后缀数组(SA)
Update 2020.1.7
看了 oiwiki 忽然发现自己的模板代码是那样的丑陋,常数是那样的大,重新打了一遍。之前交的题都变快了,开心!
定义
\(S\):需要处理的字符串,长度为 \(len\)
\(suf_i\):字符串\(S\)中下标为 \(i \sim len\) 的连续子串(即后缀)
\(rank_i\):\(suf_i\)在所有后缀中的排名
\(SA_i\):后缀数组,排名为\(i\)的后缀在原串中的位置,满足 \(suf_{SA_1} < suf_{SA_2} < \dots < suf_{SA_{len}}\),与 \(rank_i\) 为互逆运算
\(height_i\):高度数组,排名相邻的两个后缀的最长公共前缀长度。
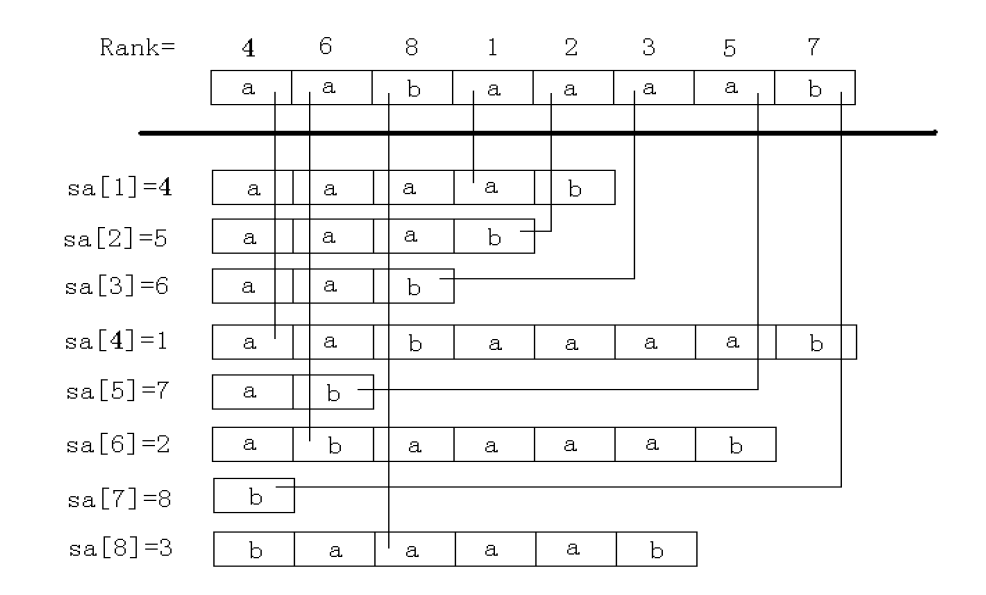
后缀数组的构造
倍增算法
倍增算法的主要思路是,每次利用上一次的结果,倍增计算出每个位置从 \(i\) 开始的长度为 \(2^k\) 的子串的排名。
例如,在算法的开始,我们有 "aabaaaab" ,长度为 \(2^0=1\) 的子串的排名分别为:
| \(S_i\) | a | a | b | a | a | a | a | b |
|---|---|---|---|---|---|---|---|---|
| \(rank_i\) | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 |
然后,为了求出长度为 \(2^1=2\) 的子串的排名,我们以每个位置 \(i\) 开始,长度为 \(2^0=1\) 的子串的排名作为位置 \(i\) 的第一关键字,以每个位置 \(i\) 开始,长度为 \(2^0=1\) 的子串的排名作为位置 \(i\) 的第二关键字,进行双关键字排序。
接下来,以此类推即可。
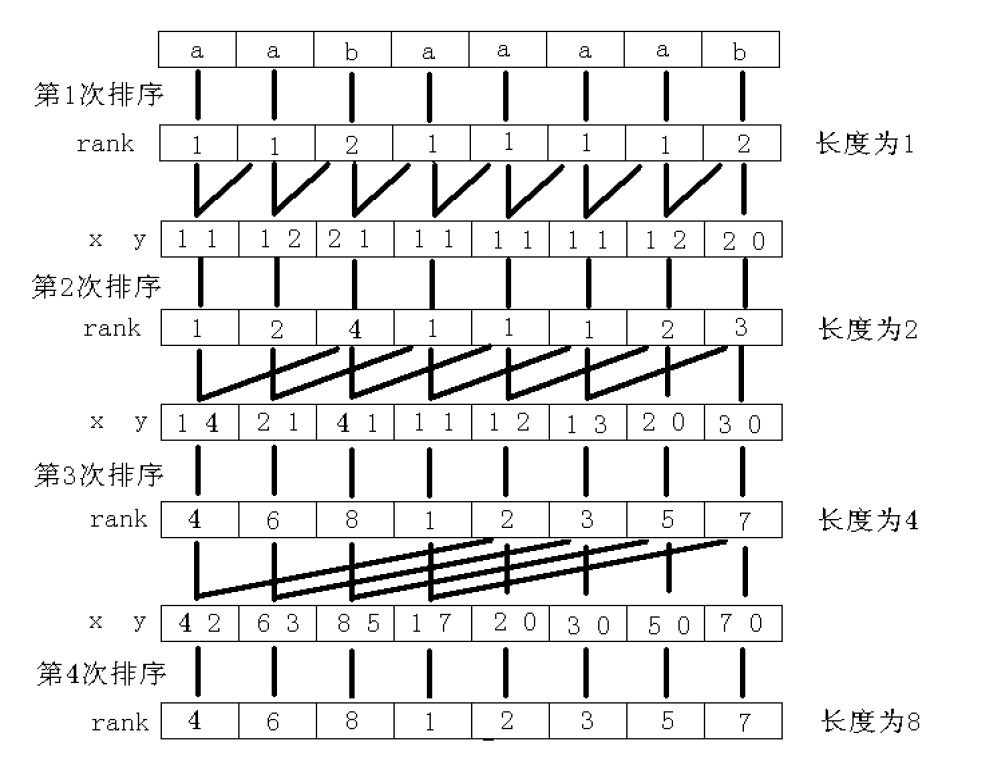
如果使用使用快速排序,那么复杂度将是 \(O(N\log^2 N)\) ,所以,我们在这里使用基数排序,复杂度将降为 \(O(N\log N)\)。
Code
inline void SA() {
int M = 122, p = 0; // 字符集
static int buc[_], id[_], fir[_], oldrk[_];
static char t[_];
copy(s + 1, s + N + 1, t + 1);
sort(t + 1, t + N + 1);
char *end = unique(t + 1, t + N + 1);
for (int i = 1; i <= N; ++i) s[i] = lower_bound(t + 1, end, s[i]) - t;
for (int i = 1; i <= N; ++i) ++buc[rk[i] = s[i]];
for (int i = 1; i <= M; ++i) buc[i] += buc[i - 1];
for (int i = N; i >= 1; --i) sa[buc[rk[i]]--] = i;
for (int len = 1; len < N; len <<= 1, M = p) {
p = 0;
for (int i = N; i > N - len; --i) id[++p] = i;
for (int i = 1; i <= N; ++i)
if (sa[i] > len) id[++p] = sa[i] - len;
fill(buc + 1, buc + M + 1, 0);
for (int i = 1; i <= N; ++i) ++buc[fir[i] = rk[id[i]]];
for (int i = 1; i <= M; ++i) buc[i] += buc[i - 1];
