
利用python第三方库提取PDF文件的表格内容
小爬最近接到一个棘手任务:需要提取手机话费电子发票PDF文件中的数据。接到这个任务的第一时间,小爬决定先搜集各个地区各个时间段的电子发票文件,看看其中的差异点。粗略统计下来,PDF文件的表格框架是统一的,但是数据部分则有较大差异:
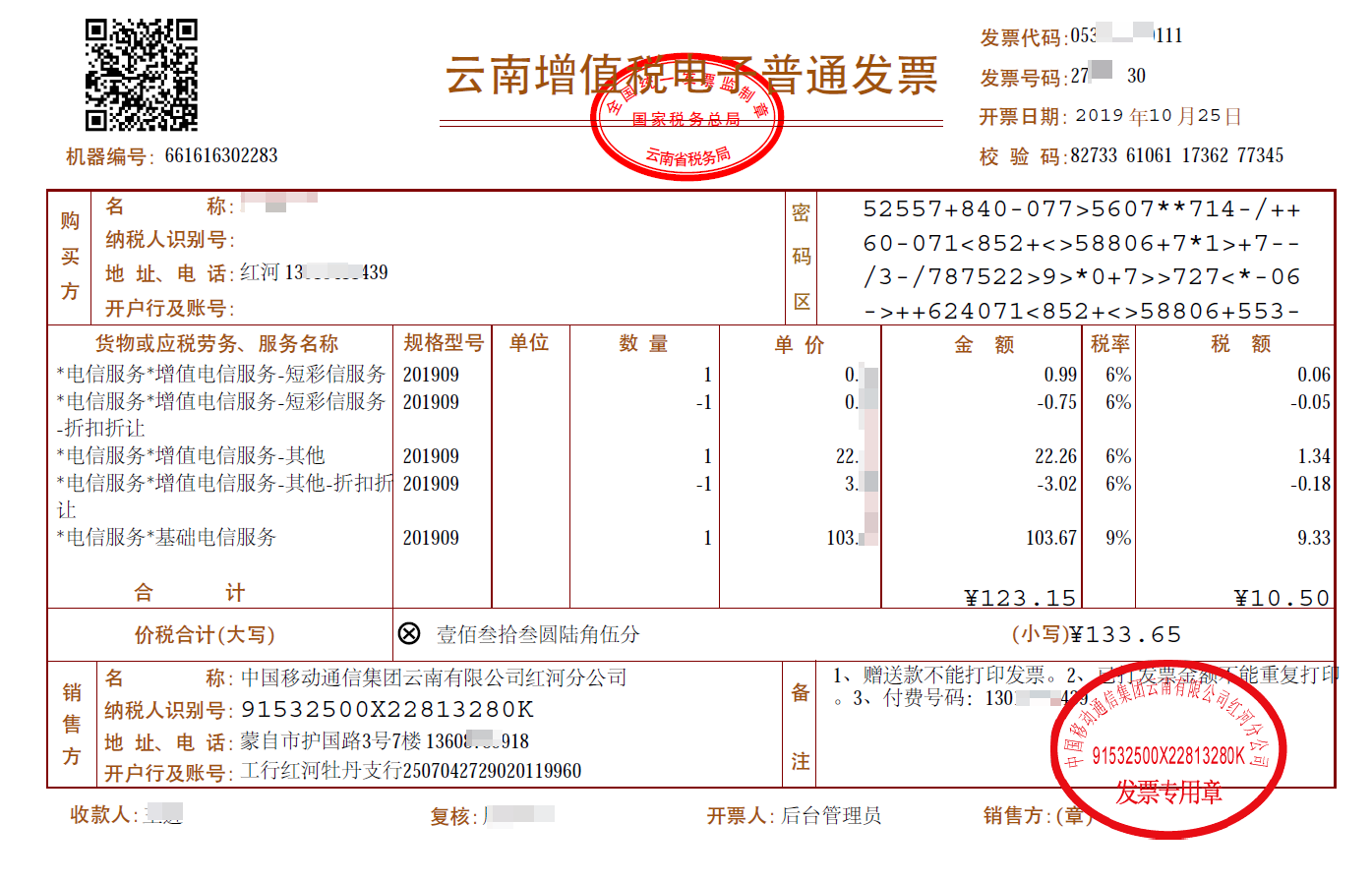
.
