Chapter 3: Built-in Data Structures, Functions, and Files 个人理解与问题
Chapter 3: Built-in Data Structures, Functions, and Files
声明一下这里直接导入了Jupter notebooks的markdown笔记,不是很方便阅读
3.1 数据结构与序列
3.1.1 元组
元组可以通过括号[]来获取
tup = tuple([4,0,2])
tup[1]
0
元组乘以整数,则会和列表一样,生成含有多个拷贝的数组,这些元组的地址是相同的.
tup = ('foo','bar')
id(tup)
id(tup*4)
1950453912624
id(tup*4)
1950453912624
tup*4
('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')
3.1.1.1 元组拆包
Python会对元组进行拆包,也就是如果一个元组有N个元素,将元组赋值给N个变量,每个变量按位置从元组取值
a,b,c = (4,5,6)
print(f"a是{a},b是{b},c是{c}")
a是4,b是5,c是6
拆包应用于循环十分方便,参考如下代码
seq = [(1,2,3),(5,2,1),(121,41,11),(3,0,13)]
for a,b,c in seq:
print(f"a是{a},b是{b},c是{c}")
a是1,b是2,c是3
a是5,b是2,c是1
a是121,b是41,c是11
a是3,b是0,c是13
由于元组拆包功能,我们可以应用它来丢弃会存储某些数据,这些数据会存储在列表
a,b,*rest=(1,2,3,4)
print(a)
print(b)
print(rest)
1
2
[3, 4]
3.1.1.2 元组方法
元组的实例方法少,有一个count用于计数元组有多少个元素
tup = (1,2,31,3,1,1,1,1,5,3)
print(tup.count(1))
5
3.1.2 列表
3.1.2.1 增加和移除元素
使用append()方法可以增加列表元素,也可以使用insert()方法指定插入位置,但是insert()方法开销比较大.如果我们在双端插入元素比较多,可以考虑使用collection.deuqe.它是一个双端队列,类似C++的deque.
pop()可以删除指定位置的元素,remove(str)会删除列表中第一个str元素
in和not in 用于检查列表中是否有某元素
3.1.2.2 连接和联结列表
与元组类似,列表可以使用+连接
[4,5,None]+[7,8,(1,2,3),{1:'foo',2:'str'}]
[4, 5, None, 7, 8, (1, 2, 3), {1: 'foo', 2: 'str'}]
+效率较低,用extend效率更高
a = [4,5,None]
a.extend([7,8,(1,2,3),{1:'foo',2:'str'}])
a
[4, 5, None, 7, 8, (1, 2, 3), {1: 'foo', 2: 'str'}]
3.1.2.3 排序
sort()可以对列表内部进行排序(永久改变列表),sort有一个参数key,向key传参可以改变列表排序的方式
a = ['aaa','12','dwdawdawd','wdadawdawdwwadawdwadwad','r']
a.sort(key=len)
print(a)
['r', '12', 'aaa', 'dwdawdawd', 'wdadawdawdwwadawdwadwad']
3.1.2.4 二分搜索和已排序列表的维护
内建的bisect模块实现了二分搜索和已排序序列的插值.bisect.bisect会找到元素应该插入的位置,并保持序列排序.而bisect.insort将元素插入到相应位置
import bisect
c = [1,2,2,3,4,7]
bisect.bisect(c,2)
3
bisect.insort(c,2)
c
[1, 2, 2, 2, 3, 4, 7]
bisect.insort(c,10)
c
[1, 2, 2, 2, 3, 4, 7, 10]
3.1.3 内建序列函数
Python中有很多有用的序列函数
3.1.3.1 enumerate
enumerate函数用于返回一个元素是(索引,对应列表元素)的新列表对象,但是返回值不是真正的列表,而是一个enumerate object,只是因为它允许迭代才可以这样做.
some_list = ['foo','bar','baz']
for k,v in enumerate(some_list):
print(f"{k}的值是{v}")
0的值是foo
1的值是bar
2的值是baz
enumerate?
