ssh架构之hibernate(三)关系映射
1.单向多对一
1.映射文件配置
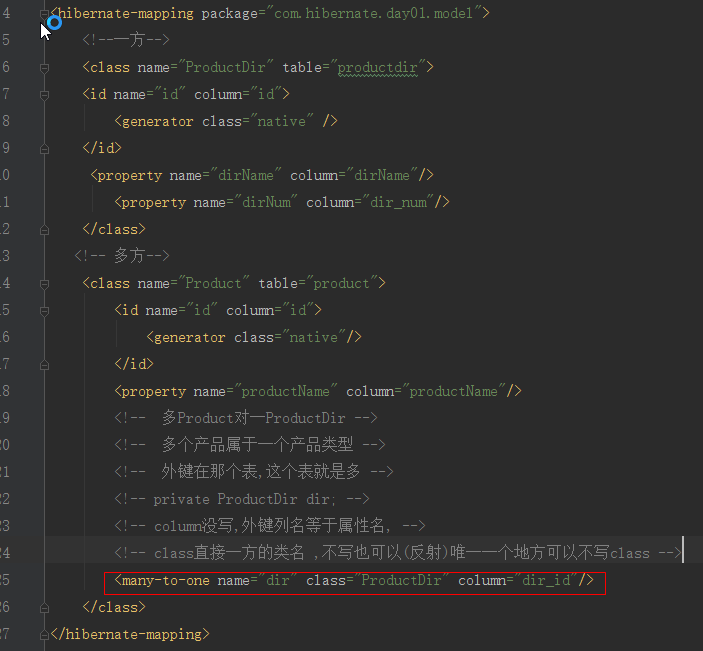
2.model:
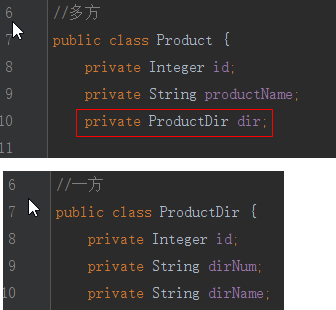
测试
1.查询测试
执行顺序,先查询多方,在查询一方,一方采用延迟加载
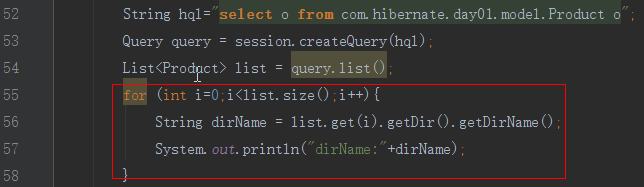
注意:如果不使用一方的数据,就关闭session,报错,同延迟加载中的报错类型一样
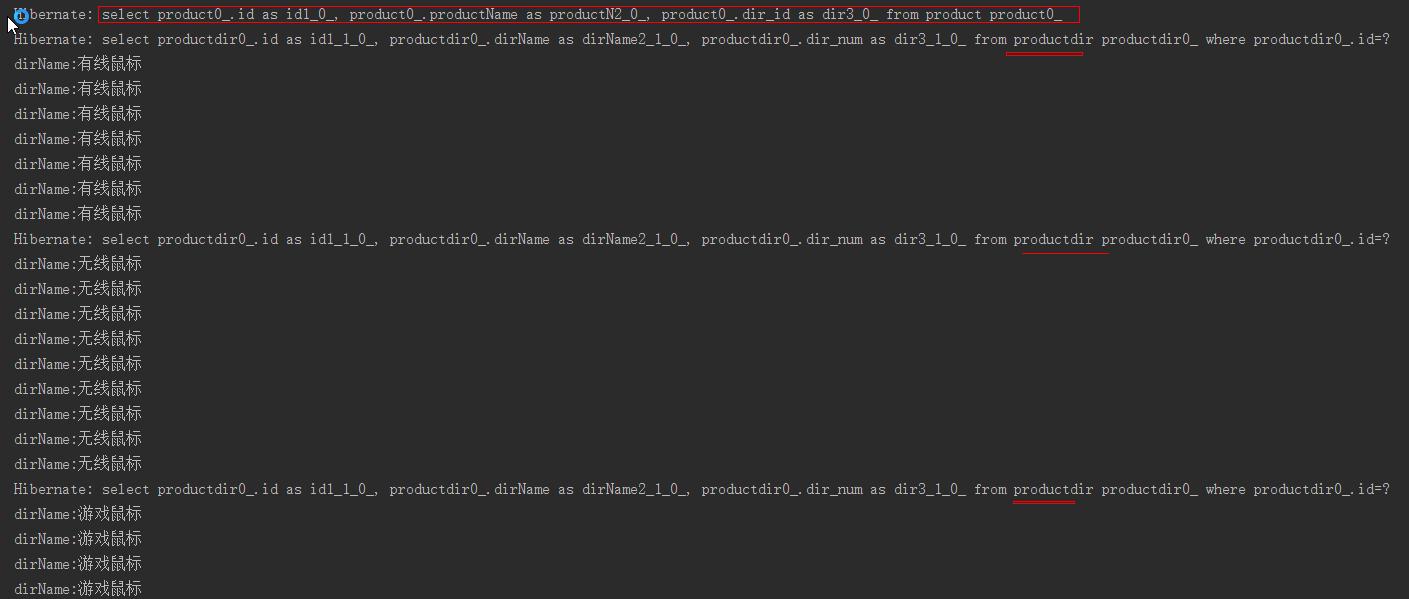
测试控制台输出为:
