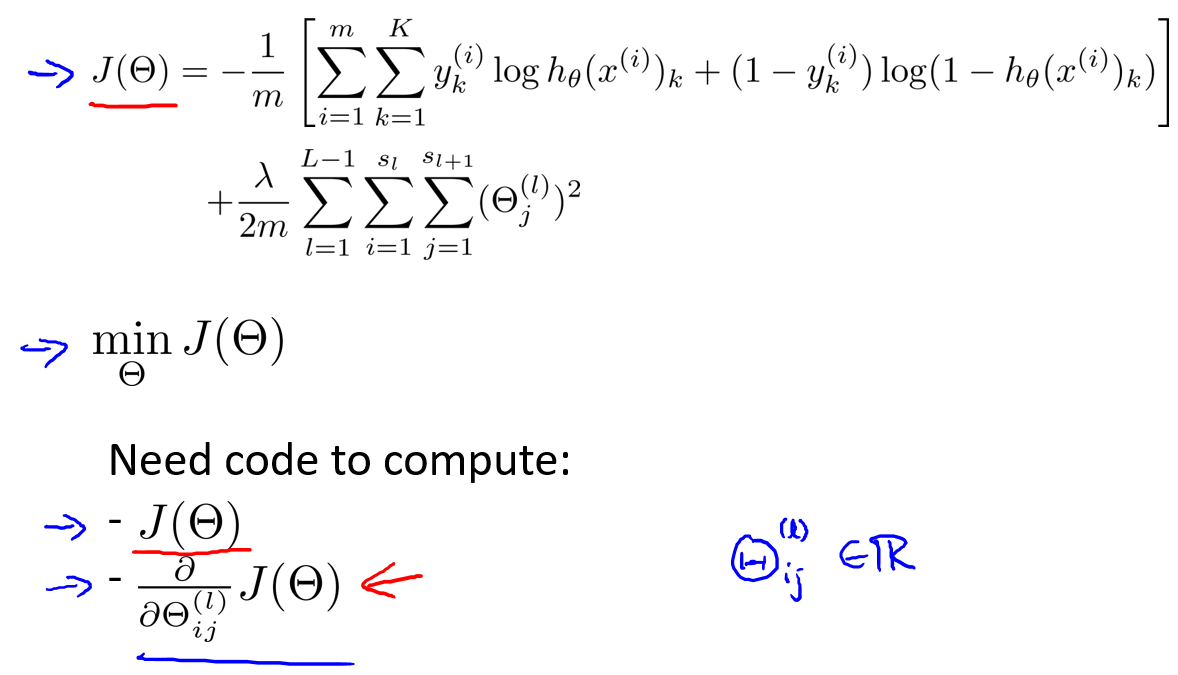
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量.但是在神经网络中,我们可以有很多输出变量,我们的\(h_{\theta}(x)\)是一个维度为\(K\)的向量,并且我们训练集中的因变量也是同样维度的一个向量.因此我们的代价函数会比逻辑回归更加复杂一些,为:
\(h_{\theta}(x) \in R^K\),并且

因为我们比逻辑回归问题多了\(k-1\)个分类器(输出).所以需要\(\sum_{k=1}^k\).代价函数的第二项类似正则化的代价,不需要算偏差值的项的代价(也就是\(i=0\)的\(\theta\)).
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出\(K\)个预测.基本上我们可以利用循环,对每一行特征都预测\(K\)个不同的结果.然后在利用循环在\(K\)个猜测里选可能性最高的那一个.将其与\(y\)的实际数据比较.
正则化的那一项只是排除了每一层\(\theta_0\)后,每一层的\(\theta\)矩阵的和.最里层的循环\(j\)循环所有的行(由\(s_{l+1}\)层的激活单元数决定).请注意不是\(s_l+1\).循环\(i\)则循环所有的列,由该层(\(s_l\)层)的激活单元数所决定.即:\(h_{\theta}(x)\)与真实值之间的距离为每个样本-每个类输出的加和,对参数进行regularization的bias项处理所有参数的平方和.
同样,这个代价函数就算计入了\(\theta_0\)也不会与原来的有较大差别.但是我们更多采用不计入的规则.
8.2 反向传播算法
本节我们讲述如何最小化神经网络的代价函数的方法.
下面是我们的代价函数,我们要做的就是找到参数\(\theta\)以此最小化代价函数.为了使用梯度下降或者其他优化算法,我们需要代码计算\(J(\theta)\)和它的偏导数.显然\(\theta\)在每层都是一个矩阵,我们要对每一个进行偏导.
计算成本函数只需要上面的公式,所以本节注重偏导数计算.
我们从样本集中只有一个样本的情况开始说起:

而神经网络是一个四层的神经网络,其中\(K = 4,S_L=4,L=4\),上面是我们使用的前向传播算法.为了计算代价函数的偏导数,我们需要使用一种叫反向传播的算法.
反向传播算法,直观上来说,就是对每一个结点计算误差\(\delta_j^{(l)}\),其中j表示第\(j\)个结点,而l表示第\(l\)层.
以下图为例,我们从最后一层的误差开始计算,误差是激活单元的预测(\(a^{(4)}\))与实际值\(y^k\)之间的误差.我们用\(\delta\)来表示误差,则:\(\delta^{(4)} = a^{(4)} - y\)(这里都是向量).
我们这里补充一下吴老师没讲的定义:
我们利用这个误差值来计算前一层的误差:
其中,\(g'(z^{(3)})\)是S形导数的求导.我们通过推导可得\(g'(z^{(3)})) = a^{(3)} \times (1-a^{(3)})\),而\((\theta^{(3)})^T\delta^{(4)}\)是权重导致的误差的和.下一步是继续计算第二层的误差:
后面的第一层就不用算了,因为第一层是输入变量,不存在误差.我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了.

假设\(\lambda = 0\),即我们不做任何正则化处理时有(我们会在后面完善正则化的细节):
重要的是清楚地知道上面式子中上下标的含义:
- \(l\)代表目前所计算的是第几层.
- \(j\)代表目前计算层中的激活单元的下标,也将是下一层的第\(j\)个输出变量的下标.
- \(i\)代表下一层中误差单元的下标,是受到权重矩阵中第\(i\)行影响的下一层中的误差单元的下标.
现在汇总起来考虑,假使我们训练集有\(m\)个样本.
我们首先要做的就是设置\(\delta_{ij}^{(l)} = 0\),请注意\(\Delta\)就是大写的\(\delta\),并且这些\(\Delta\)会慢慢累加到用来计算偏导.
接下来遍历我们的训练集,然后设置\(a^{(i)} = x^{(i)}\)(\(a\)表示激活函数),然后执行前向传播,算出所有层的\(a^{(l)}\),再计算出最后一层的误差\(y^{(i)}\),执行反向传播,算出所有层的误差,最后用
来累计我们计算的偏导数项.请注意,\(\Delta_{ij}^{(l)}\)表示第\(l\)层的第 \(i\)个激活单元受到第\(j\)个参数影响而导致的误差.