3.1.3.2 sorted
sorted可以接受的参数与sort一致
3.1.3.3 zip
zip可以将多个列表、元组或其它序列成对组合成一个元组列表,但是返回值是zip对象,是允许迭代的,可以转化为list列表
seq1 = ['foo','bar','baz']
seq2 = ['one','two','three']
zipped = zip(seq1,seq2)
zipped
<zip at 0x1c6212d0ac0>
list(zipped)
[('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
zip可以处理任意多的序列,元素的个数取决于最短的序列:
seq3 = [False,True]
list(zip(seq1,seq2,seq3))
[('foo', 'one', False), ('bar', 'two', True)]
zip的常见用法之一是同时迭代多个序列,可能结合enumerate使用:
从下面来看,拆包元组还是需要一一对应,如果元组中还有元组
for i in enumerate(zip(seq1,seq2)):
print(i)
(0, ('foo', 'one'))
(1, ('bar', 'two'))
(2, ('baz', 'three'))
for i,(a,b) in enumerate(zip(seq1,seq2)):
print(f"{i}:({a},{b})")
print(f"a是{a},b是{b}")
0:(foo,one)
a是foo,b是one
1:(bar,two)
a是bar,b是two
2:(baz,three)
a是baz,b是three
给出一个"被压缩的"序列,zip可以被用来解压序列.也可以当作把行的列表转换为列的列表.这个方法看起来有点神奇:(行列是书上原话,没理解什么意思)
pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'),('Schilling', 'Curt')]
first_names,last_names = zip(*pitchers)
print(first_names)
print(last_names)
('Nolan', 'Roger', 'Schilling')
('Ryan', 'Clemens', 'Curt')
3.1.3.4 reversed
reversed函数将序列的元素倒序排序,reversed函数是一个生成器,它只能返回一个迭代器,只有实体化(即列表或for循环)之后才能创建翻转的序列
list(reversed(range(10)))
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
3.1.4 字典
字典可能是Python最为重要的数据结构。它更为常见的名字是哈希映射或关联数组。它是键值对的大小可变集合,键和值都是Python对象。创建字典的方法之一是使用尖括号,用冒号分隔键和值.
我们可以用del或者pop从字典中删除值,其中pop可以获得返回值
dict_1 = {'1001':'张三','1002':'李四','1003':'王五'}
name = dict_1.pop('1002')
name
'李四'
dict_1
{'1001': '张三', '1003': '王五'}
update方法可以将字典合并,从实验来看没有改变字典的位置
dict_1 = {'1001':'张三','1002':'李四','1003':'王五'}
print(f"第一次{id(dict_1)}")
dict_1.update({'1004':'赵六','1005':'李白'})
id(dict_1)
print(f"第二次{id(dict_1)}")
第一次1950473138304
第二次1950473138304
3.1.4.1 从序列生成字典
因为字典本质上是2元元组的集合,dict可以接受2元元组的列表:
而后有字典推导式,也能创建字典
mapping = dict(zip(range(5),reversed(range(5))))
mapping
{0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
3.1.4.2 默认值
Python 字典 setdefault() 函数和 get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值.
- key -- 查找的键值.
- default -- 键不存在时,设置的默认键值.
返回值:如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。
words = ['apple','bat','bar','atom','book']
#by_letter针对首字母存储字典
by_letter = {}
for word in words:
letter = word[0]
if letter in by_letter:
by_letter[letter].append(letter)
else:
by_letter[letter] = [word]
print(by_letter)
{'a': ['apple', 'a'], 'b': ['bat', 'b', 'b']}
上述代码与下面等效
by_letter2 = {}
for word in words:
letter = word[0]
by_letter2.setdefault(letter,[]).append(word)
print(by_letter2)
{'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}
但是还有更方便的,collections模块有一个很有用的类defaultdict,它可以进一步简化上面.如果不存在key,它会使用默认值,但是我们在创建defaultdict时,必须指定一个可以创建默认值的函数,参考如下代码
from collections import defaultdict
by_letter3 = defaultdict(list)
for word in words:
by_letter3[word[0]].append(word)
print(by_letter3)
defaultdict(<class 'list'>, {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']})
3.1.4.3 有效的字典键类型
字典的值可以是任意Python对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。这被称为“可哈希性”。可以用hash函数检测一个对象是否是可哈希的(可被用作字典的键).
