机器学习 吴恩达 第六章 笔记
六、正则化(Regularization)
6.1 过拟合问题
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差.
在本节,我们将讲述什么是过拟合.在后面几节,我们将介绍一种正则化(regularization)的方法,它可以一定程度上改善过拟合的问题.
我们仍然用房价预测的例子来解释这个问题.
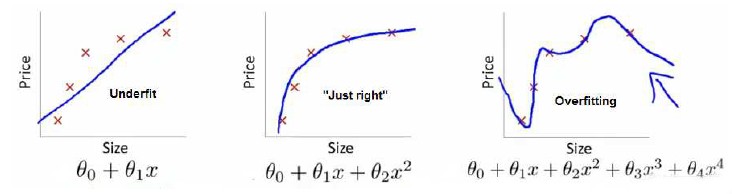
在第一幅图里,我们用一次函数拟合训练集,但是随着房子面积增大,价格逐渐平缓.该函数并没有很好地拟合训练集.我们把这种现象称为欠拟合,也可以说这种算法具有高偏差.
第二幅图用二次函数来拟合数据,这个拟合效果很好.
第三幅图,我们用四次函数来拟合数据,那么我们有五个参数.这样我们可以用一条曲线通过所有的训练样本.它似乎可以拟合所有的训练数据,但它不停地上下波动.这是过于强调拟合原始数据的原因,实际上我们不认为它是一个好的模型.这种现象我们称为过拟合.另一种说法是这种算法具有高方差.
总而言之,过拟合问题可能会在我们的假设函数有过多变量时出现,这时假设函数似乎很好地拟合了训练的数据集,代价函数会非常接近0.但它无法泛化到新的样本里.
逻辑回归也有同样的问题.
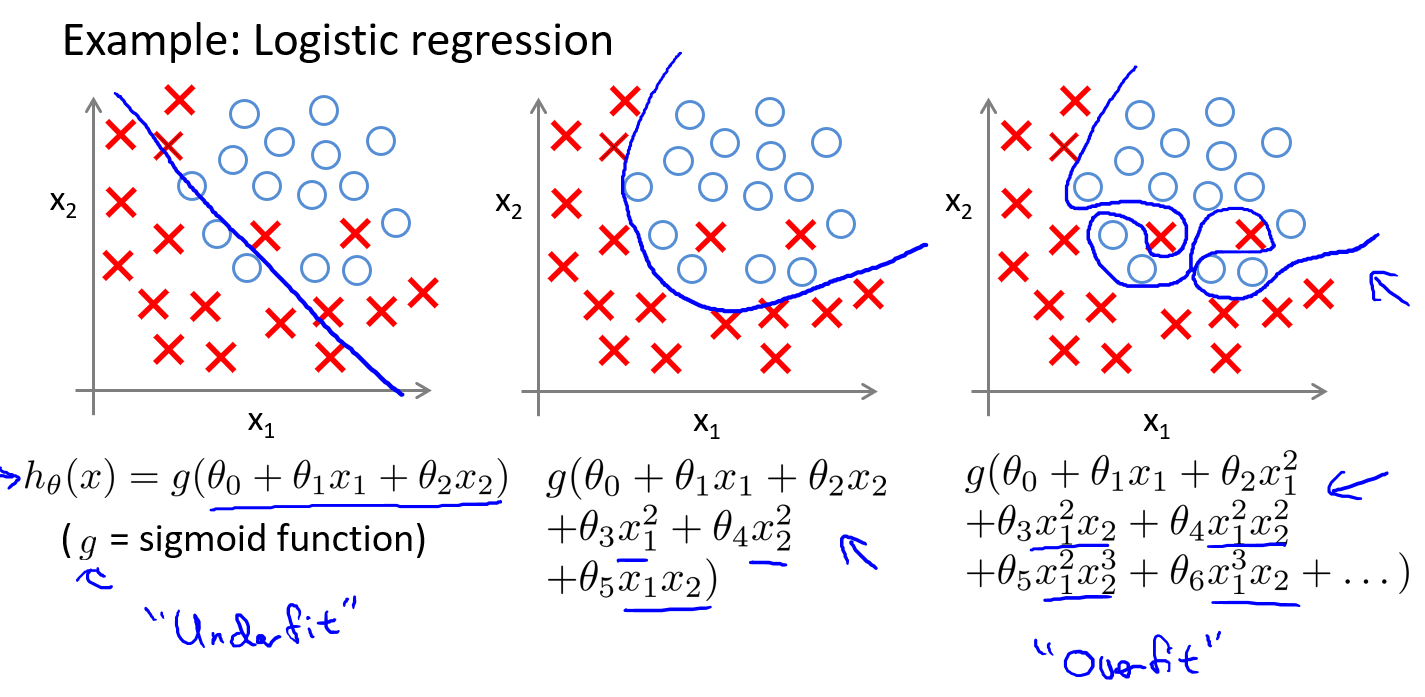
上面是一个以\(x_1、x_2\)为变量的例子.第一幅图同样用一次函数拟合数据,但似乎拟合效果不佳,这种现象也是欠拟合.最后一幅图,我们用高阶多项式拟合数据,对训练集拟合效果很好,但无法泛化到新样本里.就以多项式理解,x的次数越高,拟合的越好,但相应的预测的能力就可能变差
在课程的后半段,我们会讲述如何使用专门工具来识别过拟合和欠拟合的情况.