在求出了\(\Delta_{ij}^{(l)}\)后,我们便可以计算代价函数的偏导数了,计算方法如下:
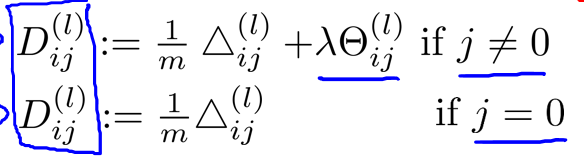
当我们计算出了\(D_{ij}^{(l)}\),那刚好是代价函数对\(\theta_{ij}^{(l)}\)的偏导.这样我们就能使用梯度下降或者其他优化算法.
理解完全看不懂,这里有两篇详细的推导,建议看:
(1) 基本解释了每一个问题,这个有个问题是它的代价函数是没有计入\(-\frac1m\)的负号的,但是(2)计入了,计算结果还是一致.所以最后\(D_{ij}\)的\(\frac1m\)没有负号(个人理解).
(2) 配合上面的看
还有我个人也和(1)同感,认为\(D_{ij}\)的式子有点问题.我个人认为正确的式子如下,这样才符合正则化求导后的式子(或者由于除不除都是一个让你自己调的参数,所以就合并到一起考虑了):
8.3 理解反向传播
&esmp; 要理解反向传播,我们必须先理解前向传播:
我们必须理解这些符号,比如\(z\)是某一层的输入,\(a\)是某一层的输出.\(a = g(z)\)
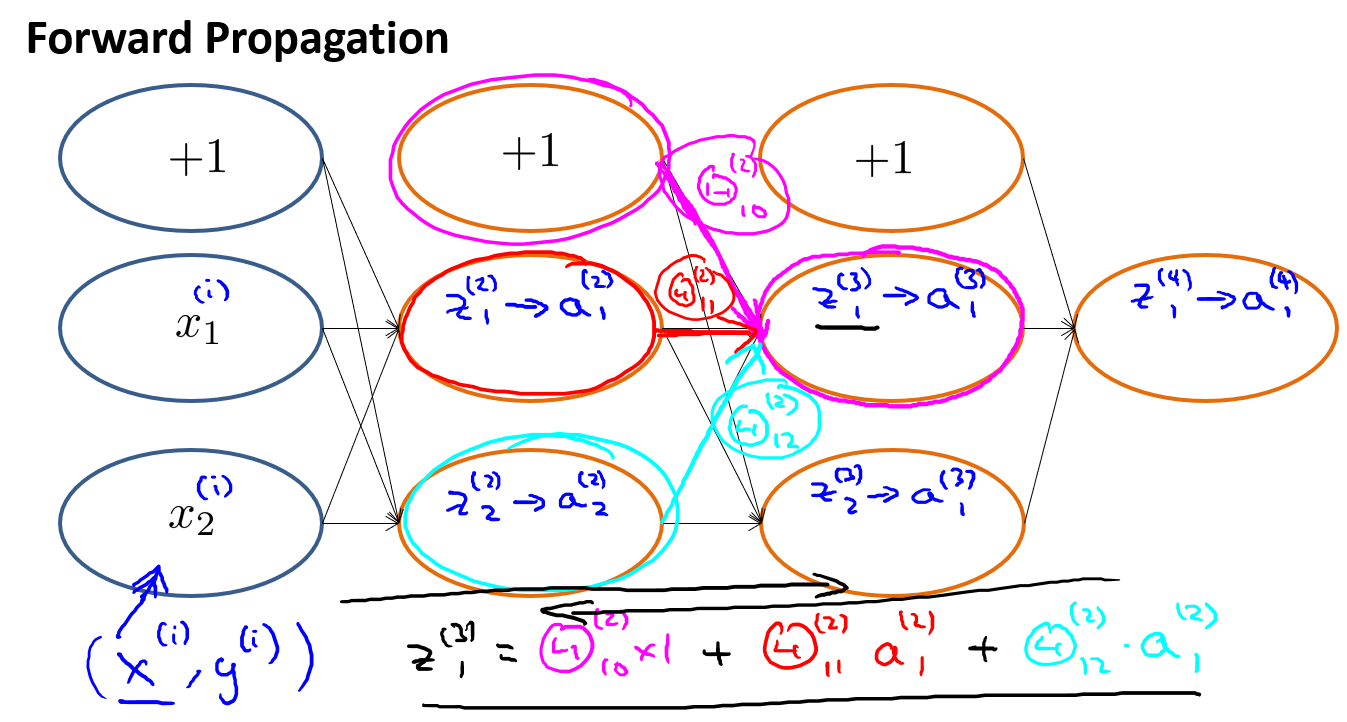
接下来看看代价函数:

上面的代价函数只适用于只有一个输出单元的情况,如果我们有多个输出单元需要在\(\sum_{i=1}^m\)前加一个\(\sum_{k=1}^{输出单元个数}\)
.这里我们同样忽略正则项,剩下的项相当于\((h_{\theta}(x^{(i)})-y)^2\)
反向传播的关键是\(\delta_j^{(l)}\),推导的关键式子是\(\delta\)的公式.上一层与下一层的权重越大,下一层的误差和上一层的结点关系越大