print(hash("123"))
print(hash((1,3,4)))
7841519930062954612
-1070212610609621906
hash((1,3,[1,3]))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-57-df3578781556> in <module>
----> 1 hash((1,3,[1,3]))
TypeError: unhashable type: 'list'
3.1.5 集合
集合是无序的不可重复的元素的集合。你可以把它当做字典,但是只有键没有值。可以用两种方式创建集合:通过set函数或使用尖括号set语句
s1 = {1,2,3,4}
s2 = set([1,3,3,4])
print(type(s1))
print(type(s2))
<class 'set'>
<class 'set'>
集合支持合并、交集、差分和对称差等数学集合运算。考虑两个示例集合:
a = {1, 2, 3, 4, 5}
b = {3, 4, 5, 6, 7, 8}
合并是取两个集合中不重复的元素。可以用union方法,或者|运算符;
交集的元素包含在两个集合中。可以用intersection或&运算符;
print(a.intersection(b))
print(a & b)
print(a.union(b))
print(a | b)
{3, 4, 5}
{3, 4, 5}
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7, 8}
下表给出常见的集合操作:
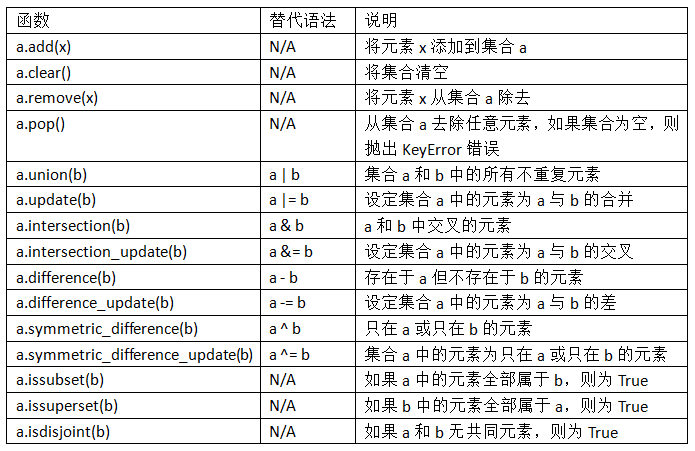
与字典类似,集合元素通常都是不可变的。要获得类似列表的元素,必须转换成元组:
my_set = {tuple([1,2,3,45])}
print(my_set)
{(1, 2, 3, 45)}
my_set = {[1,2,3,4]}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-63-9f5b1d870c7b> in <module>
----> 1 my_set = {[1,2,3,4]}
TypeError: unhashable type: 'list'
3.1.6 列表、集合和字典推导式
列表推导式是Python最受喜爱的特性之一。它允许用户方便的从一个集合过滤元素,形成列表,在传递参数的过程中还可以修改元素。形式如下:
# [expr for val in collection if condition]
# 它等同于下面的for循环:
# result = []
# for val in collection:
# if condition:
# result.append(expr)
用相似的方法,还可以推导集合和字典。字典的推导式如下所示:
dict_comp = {key-expr : value-expr for value in collection if condition}
集合的推导式与列表很像,只不过用的是尖括号:
set_comp = {expr for value in collection if condition}
假如我们只想要字符串的长度,用集合推导式的方法非常方便:
strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
unique_lengths = {len(x) for x in strings}
unique_lengths
{1, 2, 3, 4, 6}
map函数可以进一步简化:
map() 会根据提供的函数对指定序列做映射.
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表.
map(function, iterable, ...)
- function -- 函数
- iterable -- 一个或多个序列
返回值:
Python 3.x 返回迭代器
set(map(len, strings))
{1, 2, 3, 4, 6}
3.1.6.1 嵌套列表推导式
假设我们有一个包含列表的列表,包含了一些英文名和西班牙名:
all_data = [['John', 'Emily', 'Michael', 'Mary', 'Steven'],['Maria', 'Juan', 'Javier', 'Natalia', 'Pilar']]
你可能是从一些文件得到的这些名字,然后想按照语言进行分类。现在假设我们想用一个列表包含所有的名字,这些名字中包含两个或更多的e。可以用for循环来做:
names_of_interest = []
for names in all_data:
enough_es = [name for name in names if name.count('e') >= 2]
names_of_interest.extend(enough_es)
print(names_of_interest)
['Steven']
可以用嵌套列表推导式的方法,将这些写在一起,如下所示:
names_of_interest = [name for names in all_data for name in names if name.count('e') >= 2]
print(names_of_interest)
['Steven']
嵌套列表推导式看起来有些复杂。列表推导式的for部分是根据嵌套的顺序,过滤条件还是放在最后
记住,for表达式的顺序是与嵌套for循环的顺序一样(而不是列表推导式的顺序):
你可以有任意多级别的嵌套,但是如果你有两三个以上的嵌套,你就应该考虑下代码可读性的问题了。分辨列表推导式的列表推导式中的语法也是很重要的:
some_tuples = [(1,2,3),(4,5,6),(7,8,9)]
[[x for x in tup] for tup in some_tuples]
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
这段代码产生了一个列表的列表,而不是扁平化的只包含元素的列表.一定要区分列表推导式中的列表推导式和嵌套列表推导式
3.2 函数
函数是Python中最主要也是最重要的代码组织和复用手段.作为最重要的原则,如果你要重复使用相同或非常类似的代码,就需要写一个函数.通过给函数起一个名字,还可以提高代码的可读性.