小爬首先想到的是借助工具提取发票的文本内容,然后用re正则表达式进行规则化的匹配数据,找到每个字段信息;这其中大部分的python-pdf解析库都能胜任.
可关键的问题是,提取出来的文本差异性非常大,比如说:各段文字出现的顺序并没有按照PDF中的文字Z序排列.举个例子:"名称:"后面紧跟的未必是真实的【用户名称】字符,可能是【单价】.这就给RE表达式提取信息带来了极大难度.后来小爬才意识到,我需要的是一个能够对"表格"数据的支持非常友好的PDF解析库,且它同时对表格以外的图片&文字信息也具备很好的提取能力.
我们得搞定二维码:发票PDF文件的左上角位置是一个二维码对象,该二维码中可以解析到 "机器编号","发票代码","发票号码","开票日期" 和"校验码".这个时候需要用到fitz.很多人不知道fitz库是啥,其实它是pymupdf中的一个模块,操作PDF非常舒服,只需要pip安装即可:
pip install pymupdf
该方法基本借鉴了这篇博客的方法:Python提取PDF中的图片,代码示例如下:

def pdf2pic(pdf_path): #t0 = time.clock() # 生成图片初始时间 checkXO = r"/Type(?= */XObject)" # 使用正则表达式来查找图片 checkIM = r"/Subtype(?= */Image)" doc = fitz.open(pdf_path) # 打开pdf文件 imgcount = 0 # 图片计数 lenXREF = doc._getXrefLength() # 获取对象数量长度 # 遍历每一个对象 for i in range(1, lenXREF): text = doc._getXrefString(i) # 定义对象字符串 isXObject = re.search(checkXO, text) # 使用正则表达式查看是否是对象 isImage = re.search(checkIM, text) # 使用正则表达式查看是否是图片 if not isXObject or not isImage: # 如果不是对象也不是图片,则continue continue imgcount += 1 pix = fitz.Pixmap(doc, i) # 生成图像对象 #new_name = "图片{}.png".format(imgcount) # 生成图片的名称 new_name=pdf_path.replace("pdf","png").replace("手机话费发票","二维码图片") if pix.n < 5: # 如果pix.n<5,可以直接存为PNG pix.writePNG(new_name) else: # 否则先转换CMYK pix0 = fitz.Pixmap(fitz.csRGB, pix) pix0.writePNG(new_name) pix0 = None pix = None break return new_name # 释放资源
使用它,我们就可以解析得到PDF文件中的二维码图片元素,并保存为PNG图片.再利用pyzbar我们可以很轻易地解析出二维码中的信息.之所以要单独提取出二维码并保存为图片,再识别和解析二维码,是因为如果我们把所有的pdf内容处理为png图片,再让Pyzbar库来解析二维码,则pyzbar需要先定位二维码在图片中的位置,才能开始解析.这样png图片中干扰元素变多,识别率必然下降.而单纯地识别PDF文件中的提取到的二维码图片,则pyzbar库的识别率非常高,几乎达到100%.
但凡事总有例外,有些PDF文件不规则,无法通过遍历元素的方法得到这个二维码对象元素.此时,我们可以借助截取PDF画面右上角的固定区域来得到二维码图片.具体代码如下:
def crop_to_png(pdfPath): ''' 假定pdf只有一页,只转换第一页的内容的左上角部分(二维码区域)为png图片 tl:TopLeft br:BottomRight mp:MiddlePoint ''' doc = fitz.open(pdfPath) pngPath=pdfPath[:-4] page = doc[0] rotate = int(0) # 每个尺寸的缩放系数为3,这将为我们生成分辨率提高九倍的图像。 zoom_x = 3.0 zoom_y = 3.0 trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate) rect = page.rect mp = rect.tl + (rect.br - rect.tl) * 1/5 #二维码矩形区域右下角坐标 clip = fitz.Rect(rect.tl,mp) #裁切的二维码区域的左上角、右下角坐标,定位裁切的矩形区位置 pm = page.getPixmap(matrix=trans, alpha=False,clip=clip) pngPath=pdfPath.replace("pdf","png").replace("手机话费发票","二维码图片") pm.writePNG(pngPath) doc.close() return pngPath
得到了二维码图片,我们先按照 pdf2pic(pdf_path) 方法,交给pyzbar解析,如果依旧识别不了,我们再用第二种裁切画面的方法:crop_to_png(pdfPath) 得到并保存二维码图片,再交给pyzbar解析.如果两种方法都不能通过pyzbar解析,则返回信息提示用户.具体方法如下:
def parse_invoice_qrcode(pdfPath,pngPath): """ 通过解析二维码信息,得到发票的发票代码、发票号码 开票日期、检验码、机器编号等信息 """ invoice_code,invoice_number,total_money,invoice_date,check_code=(None,None,None,None,None) img=Image.open(pngPath) #img_size=img.size #print(img_size) qrcodes=pyzbar.decode(img) #print(qrcodes) try: qrcodeInfo=qrcodes[0].data.decode("utf-8").split(",") except: print("%s:decode error,try another way to decode it"%pngPath) pngPath=crop_to_png(pdfPath) #使用另一种裁切图片的方法得到二维码图片,并返回图片的路径 img=Image.open(pngPath) qrcodes=pyzbar.decode(img) try: qrcodeInfo=qrcodes[0].data.decode("utf-8").split(",") except: print("%s:still decode error"%pngPath) return invoice_code,invoice_number,total_money,invoice_date,check_code invoice_code=qrcodeInfo[2] #发票代码 invoice_number=qrcodeInfo[3] #发票号码 total_money=qrcodeInfo[4] #不含税总金额 invoice_date=qrcodeInfo[5] #发票日期 check_code=qrcodeInfo[6] #检验码 print("二维码图片名称:%s\n发票代码:%s\n发票号码:%s\n不含税金额:%s\n开票日期:%s\n检验码:%s"%(pngPath,invoice_code,invoice_number,total_money,invoice_date,check_code)) return invoice_code,invoice_number,total_money,invoice_date,check_code
之后,我们用pdfPlumber库来重点提取pdf发票的表格信息.
with pdfplumber.open(pdf_path) as pdf: p0 = pdf.pages[0] print("pdf名称:%s"%pdf_path) contents=p0.extract_text() #print(contents) if contents is None: print("%s:pdf文件格式异常,提取不到文本内容\n"%pdf_path) continue else: contents=contents.replace(" ","").replace(":",":") #打印所有的文本 """地区""" if p0.extract_tables()==[]: print("%s:格式不规范,提取不到表格内容\n"%pdf_path) elif len(p0.extract_tables()[0])<4: #话费pdf文件中表格共有4块 print("%s:格式不规范,提取到的表格内容不完整\n"%pdf_path) else: table = p0.extract_tables()[0] """销售方名称:运营商""" pattern=re.search(r".*?(中国.*?)\n.*?",table[3][1],re.S) salesName=pattern.group(1) if pattern else "" print("salesname:",salesName) if salesName: if "中国移动通信集团" in salesName: operation_corp="移动" """提取用户名、电话和账期字段""" txt=table[0][1].replace(":",":").replace(" ","") #名称 &纳税人识别号字段 userName=re.search(r"名称:(.*?)\n.*?",txt).group(1) if "(号码" in userName: userName=userName.split("(")[0] #pattern=re.search(r".*?\D(1[0-9]{10}).*?",txt) if not tel: pattern=re.findall(r'\d+',txt) #这串数字(11位)前后都不是数字字符,避免从其他数字中提取了一段当作电话号码 if pattern: for element in pattern: if element[0]=="1" and len(element)==11: tel=element break comment=table[3][7].replace("\n","").replace(" ","").replace(":",":") #发票的备注栏,往往有手机号和账期等信息,考虑到换行,去掉这些必要的换行符、空格符,账期有时在规格型号栏,云南区域 pattern=re.search(".*?(20[0-9]{4})-(20[0-9]{4}).*?",comment) #账期:201812-201902 ,多个月的发票开在一起 if pattern: if pattern.group(1)!=pattern.group(2): print("%s:(%s-%s)---不建议将几个月的话费开在同一张发票内!\n"%(pdf_path,pattern.group(1),pattern.group(2))) continue pattern=re.search(".*?(20[0-9]{2}[0-1]{1}[0-9]{1}).*?",comment) if pattern: period=pattern.group(1) #账期:诸如201906 或者2019年06月 else: pattern=re.search(".*?(20[0-9]{2}年[0-1]{1}[0-9]{1}月).*?",comment) if pattern: period=pattern.group(1) else: pattern=re.search(".*?(20[0-9]{2}.[0-1]{1}[0-9]{1}).