这副图没有计入偏置单元,我们也可以采取其他方法计入,但是请记住偏置单元的输出永远是1.老师自己的做法是计算偏导没有计入偏置单元.
9.4 实现注意:展开参数
在上一节中,我们谈到了怎样使用反向传播算法计算代价函数的导数.在这段视频中,我想快速地向你介绍一个细节的实现过程,怎样把你的参数从矩阵展开成向量,以便我们在高级最优化步骤中的使用需要.
我们在作业使用的fmin_unc函数,它的参数和计算梯度的函数返回值都需要是n维或n+1维向量,但是我们在一个完整的神经网络中,得到的参数和梯度都是矩阵,这就需要我们将矩阵展开为向量.

用Octave语言表达就是如下,思想概况一下就是利用切片和reshape来做到相互转换.

配合代码实现就是,在传参给fmin_unc函数的时候,我们传的参数\(\theta\)是一维向量,但是到代价Cost函数或者梯度函数我们需要将一维向量reshape回原来的参数矩阵.同样我们计算梯度函数的时候也需要转成一维返回.

9.5 梯度检测
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能并不是最优解.
为了避免这样的问题,我们采取一种叫做梯度的数值检验(Numerical Gradient Checking)方法.这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的.它是100%正确.
考虑下面这个例子:

上图是\(J(\theta)\)的图像,而\(\theta\)是实数.下面是从数值上求近似导数(梯度)的方法.就是取一点\(\epsilon\)(\(\epsilon\)是一个非常小的值,通常选取0.001,当它足够小,就变成了真正的导数),在特定点的两边取\(\theta-\epsilon\)和\(\theta+\epsilon\),而这两点的斜率就是近似导数.我们将围成的三角形画出来就是:
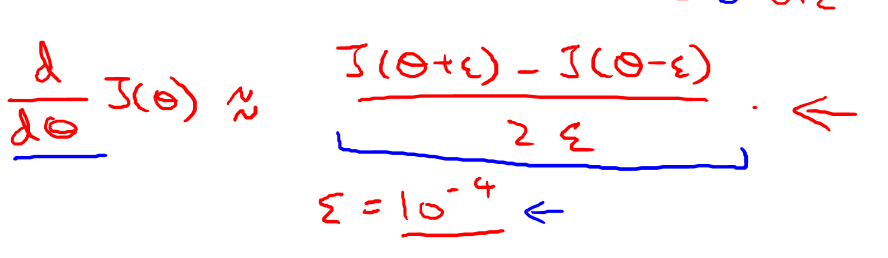
这也被称为双侧差分,比单侧差分(分母没有\(\frac12\))更准确.
上面我们只讨论了\(\theta\)为实数的情况,当\(\theta\)为矩阵时情况更为普遍.下图的\(\theta\)是\(n\)维向量,比如多个\(\theta\)的矩阵展开.

用代码实现的情况如下:

我们用此方法检验反向传播的偏导数.计算出的偏导数存储在矩阵\(D_{ij}^{(l)}\).检验时,我们要将该矩阵展开成为向量,同时我们也将\(\theta\)矩阵展开为向量,我们针对每一个\(\theta\)都计算一个近似的梯度值,将这些值存储于一个近似梯度矩阵中,最终将得出的这个矩阵同\(D_{ij}^{(l)}\)作比较.
所以步骤就是先用反向传播计算出偏导矩阵,再用梯度估计检验.但是我们不要使用梯度检验的方法计算梯度,因为计算量太大,上一节的方法是一个更为高效的方法.例如,如果我们在梯度下降的迭代或代价函数的内循环里使用了梯度检验,就会拖累程序进度.
9.6 随机初始化
前面我们讲述了所有神经网络要实现的内容,本节讲述最后的一个思想:随机初始化.
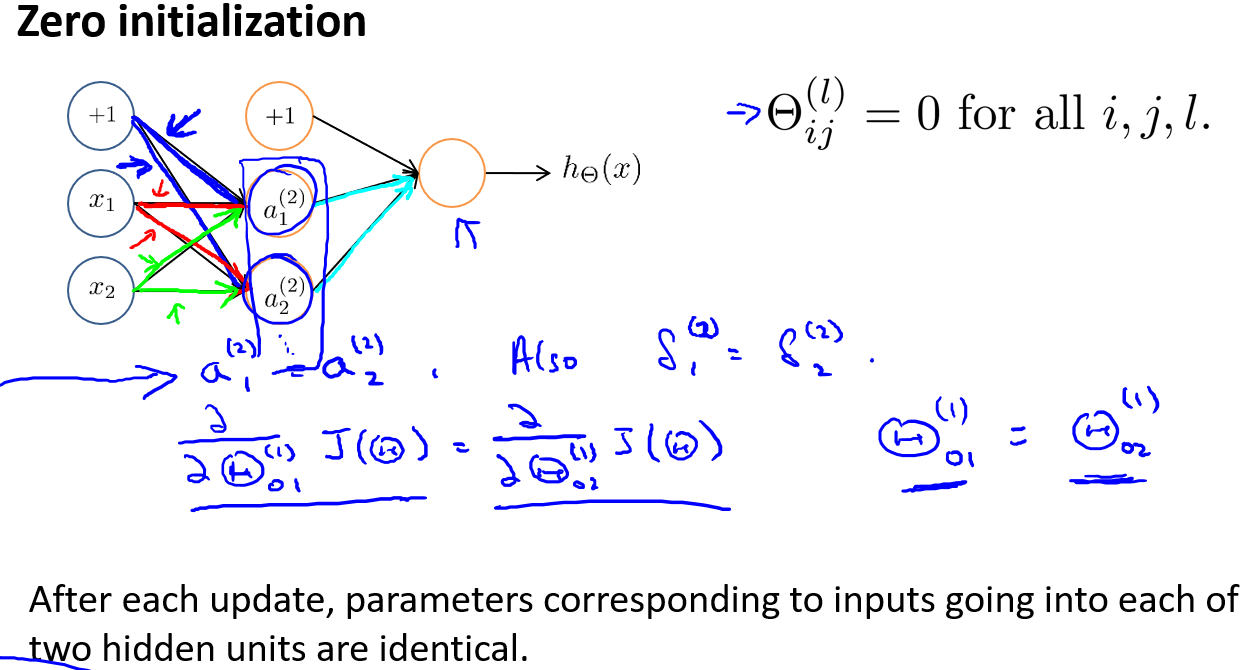
任何优化算法都需要一些初始的参数.到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的.如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值,再将得到的激活单元代入之前我们计算的\(\delta\)和偏导公式.因此每次更新后,同一颜色的参数都相等.同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的.
具体证明参考这里:Click,知乎这个公式显示地不行,配合这个看Click
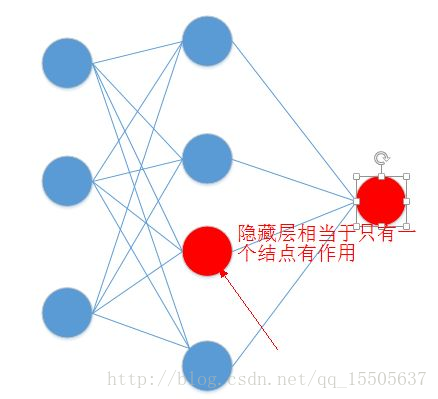
这相当于隐藏层无论每层有多少个结点,实际只有一个结点在起作用.
所以我们需要随机初始化参数,顺带一提\(\epsilon\)与梯度检验的没有什么关系:

我们通常初始参数为正负ε之间的随机值(\(\epsilon\)接近0),假设我们要随机初始一个尺寸为10×11的参数矩阵,代码如下:
Theta1 = rand(10, 11) * (2*eps) – eps
9.7 综合起来
本节的内容就是将前几节的内容综合.
小结一下使用神经网络时的步骤:
(1) 选择网络架构.即决定选择多少层以及决定每层分别有多少个单元.输入层的单元个数就是特征向量的维数,而输出层的个数(比如多类别问题)就是类的个数(注意输出的y向量是01向量,而不是直接等于1,2,3,4...).比较关键的是隐藏层,我们通常默认隐藏层是1,如果不是1,通常默认每层都有相同的单元个数.通常隐藏单元越多越好(大多为输入层个数的倍数),但是太多会有计算量太大的问题.
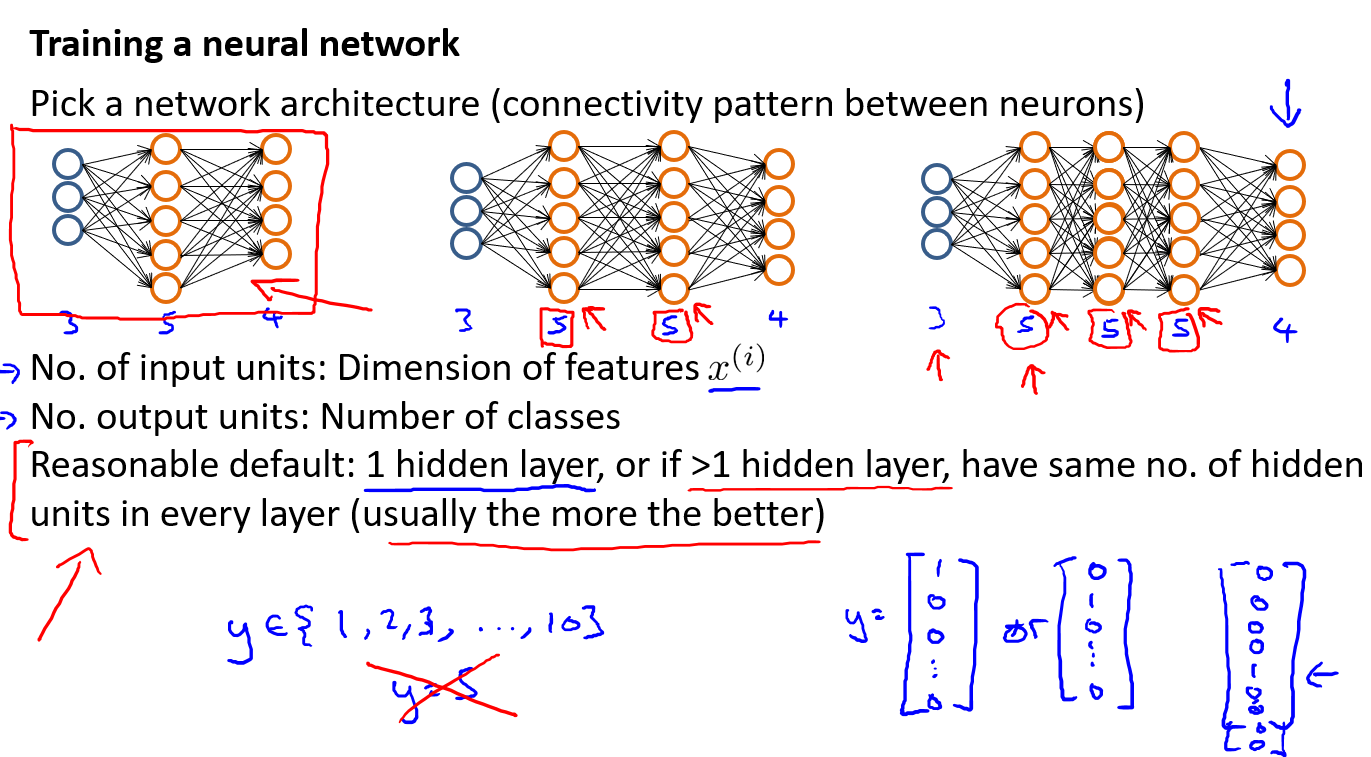
(2) 接下来介绍训练神经网络的步骤.
- 参数的随机初始化(通常是接近0的值)
- 利用正向传播方法计算所有的\(h_{\theta}(x)\)
- 写计算代价函数\(J\)的代码
- 利用反向传播方法计算所有偏导数
对于不熟悉的新手,老师推荐使用for循环对每一个样本遍历,在for循环里累加\(\Delta\),在for循环外(遍历完所有样本后)再计算偏导数.


- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号