3.2.1 命名空间、作用域和本地函数
函数可以访问两种不同作用域中的变量:全局(global)和局部(local).Python有一种更科学的用于描述变量作用域的名称,即命名空间(namespace)。任何在函数中赋值的变量默认都是被分配到局部命名空间(local namespace)中的。局部命名空间是在函数被调用时创建的,函数参数会立即填入该命名空间。在函数执行完毕之后,局部命名空间就会被销毁(会有一些例外的情况,具体请参见后面介绍闭包的那一节).
但是这样会造成一些问题,比如在C语言中,由于变量一定是先声明,后使用,所以我们可以清楚的知道,现在使用的变量是全局还是局部.比如:
int a = 5;
void test(void)
{
a = 1; // 没有先声明,所以用的是全局的变量a
}
void test1(void)
{
int a;
a = 2; // 前面声明了,所以用的是局部变量a,对其所做的修改不会影响全局变量a
}
但是在python中,变量不需要先声明,直接使用即可,那我们怎么知道用的是局部变量还是全局变量呢?
首先:python使用的变量,在默认情况下一定是用局部变量.
其次:python如果想使用作用域之外的全局变量,则需要加global前缀.
#不使用global的情况
a = 5
def test():
a = 1
print(f'In test func: a = {a}')
test()
print(f'Global a = {a}')
In test func: a = 1
Global a = 5
#使用global的情况
a = 5
def test():
global a
#此处声明,告诉执行引擎:我要用全局变量a,不要整成局部的了!
a = 1
print(f'In test func: a = {a}')
test()
print(f'Global a = {a}')
In test func: a = 1
Global a = 1
3.2.2 返回多个值
在数据分析和其他科学计算应用中,你会发现自己常需要返回多个值。但函数其实只返回了一个对象,也就是一个元组,最后该元组会被拆包到各个结果变量中.
def f():
a = 5
b = 6
c = 7
return a, b, c
a, b, c = f()
print(a,b,c)
5 6 7
此外,还有一种非常具有吸引力的多值返回方式——返回字典,取决于工作内容,第二种方法可能很有用.
def f():
a = 5
b = 6
c = 7
return {'a' : a, 'b' : b, 'c' : c}
print(f())
{'a': 5, 'b': 6, 'c': 7}
3.2.3 函数是对象
由于Python函数都是对象,因此,在其他语言中较难表达的一些设计思想在Python中就要简单很多了。假设我们有下面这样一个字符串数组,希望对其进行一些数据清理工作并执行一堆转换:
states = [' Alabama ', 'Georgia!', 'Georgia', 'georgia', 'FlOrIda','south carolina##', 'West virginia?']
不管是谁,只要处理过由用户提交的调查数据,就能明白这种乱七八糟的数据是怎么一回事。为了得到一组能用于分析工作的格式统一的字符串,需要做很多事情:去除空白符、删除各种标点符号、正确的大写格式等。做法之一是使用内建的字符串方法和正则表达式re模块.
之前看到Python基础书并没有介绍Re,这里写一些定义,也可以直接参考链接:
3.2.3.1 re
Re库是Python的标准库,主要用于字符串匹配,调用方法"import re"
(1) 正则表达式的类型
Re库采用raw string(原生字符串类型)表达正则表达式,表示为r'text',raw string是不包含转义符的字符串
如 r'[1-9]\d{5}'、r'\d{3}-\d{8}|\d{4}-\d{7}'
如果直接用String表示,还需要转义符:
'[1-9]\d{5}'、'\d{3}-\d{8}|\d{4}-\d{7}'
(2) \(re\)库的主要函数
- re.sub(pattern,repl,string,count = 0,flags = 0)
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
① pattern:正则表达式的字符串或原生字符串表示
② repl:替换匹配字符串的字符串
③ string:待匹配字符串
④ count:匹配的最大替换次数
⑤ flags:正则表达式使用时的控制标记
import re
re.sub(r'[1-9]\d{5}','zipcode','BIT100081 TSU100084')
#'BITzipcode TSUzipcode'
'BITzipcode TSUzipcode'
这里只介绍要用的,详细上面的链接
现在来看如何清洗数据
def clean_strings(strings):
result = []
for value in strings:
value = value.strip()
value = re.sub('[!#?]','',value)
value = value.title()
result.append(value)
return result
clean_strings(states)
['Alabama',
'Georgia',
'Georgia',
'Georgia',
'Florida',
'South Carolina',
'West Virginia']
其实还有另外一种不错的办法:将需要在一组给定字符串上执行的所有运算做成一个列表:
states = [' Alabama ', 'Georgia!', 'Georgia', 'georgia', 'FlOrIda','south carolina##', 'West virginia?']
