Kaggle:House Prices
Kaggle:House Prices
数据处理
首先是处理数据,导入相应的包,使用pandas读取csv文件,并指定Id列为index,本身Id这一列也不携带预测信息。同时将训练数据和测试数据拼接在一起以便后续的处理。
train_data = pd.read_csv("dataset/train.csv", index_col="Id") #
test_data = pd.read_csv("dataset/test.csv", index_col="Id")
all_features = pd.concat((train_data.iloc[:, :-1], test_data)) #
将数据粗略地分为两类,一类是连续的数值类型,一类是离散的类型。
对于数值类型的数据,进行零均值和单位方差的标准化处理,同时把缺失值NaN置为0。
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)
对于离散数据,使用get_dummies()函数,将它们转换成对应的独热编码。
all_features = pd.get_dummies(all_features, dummy_na=True)
最后,提取出训练特征、训练标签和测试特征集,转换成Tensor对象,并使用Dataloader进行batch。
num_train = train_data.shape[0]
train_features = torch.tensor(all_features[:num_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[num_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1,1), dtype=torch.float32)
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True)
定义模型、损失和优化
定义一个简单的线性模型作为基线(baseline)模型,可以用以衡量之后较复杂模型的性能。
loss = nn.MSELoss()
in_features = train_features.shape[1] # 输入特征的数量
# 定义一个简单的线性模型作为基线(baseline)模型
def get_net():
net = nn.Sequential(nn.Linear(in_features, 1))
return net
对于房价的预测的误差,我们更关心相对误差而不是绝对误差。因为不同房价的价格尺度可能很大。比如对于12w的价格我们预测偏差为10w,那么模型的表现就很糟糕;如果对于500w的价格偏差为10w,那么这样的偏差是可以接受的。
因此这里,将使用对数尺度来衡量误差(可以想象以下对数函数的图像)。损失函数为:
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
训练和预测
通过迭代构建训练函数
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay):
train_ls, test_ls = [], []
optimizer = torch.optim.Adam(net.parameters(),
lr=learning_rate, weight_decay=weight_decay)
for epoch in range(num_epochs):
for X, y in loader:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
由于数据量也比较小,还需要剥离一部分数据作为开发集进行验证,可以采用K交叉验证。具体实现如下:
# 将数据分为k-1份和 1份两部分
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls], xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs], legend=['train', 'valid'], yscale='log')
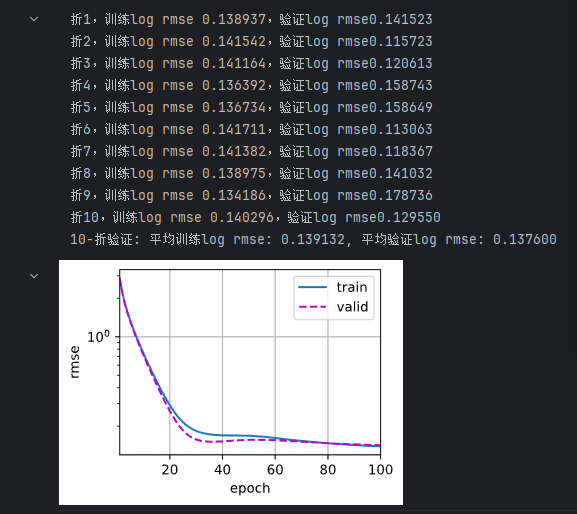
print(f'折{i+1},训练log rmse {float(train_ls[-1]):f},' f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
训练,并输出相关信息。
k, num_epochs, lr, weight_decay = 10, 100, 5, 0
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
训练模型后,输出预测信息并保存到csv文件中,用以提交。
def train_and_pred(train_freatures, test_features, train_labels, test_data,
num_epoches, lr, weight_decay):
net = get_net()
train_ls, _ = train(net,train_freatures, train_labels,None, None, num_epochs, lr, weight_decay)
d2l.plot(np.arange(1, num_epoches+1), [train_ls], xlabel='epoch', ylabel='log rmse', xlim=[1, num_epochs], legend=['train', 'valid'], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
preds = net(test_features).detach().numpy()