问题是,如果我们发现了过拟合问题,应该如何处理?
我们可以用绘制假设函数曲线作为决定多项式阶次的一种方法,但它不总是奏效的.如果我们面临的问题有很多特征变量(x)时,绘图就会变得困难,决定保留哪些变量也是很难的.以预测房价为例,如果我们有很多因素与房价有关,但此时拥有的训练集又很少,此时就很容易出现过拟合问题.这儿主要有两种方法来解决过拟合问题:
(1) 丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙选择特征(PCA).
(2) 正则化,保留所有的特征,但是减少参数的大小(\(magnitude\))
6.2 代价函数
在本节,我们将学习正则化是怎么运行的.当我们要运行正则化时,我们还会写出相应的代价函数.
上面的回归问题中如果我们的模型是:
我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了.所以我们要做的就是在一定程度上减小这些参数\(\theta\)的值,这就是正则化的基本方法.以上面的函数为例,我们要减少\(\theta_3\)和\(\theta_4\)的值,我们要做的便是修改代价函数,给\(\theta_3\)和\(\theta_4\)设置一点惩罚.这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的\(\theta_3\)和\(\theta_4\).修改后的代价函数如下(1000是任意的,这里只是设置了比较大的数):
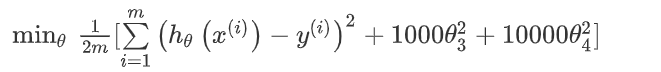