for (int i = N; i >= 1; --i) sa[buc[fir[i]]--] = id[i];
copy(rk + 1, rk + N + 1, oldrk + 1);
p = 0;
for (int i = 1; i <= N; ++i) {
if (i == 1) rk[sa[i]] = ++p;
else {
int x = sa[i], y = sa[i - 1];
rk[sa[i]] = (oldrk[x] == oldrk[y] && oldrk[x + len] == oldrk[y + len]) ? p : ++p;
}
}
if (p == N) break;
}
}
DC3算法
不会。
高度数组的构造
如果直接按照定义构造高度数组,那么时间复杂度是 \(O(N^2)\),难以承受,这就需要利用到高度数组的一个性质:
令 \(h_i\) 表示表示从第 \(i\) 个位置开始的后缀与排在其前一名的后缀的最长公共前缀,即当 \(rank_i>0\) 时
对于 \(h_i\),有一个结论
证明(来自\(\mathrm{hihoCoder}\))
设 \(suf_k\) 是排在前 \(suf_{i-1}\)前 一名的后缀,
则它们的最长公共前缀是 \(h_{i-1}\)
那么将 \(suf_{k+1}\) 排在 \(suf_i\) 的前面
并且 \(suf_{k+1}\) 和 \(suf_i\) 的最长公共前缀是 \(h_{i-1}-1\) ,
所以 \(suf_i\) 和在它前一名的后缀的最长公共前缀至少是 \(h_{i-1}-1\)
Code
有了上面的性质,我们可以按照 \(height_{SA_i}\) 的顺序递推。 设 \(k=height_{rank_{i-1}}\) ,显然在计算每个 \(height_{rank_i}\) 时,\(k\) 每次减小\(1\) ,最多增加到 \(n\) ,所以这个过程的时间复杂度为 \(O(n)\)。
for (int i = 1, k = 0; i <= N; ++i) {
if (rnk[i] == 1)
k = 0;
else {
if (k > 0) --k;
int j = sa[rnk[i] - 1];
while (i + k <= N && j + k <= N && a[i + k] == a[j + k]) ++k;
}
height[rnk[i]] = k;
}
最长公共前缀
通过高度数组 \(height_i\),我们可以得到排名相邻的两个后缀的最长公共前缀。
对于排名不相邻的两个后缀,它们的前缀的相似性比相邻后缀要差。显然排名不相邻的两个后缀的最长公共前缀长度一定不会比这两个后缀在后缀数组中确定的一段区间中任意两个相邻后缀的最长公共前缀长度更长。
所以,求出这段区间内最小的 \(height\) 值即为这两个不相邻后缀的最长公共前缀长度。
问题转化为 \(RMQ\) 问题,可以使用 \(ST\) 表解决。
模板
#include <bits/stdc++.h>
using namespace std;
const int _ = 1e6 + 10;
int N, rnk[_], sa[_], height[_];
char s[_];
inline void SA() {
int M = 122, p = 0; // 字符集
static int buc[_], id[_], fir[_], oldrk[_];
static char t[_];
copy(s + 1, s + N + 1, t + 1);
sort(t + 1, t + N + 1);
char *end = unique(t + 1, t + N + 1);
for (int i = 1; i <= N; ++i) s[i] = lower_bound(t + 1, end, s[i]) - t;