x = pd.Series(preds.reshape(1, -1)[0])
print(x.values)
# 通过values获得预测值这一列,并保存到test_data中
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0]).values
#submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission = test_data['SalePrice']
submission.to_csv('submission.csv', index=True)
train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay)
运用DenseNet的思想
运用DenseNet的思想设计多层感知机模型,看看效果如何。
DenseNet主要由两部分组成dense block和transition layer,前者用于定义如何连接输入和输出,后者用于控制通道数。
由于在本例中,每个特征样本都是一个列向量,所以也就用不到transition layer。按照dense的理念,我们需要构建一个简单的dense block,能将线性层的输入和输出连接起来作为下一层的输入即可。
下面的代码定义了由四个dense block构成的模型。
def linear_block(input_features, out_features):
return nn.Sequential(
nn.BatchNorm1d(input_features), nn.ReLU(),
nn.Linear(input_features, out_features)
)
# 定义稠密块
class DenseBlock(nn.Module):
def __init__(self, num_linear, input_features, num_features):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_linear):
layer.append(linear_block(i * num_features + input_features, num_features))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
y = blk(X)
X = torch.cat((X, y), 1)
return X
def get_dense_linear_net():
linear_prev = nn.Sequential(
nn.Linear(in_features, 64),
nn.BatchNorm1d(64), nn.ReLU(),
)
num_features, growth_rate = 64, 32
num_linear_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_linear in enumerate(num_linear_in_dense_blocks):
blks.append(DenseBlock(num_linear, num_features, growth_rate))
num_features += num_linear * growth_rate
net = nn.Sequential(
linear_prev, *blks,
nn.Dropout(0.2),
nn.Linear(num_features, 1))
return net
在k折交叉验证函数这块,调用上述构建的含有dense block的网络即可。其余部分都一样。
def k_fold_dense(...)
...
net = get_dense_linear_net()
...
训练并输出预测
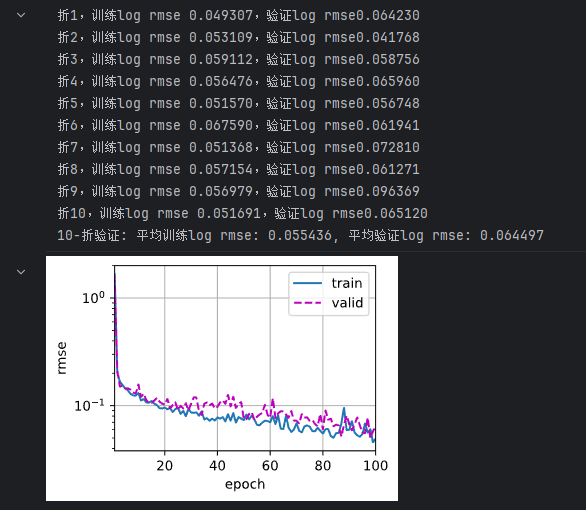
k, num_epochs, lr, weight_decay = 10, 100, 0.01, 0
train_l, valid_l = k_fold_dense(k, train_features, train_labels, num_epochs, lr,
weight_decay)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
总结
- 通过本次练习,熟悉了对于一个案例从数据处理到构建模型进行预测的流程。学到一些案例处理的思路,比如对于损失函数的考虑。还有就是数据处理很关键。
- 学习到一些对数据操作的函数以及k折交叉验证的实现,
DataFrame.apply()对数据对象进行批量处理,很多pandas的数据对象都可以使用apply()来调用函数。,如 Dataframe、Series、分组对象、各种时间序列等。pandas.get_dummies()是 pandas 库中的一个函数,用于对整个数据集中的离散变量执行独热编码(One-Hot Encoding)。torch.clamp(input,min,max)将输入的张量中的数据压缩在[min,max]之间。 float('inf')代表无穷大Series([data, index, dtype, name, copy, …])将一维的列向量数据换成Series的结构,通过values提取其值,可以通过DataFrame中某一行或者某一列创建序列。
- 含有dense block的模型,是一个比较复杂的模型,这就导致了其过拟合了训练集,而在测试集上表现就比较差了(最后提交kaggle结果0.14607,只比简单模型好了一点点点点点点)。也尝试加上dropout、权重衰减等方式,结果并没由得到比较好的优化,可能需要进一步调参。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号