def remove_punctuation(value):
return re.sub('[!#?]','',value)
clean_ops = [str.strip,remove_punctuation,str.title]
def clean_strings(strings,ops):
result = []
for string in strings:
for fun in ops:
string = fun(string)
result.append(string)
return result
clean_strings(states,clean_ops)
['Alabama',
'Georgia',
'Georgia',
'Georgia',
'Florida',
'South Carolina',
'West Virginia']
这种多函数模式使你能在很高的层次上轻松修改字符串的转换方式。此时的clean_strings也更具可复用性!
还可以将函数用作其他函数的参数,比如内置的map函数,它用于在一组数据上应用一个函数:
states = [' Alabama ', 'Georgia!', 'Georgia', 'georgia', 'FlOrIda','south carolina##', 'West virginia?']
for x in map(remove_punctuation, states):
print(x)
Alabama
Georgia
Georgia
georgia
FlOrIda
south carolina
West virginia
3.2.4 匿名函数
Python支持一种被称为匿名的、或lambda函数。它仅由单条语句组成,该语句的结果就是返回值。它是通过lambda关键字定义的,这个关键字没有别的含义,仅仅是说"我们正在声明的是一个匿名函数"。
下面是lambda的语法格式
name = lambda [参数list] : 表达式
举一个例子,如果设计一个求 2 个数之和的函数,使用普通函数的方式,定义如下:
def add(x, y):
return x+y
print(add(3,4))
7
但如果我们使用lambda函数,可以将代码缩减为1行:
add = lambda x,y : x+y
add(3,4)
7
Lambda函数可以具有任意数量的参数,但只能有一个表达式.表达式被求值并返回.Lambda函数可在需要函数对象的任何地方使用.等式左边返回的是函数对象.
在Python中,我们通常将其用作高阶函数的参数,Lambda函数可以与filter(),map()等内置函数一起使用.
#按字符串字母数量种类排序
strings = ['foo', 'card', 'bar', 'aaaa', 'abab']
#set()只接受list和tuple或其他可迭代对象作为参数,因为它只存储不可变的数据类型,为什么允许接受list:是将List的元素划为自己的元素
#但如果list存在可变的类型,那么也会报错
strings.sort(key = lambda x : len(set(list(x))))
strings
['aaaa', 'foo', 'abab', 'bar', 'card']
3.2.5 柯里化:部分参数应用
柯里化(currying)是一个有趣的计算机科学术语,它指的是通过“部分参数应用”(partial argument application)从现有函数派生出新函数的技术.详情看这个,更详细
3.2.6 生成器
能以一种一致的方式对序列进行迭代(比如列表中的对象或文件中的行)是Python的一个重要特点.这是通过一种叫做迭代器协议(iterator protocol,它是一种使对象可迭代的通用方式)的方式实现的,一个原生的使对象可迭代的方法。比如说,对字典进行迭代可以得到其所有的键:
some_dict = {'a': 1, 'b': 2, 'c': 3}
for key in some_dict:
print(key)
a
b
c
当你编写for key in some_dict时,Python解释器首先会尝试从some_dict创建一个迭代器:
dict_iterator = iter(some_dict)
dict_iterator
<dict_keyiterator at 0x1c621ac7ea0>
迭代器与生成器的解释看这个
顾名思义,迭代器就是用于迭代操作(for)的对象,它像列表一样可以迭代获取其中的每一个元素,任何实现了 next 方法 (python2 是 next)的对象都可以称为迭代器.
它与列表的区别在于,构建迭代器的时候,不像列表把所有元素一次性加载到内存,而是以一种延迟计算(lazy evaluation)方式返回元素,这正是它的优点.比如列表含有中一千万个整数,需要占超过400M的内存,而迭代器只需要几十个字节的空间.因为它并没有把所有元素装载到内存中,而是等到调用next方法时候才返回该元素(按需调用 call by need 的方式,本质上 for 循环就是不断地调用迭代器的next方法).
大部分能接受列表之类的对象的方法也都可以接受任何可迭代对象。比如min、max、sum等内置方法以及list、tuple等类型构造器:
list(dict_iterator)
['a', 'b', 'c']
- 生成器
这方面还是继续看知乎比较好.