通过这样的代价函数选择出的\(\theta_3\)和\(\theta_4\),就接近于0,对预测结果的影响就比之前要小许多.假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚(这样相当于简化尽量简化这个假设模型),并且让代价函数最优化的软件来选择这些惩罚的程度.这样的结果是得到了一个较为简单的能防止过拟合问题的假设:
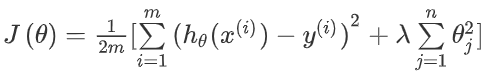
让我们再看房价预测的例子,这里的例子有100个特征值,与之前的例子不同,我们不知道哪个参数是高阶项,我们也比较难知道哪个特征是相关度比较低的.这里我们要做的就是修改代价函数,以减小所有参数的值.:
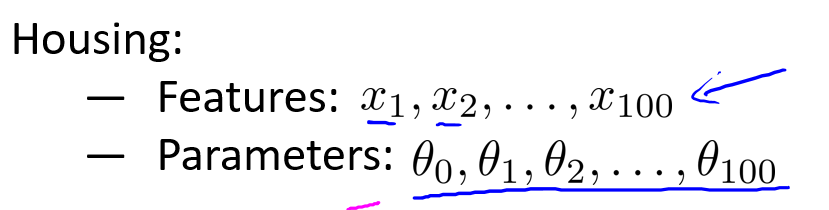
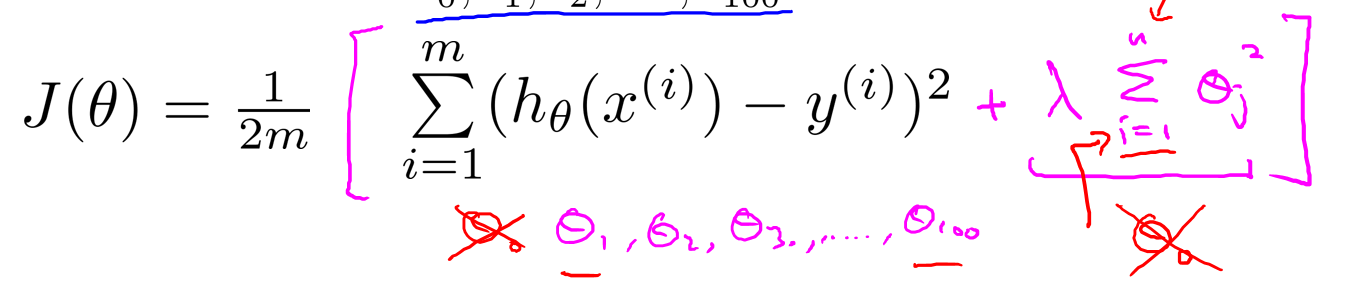
请注意求和是从
1开始的,我们不会给\(\theta_0\)设置惩罚项.但实践中,设不设置没有什么区别.
我们来看下面的图以获得更好的解释.新的代价函数有两个目标,一个是前面的误差项,我们的目标是最小化它以更好地拟合数据.第二个目标是后面的正则化项,我们要使参数尽可能小.这个正规化参数\(\lambda\)(Regularization Parameter)的作用就是控制两个目标之间的平衡关系,从而使假设函数尽可能简单,避免出现过拟合现象.
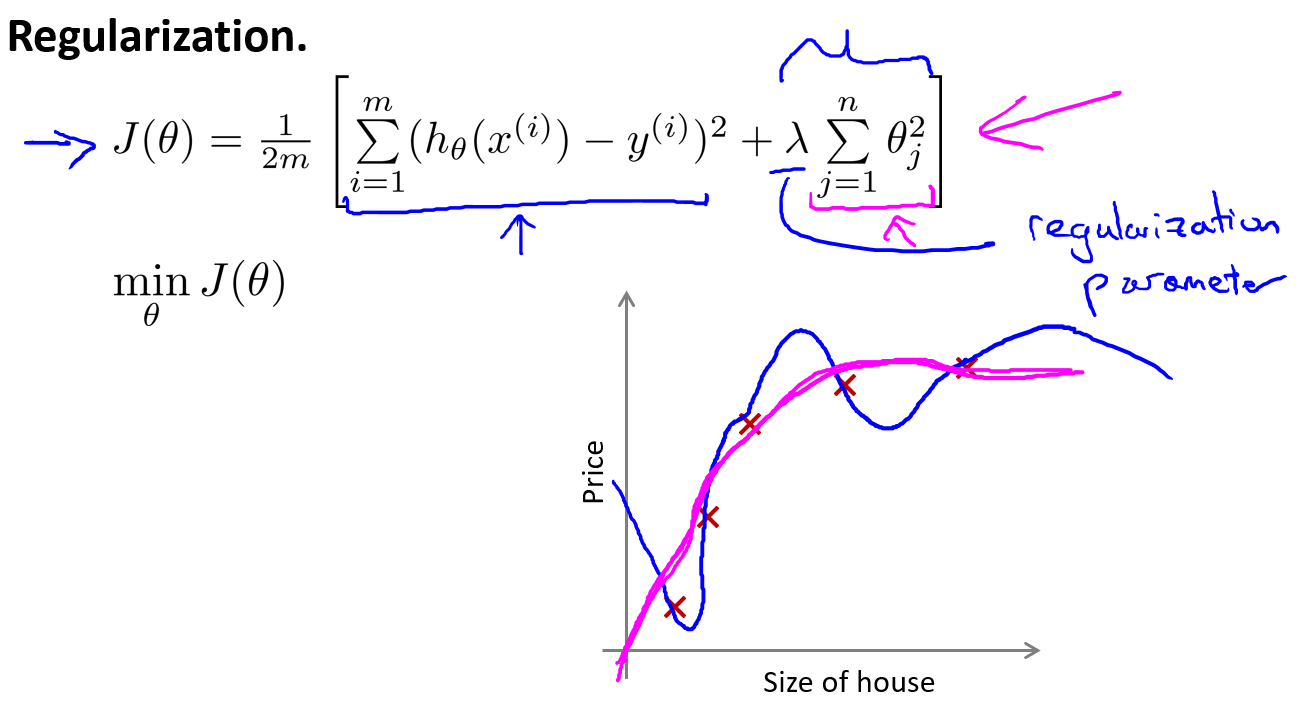
如果选择的正则化参数\(\lambda\)过大,则会把所有的参数都最小化了,导致模型变成 \(h_{\theta}(x) = \theta_0\).也就是下图中红色直线所示的情况,造成欠拟合.那么到底是如何做到让高阶的比例更小呢?我个人理解是如果要完全符合样本数据,这时误差项接近于0,但就会在假设函数里出现高阶项,与此同时后面的正则化项就会有较大惩罚.但如果最小化正则化项也不行,这样会使得误差项更大.因此,我们这里最小化\(J\)函数就只能是在两个之间做取舍.为了达到平衡,这样就使相关性大的特征参数也大,相关性小的特征参数也小.
