机器学习 吴恩达2022 第一章 笔记
1.第一周
这篇笔记很多源自这位大佬,我实在是打不出这么多字(.)
1.1 什么是机器学习
机器学习是什么?在本视频中,我们会尝试着进行定义,同时让你懂得何时会使用机器学习。实际上,即使是在机器学习的专业人士中,也不存在一个被广泛认可的定义来准确定义机器学习是什么或不是什么,现在我将告诉你一些人们尝试定义的示例。第一个机器学习的定义来自于Arthur Samuel.他定义机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域.Samuel的定义可以回溯到50年代,他编写了一个西洋棋程序.这程序神奇之处在于,编程者自己并不是个下棋高手.但因为他太菜了,于是就通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察哪种布局(棋盘位置)会赢,哪种布局会输,久而久之,这西洋棋程序明白了什么是好的布局,什么样是坏的布局。然后程序通过学习后,玩西洋棋的水平超过了Samuel.这绝对是令人注目的成果.
机器学习的两种主要类型是监督学习和无监督学习.监督学习是世界上实际运用最多的类型,也是进步最快和创新最多的算法.本课程的三个主要部分,前两个注重监督学习,最后一个注重无监督学习.此外,强化学习也是机器学习的一种算法.
1.2 监督学习
1.2.1 监督学习-回归
监督机器学习或更常见的监督学习指学习x到y或输入映射到输出映射的算法.监督学习的关键特征是你给你学习的算法提供学习的例子.这些例子中有正确的答案.即对于给定的输入\(x\),标上正确的输出\(y\).监督学习算法发只需要接收输入\(x\),而不需要输出\(y\).看下面的例子:
比如输入\(x\)是\(email\),而输出就是是否是垃圾邮件.这个算法将会提供垃圾邮件过滤器.再比如输入是一则语音,输出是文本.那么算法就是语音识别.最后比如输入是语言A,输出是语言B,这就是机器翻译.
扩展来说,就是提供给你的机器学习的算法一些样本集,算法从样本集中学习,然后就可以接收新的输入(不在样本集里的),不断训练,得到正确的输出\(y\).
看一个具体的例子,根据房子的大小来预测房价.横坐标是房子的大小,纵坐标是房子的价格.
我们应用学习算法,可以在这组数据中画一条直线,或者换句话说,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖150k美元,当然这不是唯一的算法。可能还有更好的,比如我们不用直线拟合这些数据,用二次方程去拟合可能效果会更好.根据二次方程的曲线,我们可以从这个点推测出,这套房子能卖接近200k美元。稍后我们将讨论如何选择学习算法,如何决定用直线还是二次方程来拟合。两个方案中有一个能让你朋友的房子出售得更合理。这些都是学习算法里面很好的例子。以上就是监督学习的例子

在本课后面,我们将学习如何决定是否是拟合一条直线,一条曲线或其他对数据更复杂的函数.
可以看出,监督学习指的就是我们给学习算法一个数据集.这个数据集由"正确答案"组成.在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案.比如你朋友那个新房子的价格.用术语来讲,这叫做回归问题.我们试着推测出一个连续值的结果,即房子的价格.
一般房子的价格会记到美分,所以房价实际上是一系列离散的值,但是我们通常又把房价看成实数,看成是标量,所以又把它看成一个连续的数值.
回归这个词的意思是,我们在试着推测出这一系列连续值属性.
根据课程定义,回归就是从无限多可能的数字中预测出一个数
1.2.2 监督学习-分类
回归是监督学习算法之一,还有一种监督学习算法称作分类.
我再举另外一个监督学习的例子.我和一些朋友之前研究过这个.假设说你想通过查看病历来推测乳腺癌良性与否,假如有人检测出乳腺肿瘤,恶性肿瘤有害并且十分危险,而良性的肿瘤危害就没那么大,所以人们显然会很在意这个问题.