知道迭代器之后,就可以正式进入生成器的话题了。普通函数用return返回一个值,和 Java 等其他语言是一样的,然而在Python中还有一种函数,用关键字yield来返回值,这种函数叫生成器函数,函数被调用时会返回一个生成器对象,生成器本质上还是一个迭代器,也是用在迭代操作中,因此它有和迭代器一样的特性,唯一的区别在于实现方式上不一样,后者更加简洁.
一般的函数执行之后只会返回单个值,而生成器则是以延迟的方式返回一个值序列,即每返回一个值之后暂停,直到下一个值被请求时再继续。要创建一个生成器,只需将函数中的return替换为yeild即可:
def squares(n=10):
print('Generating squares from 1 to {0}'.format(n ** 2))
for i in range(1, n + 1):
yield i ** 2
调用该生成器时,没有任何代码会被立即执行:
gen = squares()
gen
<generator object squares at 0x000001C621336970>
直到你从该生成器中请求元素时,它才会开始执行其代码:
这里感觉延迟执行,每返回一个值就暂停,可能这就是在for循环里返回值的原因
for x in gen:
print(x,end=' ')
Generating squares from 1 to 100
1 4 9 16 25 36 49 64 81 100
3.2.6.1 生成器表达式
另一种更简洁的构造生成器的方法是使用生成器表达式(generator expression)。这是一种类似于列表、字典、集合推导式的生成器。其创建方式为,把列表推导式两端的方括号改成圆括号:
gen = (x**2 for x in range(100))
gen
<generator object <genexpr> at 0x000001C6233476D0>
它跟下面这个冗长得多的生成器是完全等价的:
def _make_gen():
for x in range(100):
yield x ** 2
gen = _make_gen()
gen
<generator object _make_gen at 0x000001C6233479E0>
生成器表达式也可以取代列表推导式,作为函数参数:
dict(((i,i**2) for i in range(6)))#实际包裹生成器表达式的括号不需要
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
3.2.6.2 itertools 模块
课本上的解释不是很白话,然后参考了几个博客,概况如下:
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数,其主要分为三类:分别是无限迭代器,有限迭代器,组合迭代器.
(1) 无限迭代器
这些函数可以生成无限的迭代器,我们主要学习以下三个函数的用法
- count([start=0, step=1])
接收两个可选整形参数,第一个指定了迭代开始的值,第二个指定了迭代的步长.此外,start参数默认为0,step参数默认为1,可以根据需要来把这两个指定为其它值,或者使用默认参数.
下面的代码,如果没有break,会一直迭代下去
import itertools
for i in itertools.count(10,2):
print(i)
if i>20:
break
10
12
14
16
18
20
22
- cycle(iterable)
是用一个可迭代对象中的元素来创建一个迭代器,并且复制自己的值,一直无限的重复下去。
for i in itertools.cycle("abc"):
print(i)
break
a
- repeat(elem [,n])
是将一个元素重复n遍或者无穷多遍,并返回一个迭代器
for i in itertools.repeat("abcd",5):
print(i)
abcd
abcd
abcd
abcd
abcd
(2) 组合迭代器
组合操作包括排列,笛卡儿积,或者一些离散元素的选择,组合迭代器就是产生这样序列的迭代器。我们来看看这几个函数的用法.
- product(iterables, repeat=1)
得到的是可迭代对象的笛卡儿积,iterables参数表示需要多个可迭代对象.这些可迭代对象之间的笛卡儿积,也可以使用for循环来实现,例如product(A,B)与((x,y) for x in A for y in B)就实现一样的功能
for i in itertools.product([1,2,3],[4,5,6]):
print(i)
(1, 4)
(1, 5)
(1, 6)
(2, 4)
(2, 5)
(2, 6)
(3, 4)
(3, 5)
(3, 6)
而repeat参数则表示这些可迭代序列重复的次数.例如 product(A, repeat=4)与 product(A,A,A,A)实现的功能一样.