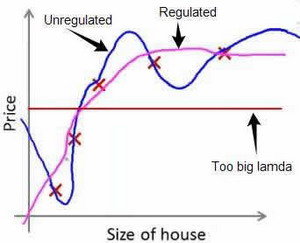
所以对于正则化,我们要取一个合理的\(\lambda\)值.这样才能更好的应用正则化.回顾一下代价函数,为了使用正则化,让我们把这些概念应用到到线性回归和逻辑回归中去,那么我们就可以让他们避免过度拟合了.
6.3 线性回归的正则化
对于线性回归的求解,我们之前推导了两种学习算法:一种基于梯度下降,一种基于正规方程.本节我们会把这两个算法推广到正则化线性回归里.
正则化线性回归的代价函数如下,我们要找一个参数\(\theta\)来最小化代价函数:

如果我们采用梯度下降法令这个代价函数最小化,因为我们未对\(\theta_0\)正则化,所以梯度下降算法将分两种情形:
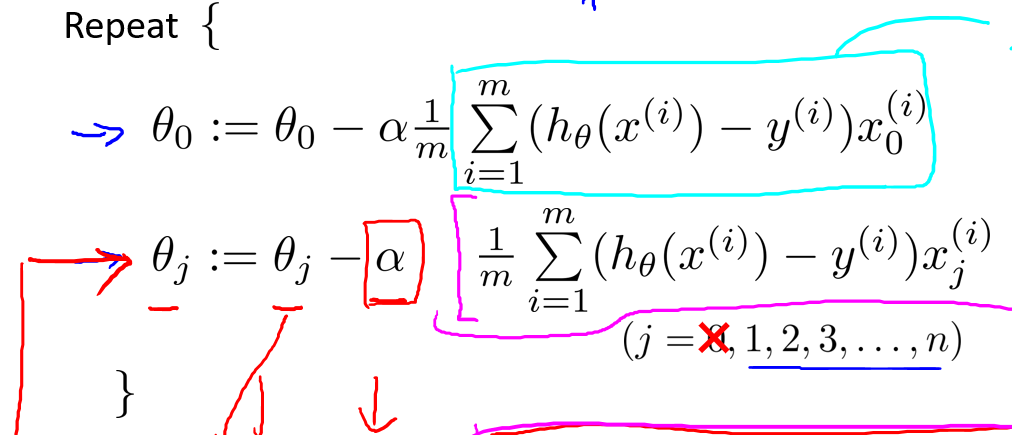
现在我们要用正则化项修改这个算法,我们要做的就是做如下修改,这实际上就是\(J(\theta)\)的偏导数:
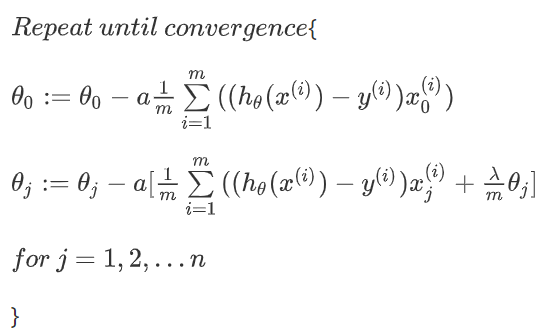
对上面的算法中,\(j=1,2,...,n\)时的更新式子进行调整可得:
对于上式的\((1-a\frac{\lambda}{m})\)这个结果实际很接近1,类似于0.99,而第二项\(a\frac1m\sum_{i=1}^m(h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)}\)实际就是和我们之前的梯度下降一样.所以区别就是\(j=[1,n]\)时,更新的\(\theta_j\)被缩小了.