*?",comment) #格式:2019.02 if pattern: period=pattern.group(1) else: type_size=table[1][2] #规格型号栏 pattern=re.search(".*?(20[0-9]{2}[0-1]{1}[0-9]{1}).*?",type_size) #格式:201902 if pattern: period=pattern.group(1) else: content=table[1][0] pattern=re.search(".*?(20[0-9]{2}年[0-9]{2}月).*?",content) #格式:2019年02月 period=pattern.group(1) if pattern else "unknown" period=period.replace("年","").replace("月","").replace(".","").replace("-","") if not tel:
pattern=re.findall(r'号码:\d+',comment) if pattern: for element in pattern: if element[3]=="1" and len(element)==14: tel=element[3:] break # 该方法提取连续的一段数字,判断数字如果刚好是11位且以数字1打头,则认为在该场景下的这段数字应该是电话号码. if not tel: #如果最终还是不能提取到对应的号码,则退出当次循环 continue print("用户名:%s"%userName) print("电话:%s"%tel) print("账期:%s"%period) print("\n") else: ("运营商不属于中国移动!") continue else: print("不规范的运营商名称(必须以“中国”开头)") continue
原则上借助该方法,可以提取发票的明细项和对应内容,发票账期,人名,电话号码,税率等内容.
但是实际的数据提取过程中,部分PDF发票用pdfPlumber模块的 extract_tables()==[],可能捕获的是一个空列表.小爬的例子证明 pdfPlumber不是万能的.知乎上很多人力推的 tabula-py库是基于java的tabula的二次封装.要在python下使用该库,我们还需要安装Java的JRE环境,将来的封装exe也是一个大问题.小爬因此没有继续尝试.其他的python pdf2htmlEX库,小爬亲测了下,对表格的适用性不太好,尤其是(合并单元格的不规则表格)效果达不到要求.
小爬试了下 camelot库.这个pdf解析库在windows系统下的安装非常不顺利,几番折腾才得以成功安装.由于网上的诸多教程都没有很好的阐述这个库的安装过程.这里小爬特此 说明该如何正确安装.首先不是直接安装:PIP install camelot.我们需要的库名叫camelot-py.正确的方法是,进到camelot在github上的仓库,下载zip文件解压后,用setup方法运行.地址如下:
https://github.com/camelot-dev/camelot
安装方法:
步骤
打开cmd或者powerShell
到达安装目录
python setup.py build
python setup.py install
由于该库还依赖于tk库,CV库以及Ghostscript(一个exe文件),pandas,numpy等库,我们需要逐个安装这些依赖文件.
如果只想用PIP安装,则需要通过pip install tk,然后再用pip install camelot-py[cv]
就可以在安装camelot-py的同时安装上兼容的CV库.
而Ghostscript并不是通过pip install来安装,它在windows系统下有exe的安装文件,下载地址如下:
https://www.ghostscript.com/download/gsdnld.html
我们只需要下载系统对应的版本就好.
安装该软件,并记得添加用户环境变量路径.

有了这些步骤,我们的camelot库才算可以正常运行.下面是官网给出的一个例子,供参考:
>>> import camelot >>> tables = camelot.read_pdf('foo.pdf') >>> tables <TableList n=1> >>> tables.export('foo.csv', f='csv', compress=True) # json, excel, html, sqlite >>> tables[0] <Table shape=(7, 7)> >>> tables[0].parsing_report { 'accuracy': 99.02, 'whitespace': 12.24, 'order': 1, 'page': 1 } >>> tables[0].to_csv('foo.csv') # to_json, to_excel, to_html, to_sqlite >>> tables[0].df # get a pandas DataFrame!
具体的操作文档见官方的手册,路径如下:
https://camelot-py.readthedocs.io/en/master/

事实证明,camelot和pdfplumber都有各自擅长的pdf解析领域.我们可以在实际的项目中,同时使用这两个库,互为补充.当其中一个提取表格失败时,另一个库有可能可以很理想的得到我们想要的数据.
PS:使用camelot得到的数据可以很方便转成pandas需要的DataFrame格式,并结合pandas功能,方便导出csv或者xlsx格式的文件,进行后继处理!
赶紧动手试试吧!
快来扫码关注我的公众号 获取更多爬虫、数据分析的知识!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-12-06 python利用requests库模拟post请求时json的使用