- permutations(iterable,r=None)
返回的是可迭代元素中的一个排列组合,并且是按顺序返回的,且不包含重复的结果.
for i in itertools.permutations('abc'):
print(i)
('a', 'b', 'c')
('a', 'c', 'b')
('b', 'a', 'c')
('b', 'c', 'a')
('c', 'a', 'b')
('c', 'b', 'a')
当然,第2个参数默认为None,它表示的是返回元组(tuple) 的长度,我们来尝试一下传入第二个参数:
for i in itertools.permutations('abc',2):
print(i)
('a', 'b')
('a', 'c')
('b', 'a')
('b', 'c')
('c', 'a')
('c', 'b')
- combinations(iterable,r)
返回的是可迭代对象所有的长度为 r 的子序列,注意这与前一个函数 permutation 不同,permutation 返回的是排列,而 combinations 返回的是组合
for i in itertools.combinations('1234',2):
print(i)
('1', '2')
('1', '3')
('1', '4')
('2', '3')
('2', '4')
('3', '4')
- combinations_with_replacement(iterable, r)
返回一个可与自身重复的元素组合,用法类似于 combinations
for i in itertools.combinations_with_replacement('1234',2):
print(i)
('1', '1')
('1', '2')
('1', '3')
('1', '4')
('2', '2')
('2', '3')
('2', '4')
('3', '3')
('3', '4')
('4', '4')
(3) 有限迭代器
这里的函数有十来个,主要介绍其中几个常用的函数:
- chain(*iterables)
可以把多个可迭代对象组合起来,形成一个更大的迭代器
print(itertools.chain([1,2,3],[4,5]))
<itertools.chain object at 0x000001C621D85F10>
for i in itertools.chain([1,3],[4,5]):
print(i)
1
3
4
5
- groupby(iterable,key=None)
可以把相邻元素按照key函数分组,并返回相应的key和groupby,如果key函数为None,则只有相同的元素才能放在一组
names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven']
for letter, names in itertools.groupby(names, lambda x:x[0]):
print(letter, list(names)) # names is a generator
A ['Alan', 'Adam']
W ['Wes', 'Will']
A ['Albert']
S ['Steven']
- accumulate(iterable [,func])
可以计算出一个迭代器,这个迭代器是由特定的二元函数的累计结果生成的,如果不指定的话,默认函数为求和函数
for i in itertools.accumulate([0,1,0,1,1,2,3,5]):
print(i)
0
1
1
2
3
5
8
13
3.2.7 错误和异常
使用try-catch-else-finally处理异常或错误
path = 'D:/Python_Code/IPython/Chapter_3/1.txt'
f = open(path,'w')
try:
write_to_file(f)
except (TypeError,ValueError,NameError,PermissionError):
#except多个异常以元组形式
print('Failed')
else:
print('Succeeded')
finally:
f.close()
Failed
3.3 文件和操作系统
本书的代码示例大多使用诸如pandas.read_csv之类的高级工具将磁盘上的数据文件读入Python数据结构。但我们还是需要了解一些有关Python文件处理方面的基础知识。好在它本来就很简单,这也是Python在文本和文件处理方面的如此流行的原因之一。
为了打开一个文件以便读写,可以使用内置的open函数以及一个相对或绝对的文件路径:
path = 'examples/segismundo.txt'
f = open(path)
默认情况下,文件是以只读模式('r')打开的。然后,我们就可以像处理列表那样来处理这个文件句柄f了,比如对行进行迭代:
for line in f:
print(line)
Sue帽a el rico en su riqueza,
que m谩s cuidados le ofrece;
sue帽a el pobre que padece
su miseria y su pobreza;
sue帽a el que a medrar empieza,
sue帽a el que afana y pretende,
sue帽a el que agravia y ofende,
y en el mundo, en conclusi贸n,
todos sue帽an lo que son,
aunque ninguno lo entiende.