我们可能有一个数据集(包含各种大小的肿瘤),这些肿瘤要么被标记为良性(用0标识),要么被标记为恶性(用1标识).然后我们将数据绘制在如下图表,横坐标是肿瘤大小,纵坐标是分类:

我有5个良性肿瘤样本,在1的位置有5个恶性肿瘤样本.现在我们有一个朋友很不幸检查出乳腺肿瘤.假设说她的肿瘤大概这么大,那么机器学习的问题就在于,你能否估算出肿瘤是恶性的或是良性的概率.用术语来讲,这是一个分类问题.
分类指的是,我们试着推测出离散的输出值:0或1良性或恶性,而事实上在分类问题中,输出可能不止两个值.比如说可能有三种乳腺癌,所以你希望预测离散输出0、1、2、3.0 代表良性,1 表示第1类乳腺癌,2表示第2类癌症,3表示第3类,但这也是分类问题.
在其它一些机器学习问题中,可能会遇到不止一种特征.举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄.在其他机器学习问题中,我们通常有更多的特征,我朋友研究这个问题时,通常采用这些特征,比如肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等,还有一些其他的特征.这就是我们即将学到最有趣的学习算法之一.
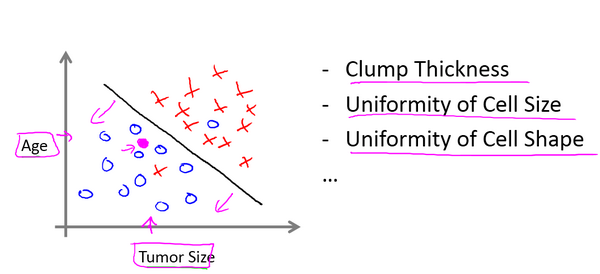
1.3 无监督学习
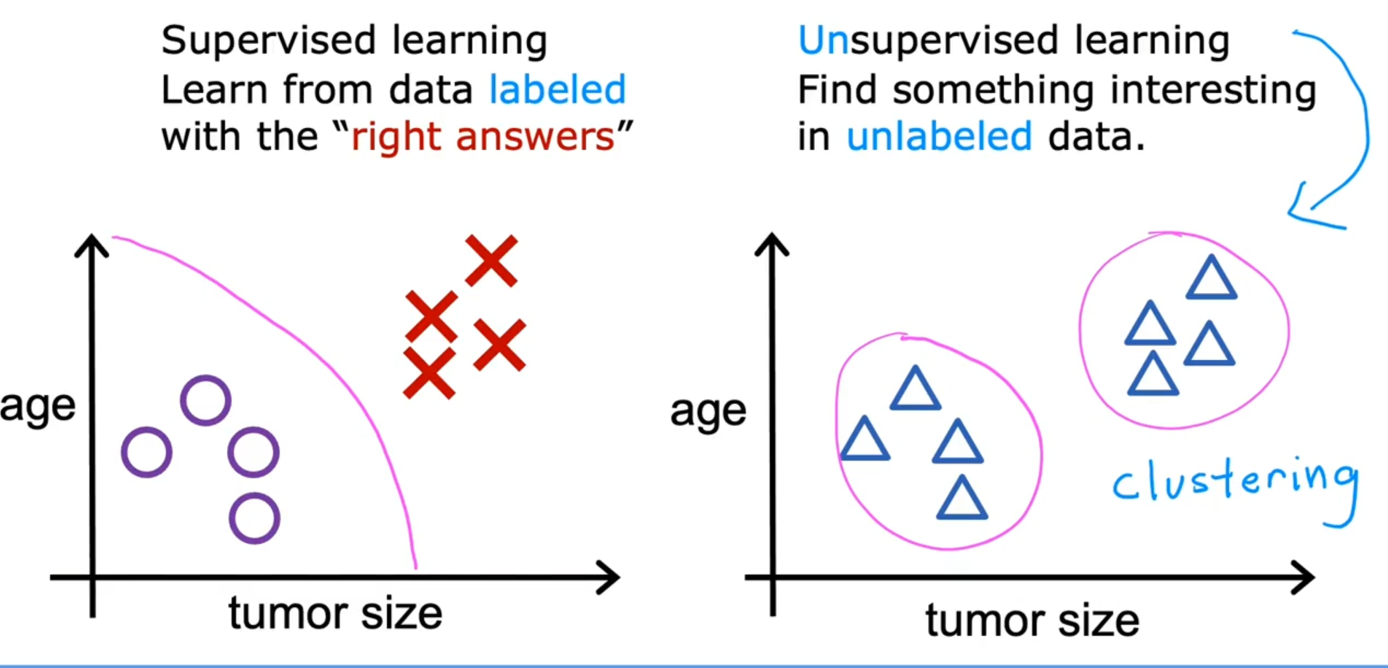
上个视频中,已经介绍了监督学习.回想当时的数据集,如图表所示,这个数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤.所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了.