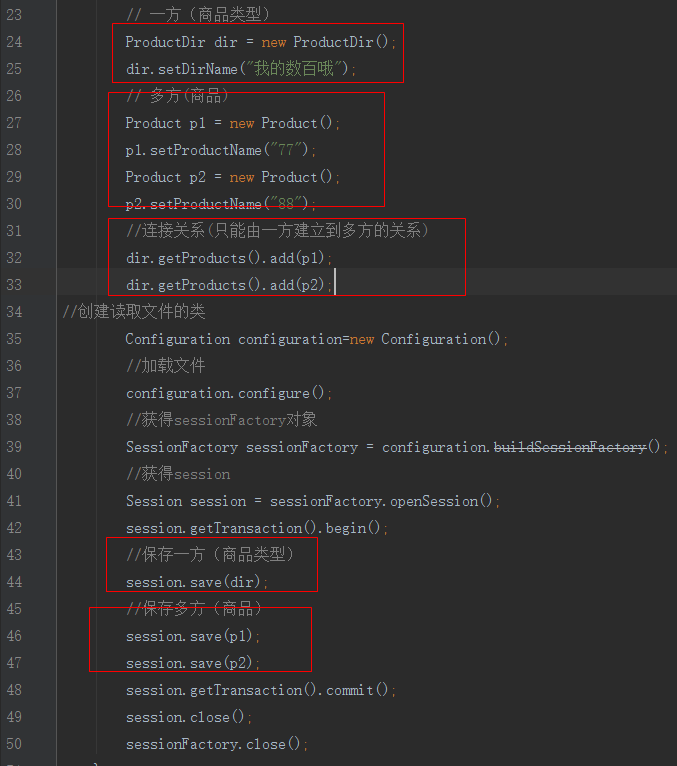
2.保存测试
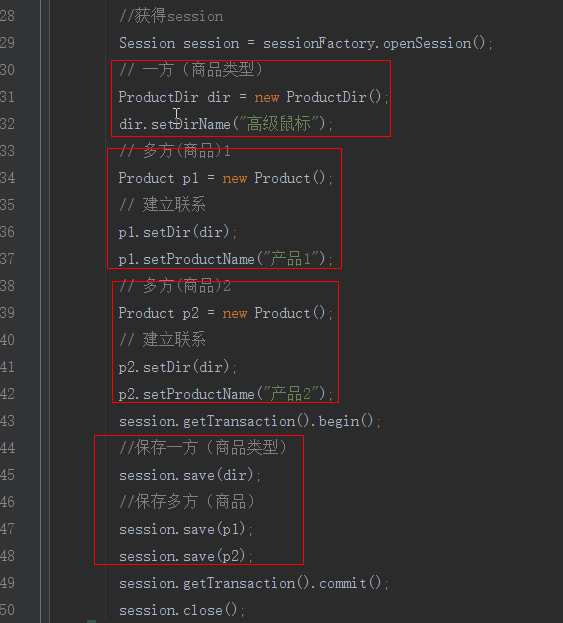
输出结果:
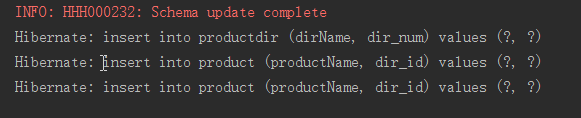
注意:
1.保存测试先保存商品后保存分类:
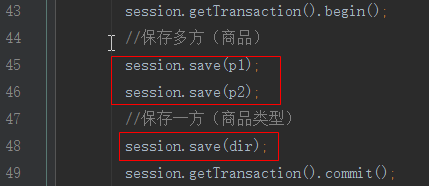
测试结果:
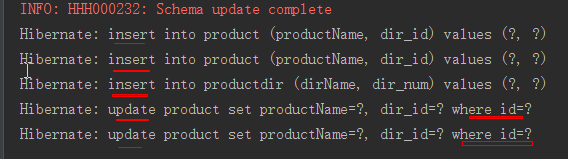
结论:很明显先保存商品后保存分类,要执行5句sql,效率低.
实际情况,我们先把类型分好,然后进货的时候就直接可以分类。但是如果相反的话,我们就要先进货,再分类型,再把货放到相应类型中去