从文件中取出的行都带有完整的行结束符(EOL),因此你常常会看到下面这样的代码(得到一组没有EOL的行):
lines = [x.rstrip() for x in open(path)]
lines
['Sue帽a el rico en su riqueza,',
'que m谩s cuidados le ofrece;',
'',
'sue帽a el pobre que padece',
'su miseria y su pobreza;',
'',
'sue帽a el que a medrar empieza,',
'sue帽a el que afana y pretende,',
'sue帽a el que agravia y ofende,',
'',
'y en el mundo, en conclusi贸n,',
'todos sue帽an lo que son,',
'aunque ninguno lo entiende.',
'']
如果使用open创建文件对象,一定要用close关闭它。关闭文件可以返回操作系统资源:
f.close()
用with语句可以可以更容易地清理打开的文件:
with open(path) as f:
lines = [x.rstrip() for x in f]
lines
['Sue帽a el rico en su riqueza,',
'que m谩s cuidados le ofrece;',
'',
'sue帽a el pobre que padece',
'su miseria y su pobreza;',
'',
'sue帽a el que a medrar empieza,',
'sue帽a el que afana y pretende,',
'sue帽a el que agravia y ofende,',
'',
'y en el mundo, en conclusi贸n,',
'todos sue帽an lo que son,',
'aunque ninguno lo entiende.',
'']
这样可以在退出代码块时,自动关闭文件。
如果输入f =open(path,'w'),就会有一个新文件被创建在examples/segismundo.txt,并覆盖掉该位置原来的任何数据。另外有一个x文件模式,它可以创建可写的文件,但是如果文件路径存在,就无法创建。表3-3列出了所有的读/写模式。

我们可以用sys查看默认编码:
import sys
sys.getdefaultencoding()
'utf-8'
对于可读文件,一些常用的方法是read、seek和tell。read会从文件返回字符。字符的内容是由文件的编码决定的(如UTF-8),如果是二进制模式打开的就是原始字节:
f = open(path)
f.read(10)
'Sue帽a el r'
f2 = open(path, 'rb') # Binary mode
f2.read(10)
b'Sue\xc3\xb1a el '
read模式会将文件句柄的位置提前,提前的数量是读取的字节数。tell可以给出当前的位置:
print(f.tell(),f2.tell())
11 10
尽管我们从文件读取了10个字符,位置却是11,这是因为用默认的编码用了这么多字节才解码了这10个字符。你可以用sys模块检查默认的编码.
seek将文件位置更改为文件中的指定字节:
f.seek(3)
3
f.read(1)
'帽'
f.close()
f2.close()
向文件写入,可以使用文件的write或writelines方法。例如,我们可以创建一个无空行版的prof_mod.py:
with open('tmp.txt', 'w') as handle:
handle.writelines(x for x in open(path) if len(x) > 1)
with open('tmp.txt') as f:
lines = f.readlines()
lines
['Sue帽a el rico en su riqueza,\n',
'que m谩s cuidados le ofrece;\n',
'sue帽a el pobre que padece\n',
'su miseria y su pobreza;\n',
'sue帽a el que a medrar empieza,\n',
'sue帽a el que afana y pretende,\n',
'sue帽a el que agravia y ofende,\n',
'y en el mundo, en conclusi贸n,\n',
'todos sue帽an lo que son,\n',
'aunque ninguno lo entiende.\n']
表3-4列出了一些最常用的文件方法:
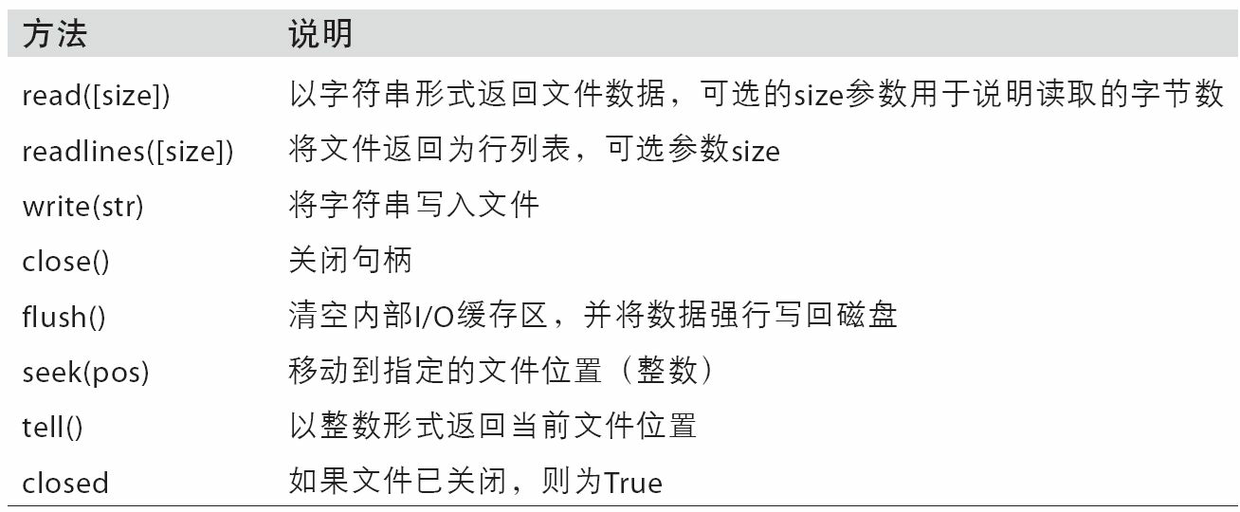

 浙公网安备 33010602011771号
浙公网安备 33010602011771号