在无监督学习中,我们已知的数据.看上去有点不一样,不同于监督学习的数据的样子,无监督学习没有任何的如上要求输出的\(y\).也就是说,我们得到一个数据,却不知道用来做什么.我们要求我们的算法自己弄清楚什么是有趣的,或者让算法自己找出这个数据中有什么模式或结构.
针对无监督学习,算法可能判断出有两个不同的聚集簇.下面紫色圈中有不同的两个聚集簇.所以无监督学习算法可以将数据分为两个不同的聚集聚集簇.这也叫簇类算法.
簇类算法被应用在许多不同的地方.聚类应用的一个例子就是在谷歌新闻中,如果你以前从来没见过它,你可以到这个URL网址news.google.com去看看.谷歌新闻每天都在,收集非常多,非常多的网络的新闻内容.它再将这些新闻分组,组成有关联的新闻.所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起.所以,这些新闻事件全是同一主题的,所以显示到一起.
事实证明,聚类算法和无监督学习算法同样还用在很多其它的问题上.
其中就有基因学的理解应用.一个DNA微观数据的例子.基本思想是输入一组不同个体,对其中的每个个体,你要分析出它们是否有一个特定的基因.技术上,你要分析特定基因的表达程度.所以这些颜色,红,绿,灰等等颜色,这些颜色展示了相应的程度,即不同的个体是否有着一个特定的基因.你能做的就是运行一个聚类算法,把个体聚类到不同的类或不同类型的组(人)……

所以这个就是无监督学习,因为我们没有提前告知算法一些信息.比如,这是第一类的人,那些是第二类的人,还有第三类,等等.我们只是说,这是有一堆数据.我不知道数据里面有什么.我不知道谁是什么类型.我甚至不知道人们有哪些不同的类型,这些类型又是什么.但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些.因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习.
无监督学习或聚集有着大量的应用.一种应用就是社交网络的分析.所以已知你朋友的信息,比如你经常发email的,或是你Facebook的朋友、谷歌+圈子的朋友,我们能否自动地给出朋友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人?还有市场分割.许多公司有大型的数据库,存储消费者信息.所以,你能检索这些顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中,你才能自动并更有效地销售或不同的细分市场一起进行销售.这也是无监督学习,因为我们拥有所有的顾客数据,但我们没有提前知道是什么的细分市场,以及分别有哪些我们数据集中的顾客.我们不知道谁是在一号细分市场,谁在二号市场,等等.那我们就必须让算法从数据中发现这一切。最后,无监督学习也可用于天文数据分析,这些聚类算法给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。这些都是聚类的例子,聚类只是无监督学习中的一种.
现在我们来介绍另外一种,比如鸡尾酒会的问题.因为之前发的笔记只是字幕的合集,我直接概括一下意思:两个人同时说话,录音记录下了两个人声音,鸡尾酒会算法可以将两个人的声音分离开.也就是输出去除杂音两个人各自的声音.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号