我们同样也可以利用正规方程来求解正则化线性回归模型,我们回忆一下原来的正规方程求解\(\theta\):
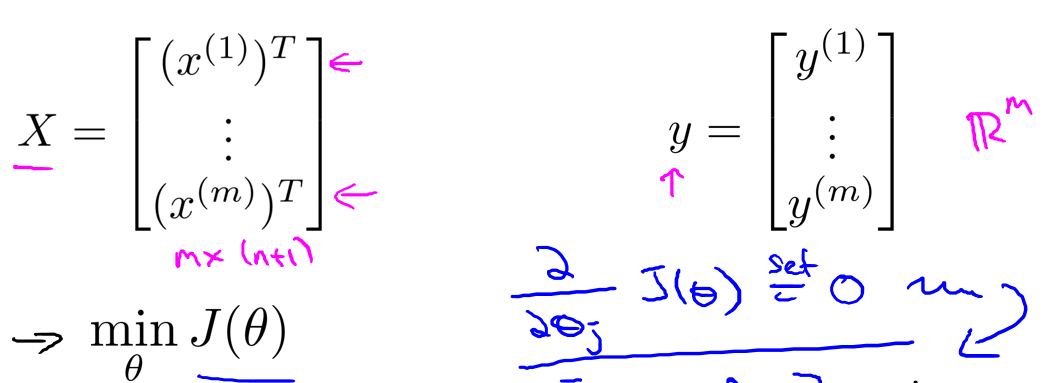
为了最小化\(J\),我们的\(\theta\)等于:
现在我们用正则化来得到想要的最小值,可以得到新的\(\theta\)的推导式如下:
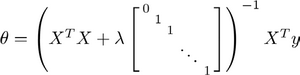
多出来的0,1,1,...1矩阵实际源自于\(\frac{\partial J(\theta)}{\partial \theta_j} =0\)经过一些数学推导而来的公式.
图中的矩阵尺寸为\((n+1) \times (n+1)\)
详细的推导过程可以看这个Click
这里解释一下为什么最后因为\(\theta_0\)不参与就得出了那个0111矩阵.可以在纸上计算一下,一开始求出的\(\lambda\theta^T\theta\)的\(\theta\)与前面的\(\theta\)不同.建议在草稿纸上计算一下,后面有时间写个电子版修改的推导.
最后我们仍然要探讨矩阵可逆的问题.如果你的样本数比特征数要少,那么\(X^TX\)是不可逆的,尽管我们可以求它的伪逆,但最后不会得到很好的假设模型.但是正则化已经考虑到了这个问题:
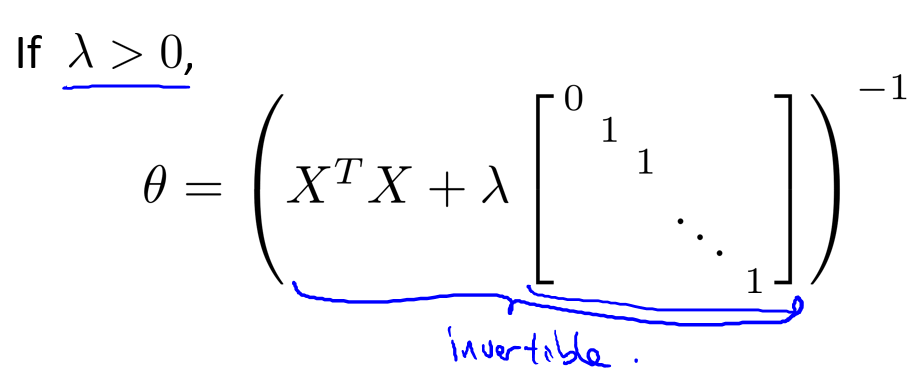
我们可以保证,只要\(\lambda > 0\),那么上图的式子就一定可逆(非奇异矩阵).所以使用正则化还可以解决出现不可逆的问题.
