大型运输行业实战_day15_1_全文检索之Lucene
1.引入
全文检索简介: 非结构化数据又一种叫法叫全文数据。从全文数据(文本)中进行检索就叫全文检索。


2.数据库搜索的弊端
案例 :
select * from product where product like ‘苹果’g
1、 使用like,会导致索引失效
(没有索引时)速度相对慢
2、 搜索效果不好
3、 没有相关度排序
3.全文解锁实现原理

4.简单使用
4.1.创建索引与搜索索引
首先导入jar包
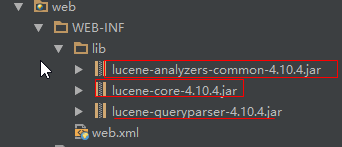
代码:
1 package com.day02.lucene; 2 3 import org.apache.lucene.analysis.Analyzer; 4 import org.apache.lucene.analysis.standard.StandardAnalyzer; 5 import org.apache.lucene.document.Document; 6 import org.apache.lucene.document.Field; 7 import org.apache.lucene.document.FieldType; 8 import org.apache.lucene.index.DirectoryReader; 9 import org.apache.lucene.index.IndexReader; 10 import org.apache.lucene.index.IndexWriter; 11 import org.apache.lucene.index.IndexWriterConfig; 12 import org.apache.lucene.queryparser.classic.ParseException; 13 import org.apache.lucene.queryparser.classic.QueryParser; 14 import org.apache.lucene.search.IndexSearcher; 15 import org.apache.lucene.search.Query; 16 import org.apache.lucene.search.ScoreDoc; 17 import org.apache.lucene.search.TopDocs; 18 import org.apache.lucene.store.Directory; 19 import org.apache.lucene.store.FSDirectory; 20 import org.apache.lucene.util.Version; 21 import org.junit.Test; 22 23 import java.io.File; 24 import java.io.IOException; 25 26 /** 27 * Created by Administrator on 2/10. 28 */ 29 public class HelloLucene { 30 //索引地址目录 31 private String file = "E:\\lucene\\indexOne"; 32 //索引版本配置 33 private Version matchVersion = Version.LUCENE_4_10_4; 34 //案例文档 35 private String doc1 = "Hello world Hello"; 36 private String doc2 = "Hello java world Hello Hello"; 37 private String doc3 = "Hello lucene world"; 38 39 /** 40 * 创建索引代码 41 * 42 * @throws IOException 43 */ 44 @Test 45 public void testCreateIndex() throws IOException { 46 System.out.println("-----测试开始------"); 47 //创建索引目录地址对象 48 Directory directory = FSDirectory.open(new File(file)); 49 //指定分词规则 50 Analyzer analyzer = new StandardAnalyzer(); 51 //创建索引配置对象 52 IndexWriterConfig conf = new IndexWriterConfig(matchVersion, analyzer); 53 //创建索引对象 54 IndexWriter indexWriter = new IndexWriter(directory, conf); 55 //创建文本属性 56 FieldType fieldType = new FieldType(); 57 fieldType.setStored(true);//存储数据 