2.关联对象不要实例化(单向多对一)
不能在多方实例化一方,因为实例化之后一方没有主键,也就是没有外键值,保存会出错

2.一对多的映射文件配置
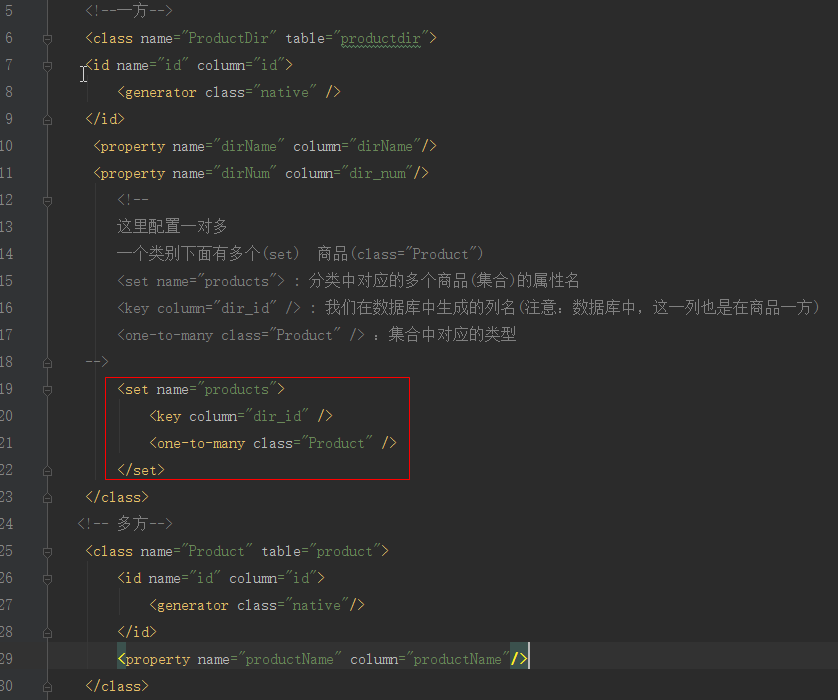
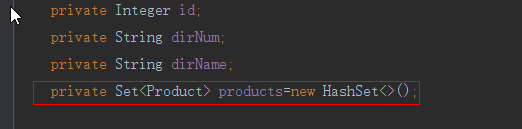
这个lazy的值默认为true,则实现延时加载,而我们修改成false后,不管有没有找其它的商品,它都会马上发送SQL来去查询数据。 但是这种做法严重影响性能。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号