for (int i = 1; i <= N; ++i) ++buc[rk[i] = s[i]];
for (int i = 1; i <= M; ++i) buc[i] += buc[i - 1];
for (int i = N; i >= 1; --i) sa[buc[rk[i]]--] = i;
for (int len = 1; len < N; len <<= 1, M = p) {
p = 0;
for (int i = N; i > N - len; --i) id[++p] = i;
for (int i = 1; i <= N; ++i)
if (sa[i] > len) id[++p] = sa[i] - len;
fill(buc + 1, buc + M + 1, 0);
for (int i = 1; i <= N; ++i) ++buc[fir[i] = rk[id[i]]];
for (int i = 1; i <= M; ++i) buc[i] += buc[i - 1];
for (int i = N; i >= 1; --i) sa[buc[fir[i]]--] = id[i];
copy(rk + 1, rk + N + 1, oldrk + 1);
p = 0;
for (int i = 1; i <= N; ++i) {
if (i == 1) rk[sa[i]] = ++p;
else {
int x = sa[i], y = sa[i - 1];
rk[sa[i]] = (oldrk[x] == oldrk[y] && oldrk[x + len] == oldrk[y + len]) ? p : ++p;
}
}
if (p == N) break;
}
for (int i = 1, k = 0; i <= N; ++i) {
if (rk[i] == 1) k = 0;
else {
if (k > 0) --k;
int j = sa[rk[i] - 1];
while (i + k <= N && j + k <= N && s[i + k] == s[j + k]) ++k;
}
height[rk[i]] = k;
}
}
应用
最长可重叠重复K次子串问题
重复出现了 \(k\) 次,相当于我们选择了 \(k\) 个后缀,求他们的 \(lcp\)。
显然 \(k\) 个后缀的 \(rank\) 是连续的,所以重复出现 \(k\) 次的前缀就是 \(min(height[l+1\dots l+k-1])\)。
所以我们需枚举 \(i\),然后用一个递增的单调队列维护 \(height[i-k+2\dots i]\) 即可。
最长不可重叠重复子串问题
如果有两个子串相同,那么也就是有两个后缀的 \(lcp\) 相同。
所以考虑二分答案 \(K\),如果有连续一段的 \(height\) 都不小于 \(K\),那么这一段区间内,两两后缀的 \(lcp\) 都不小于 \(K\),那么记录一下区间的 \(\max\{sa_i\}\) 和 \(\min\{sa_i\}\),如果 \(\max\{sa_i\}-\min\{sa_i\}\ge K\),那么就说明两个子串不重叠。
最长公共子串问题
考虑将这若干个串全部拼起来,中间用一些不在字符集内的符号隔开。
然后二分答案 \(K\),如果连续的一段 \(height\) 都大于等于 \(K\),且每个串都出现了至少一次,则是可行的。
Update 2018.1.8:
其实并没有必要二分答案,我们可以枚举左端点,然后不断向右扩展右端点,当每种串都出现恰好至少一次时,就对把答案和这一段区间的 \(\min\) 取个 \(\max\),然后区间的 \(\min\) 用单调队列维护即可。
POJ2774 Long Long Message(两个串的最长公共子串)

