
随笔分类 - 机器学习 / 李宏毅
摘要:1. 实验 1.1 背景介绍 根据输入音频判断是哪个讲话者. 1.2 数据集 数据集采用的是\(VoxCeleb2\).可以看这个Click了解数据集. 1.2.1 Data formats 目录下有三个json文件和很多pt文件,三个json文件作用标注在下图中,pt文件就是语音内容.其中,n_m
阅读全文
摘要:# 1. Introduction(引入) 词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用. 最经典的做法就是1-of-N Encoding,它指的就是每一个字都是以向量来表示,只有在自己所属的那个字词索引上为1,其余为0,因此如果世界上的英文字
阅读全文
摘要:# 1. Introduction GNN简单来说就是Graph + Nerual Networks,关键问题就是将图的结构和图中每个节点和边的特征转化为一般的神经网络的输入(张量). .比如有一个人对订票系统说“I would like to arrive Taipei on November 2nd”,那么系统要自动识别出Taipei属于Destination这个slot,Novembe
阅读全文
摘要:# 1. 问题引入 我们在之前的课程里遇到的都是输入是一个向量,输出是类别或者标量.但如果输入是向量的集合且向量长度还会变化,又应该怎么处理呢?  ## 1.2 输出文件格式 两列,一列
阅读全文
摘要:# 请复习线性代数 # 1. Spatial Transformer Layer ## 1.1 CNN is not invariant to scaling and rotation (1) CNN并不能真正做到scaling和rotation. (2) 如下图所示,在通常情况下,左右两边的图片对
阅读全文
摘要:# 1. 问题回顾 在上节的再谈宝可梦、数码宝贝分类问题上,我们提出了机器学习的分类原理.并提出了一个矛盾点:当可选参数过多,loss会变小,但理想和现实差距会很大;当可选参数比较少,loss会变大,但理想和现实差距会减小.现在我们需要一个Loss小,可选参数也少的模型.  # 2. What is
阅读全文
摘要:# 1. 概念引入: Image Classification ## 1.1 基本步骤 我们做图像分类时,一般分为三步: * 所有图片都先 rescale 成大小一样 * 把每一个类别表示成一个 one-hot vector(dimension 的长度决定模型可以辨识出多少不同种类的东西) * 将图
阅读全文
摘要:# 1. 提出背景 在前文,我们提过$error\ surface$在不同方向的斜率不一样,因此采用固定的学习率很难将模型$train$起来,上节提出了自适应学习率,这里还有一个方法就是直接将e$rror\ surface$铲平. 或许首先想要提出的是为什么会产生不同方向上斜率相差很大的现象.观察下
阅读全文
摘要:# 1. 实验结果纪录 纪录一下调整参数带来的结果.不过语音识别这块完全不熟. ## 1.1 Simple Baseline * **acc>0.45797** 直接上传助教代码  ## 1.1 为什么需要调整学习率 首先认识一个现象.Training stuck ≠ Small Gradient 训练卡住的原因不一定是因为 gradient 太小,即critical point,也有可能是因为振荡.
阅读全文
摘要:# 1. Batch(批次) > 对抗临界点的两个方法就是batch 和 momentum 将一笔大型资料分若干批次计算 loss 和梯度,从而更新参数.每看完一个epoch就把这笔大型资料打乱(shuffle),然后重新分批次.这样能保证每个epoch中的 batch 资料不同,避免偶然性. >
阅读全文
摘要:# 1. When gradient is small 本小节主要讨论优化器造成的训练问题. ## 1.1 Critical Point(临界点) 如果训练过程中经过很多个epoch后,loss还是不下降,那么可能是因为梯度(斜率)接近于 0,导致参数更新的步伐接近于0,所以参数无法进一步更新,lo
阅读全文
摘要:# 1. Framework of ML 训练的过程之前已经讲过了,训练主要是三个步骤. 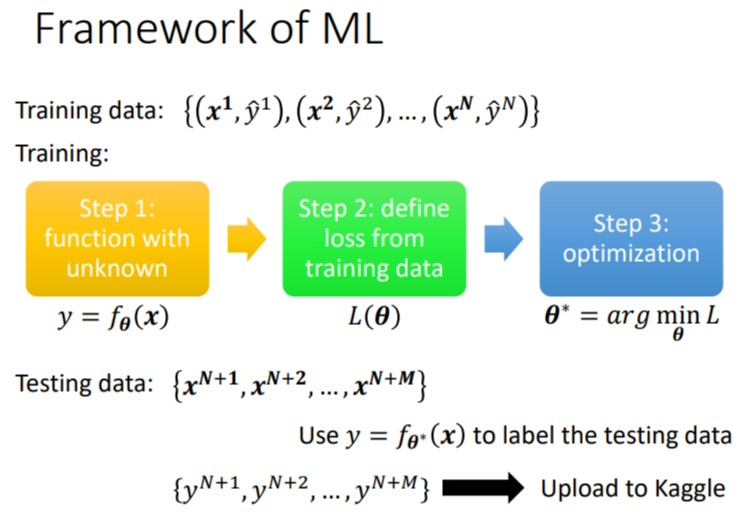 * 第一步,你
阅读全文
摘要:# 1. 逻辑回归 下面是这位大佬的[Click](https://blog.csdn.net/weixin_44406200/article/details/104288916).逻辑回归是用于分类的算法,它是在线性回归的基础上添加了一层映射. ![image](https://img2023.c
阅读全文