6.4 正则化的逻辑回归模型
针对逻辑回归问题,我们在之前的课程已经学习过两种优化算法:一种是梯度下降,另一种是更高级的优化算法.这些算法都需要计算代价函数\(J(\theta)\)和它的导数.这节会讲述如何改进这两种算法以致于可以运用到正则化逻辑回归里.
从前面可以知道逻辑回归也会有过拟合的问题.

下面是逻辑回归的代价函数计算式子,如果我们要正则化,就需要对它进行一些修改:
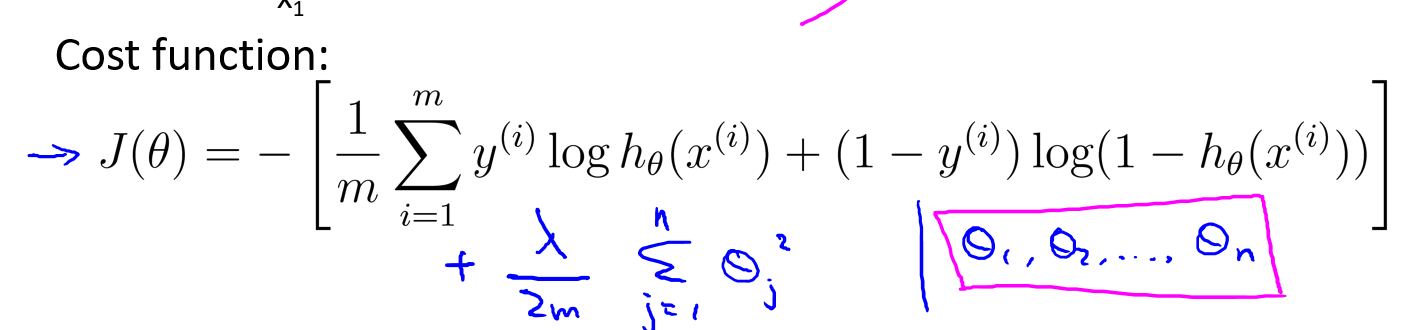
\(ppt\)上的公式书写可能会造成误会,实际上\(J(\theta)\)的计算是这样的:
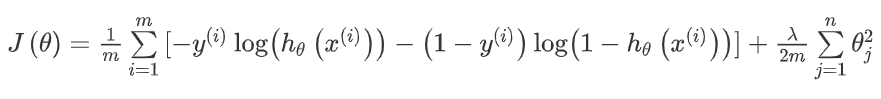
接下来我们需要最小化代价函数,这里使用梯度下降的方法(之前已经证明过梯度下降后的公式了,这里不再写),因为正则惩罚不包括\(\theta_0\),所以需要将\(\theta_0\)单独列出:
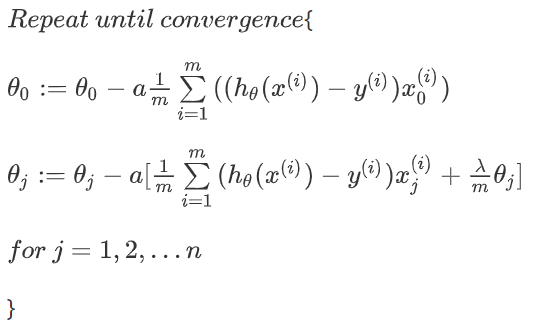
虽然推出来的式子很像线性回归,但是\(h_{\theta}(x^{(i)})\)的含义不同.逻辑回归的\(h_{\theta}(x^{(i)}) = g(\theta^TX)\).并且方括号里的就是\(\frac{\partial J(\theta)}{\partial \theta_j}\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号