58 fieldType.setIndexed(true);//添加索引 59 60 //创建要添加的文本对象 61 Document document1 = new Document(); 62 document1.add(new Field("doc", doc1, fieldType)); 63 //添加索引 64 indexWriter.addDocument(document1); 65 66 //创建要添加的文本对象 67 Document document2 = new Document(); 68 document2.add(new Field("doc", doc2, fieldType)); 69 //添加索引 70 indexWriter.addDocument(document2); 71 72 //创建要添加的文本对象 73 Document document3 = new Document(); 74 document3.add(new Field("doc", doc3, fieldType)); 75 //添加索引 76 indexWriter.addDocument(document3); 77 78 //关闭资源 79 indexWriter.close(); 80 } 81 82 /** 83 *获取索引 84 * 1.创建查询分析器(QueryParser),使用查询分析器得到查询对象 85 * 2.使用索引搜索器(IndexSearcher).search(查询对象, 获取的多少条数据),使用索引搜索器获得文档结果集(TopDocs) 86 * 3.遍历文档结果集获取文档id 87 * 4.使用IndexSearcher通过文档id获取文档对象,并获取文档具体字段值 88 */ 89 String key = "lucene"; 90 91 @Test 92 public void testSearchIndex() throws IOException, ParseException { 93 System.out.println("-----测试开始------"); 94 //1.创建索引目录地址对象 95 Directory directory = FSDirectory.open(new File(file)); 96 //2.创建目录阅读器 97 IndexReader indexReader = DirectoryReader.open(directory); 98 //3.创建索引搜索器 99 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 100 //需要查询的字段 101 String query = "doc"; 102 //4.创建分词器 103 StandardAnalyzer standardAnalyzer = new StandardAnalyzer(); 104 //5.创建查询分析器 105 QueryParser queryParser = new QueryParser(query, standardAnalyzer); 106 //6.使用查询分析器(查询关键字)获取对应的对象 107 Query parse = queryParser.parse(key); 108 //7.获取查询结果 109 int n = 1000;//最大返回对象数 110 TopDocs topDocs = indexSearcher.search(parse, n); 111 //8.获取总天数 112 int totalHits = topDocs.totalHits; 113 System.out.println("totalHits=>" + totalHits); 114 //9.获取查询返回结果集 115 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 116 //10.遍历结果集 117 for (ScoreDoc scoreDoc : scoreDocs) { 118 //获取文档主键 119 int docId = scoreDoc.doc; 120 System.out.println("docId=" + docId); 121 //通过文档Id获取文档对象 122 Document doc = indexSearcher.doc(docId); 123 //获取文档值 124 String docValue = doc.get("doc");//根据存放的key 125 System.out.println("docValue=" + docValue); 126 } 127 } 128 }
创建索引测试结果如下:
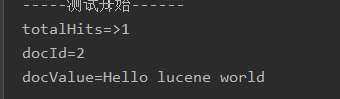
执行索引搜索结果如下图:
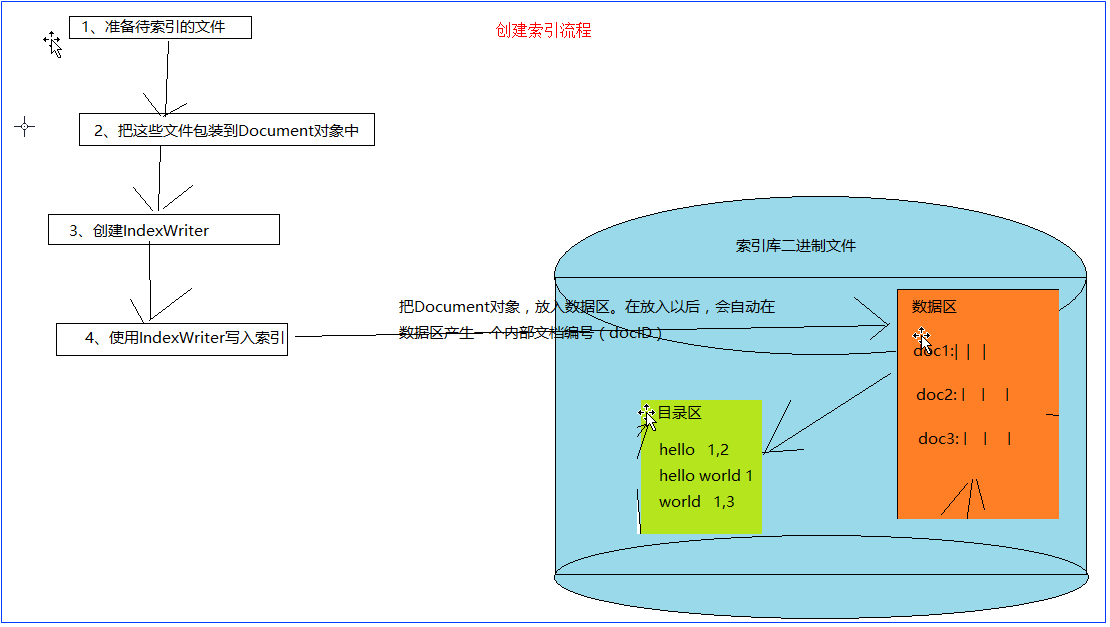
5.执行流程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号