利用pandas、Ipython来简化数据分析过程
最近小爬我为了提升数据分析这块儿的技能,学习了pandas库作者Wes Mckinney的数据分析经典书籍《利用Python进行数据分析》,受益良多!里面涉及到Python语言基础、还有编程利器Ipython、Jupyter notebook的使用小技巧,数组分析工具Numpy以及pandas的基础入门和深入知识,甚至还包含绘图与可视化的相关知识。在学习过程中,小爬深刻感受到:工欲善其事必先利其器。有了好的工具加持,数据分析不再是难事!

小爬先说说之前不知道但在该书中提到的Ipython的一些技巧:
1、Tab补全
相较于标准python命令行,Ipython的提升之一就是tab补全功能。当在命令行输入表达式时,按下Tab键即可为任意变量(对象、函数等)搜索命名空间,与当前已输入的字符进行匹配:
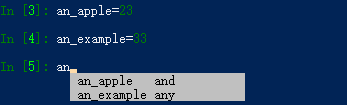


Tab补全 在其他很多上下文场景中也有用。当输入任意路径时,按下Tab键将补全你的计算机文件系统中匹配你输入内容的值:

2、内省
在一个变量名的前后使用问号(?)可以显示一些关于该对象的重要信息:

比如我们想知道print函数的用法,就可以这样操作:

假设有这么一个函数:

使用双问号甚至可以显示函数的源代码:

3、%run命令
可以在Ipython会话中使用%run命令运行任意的python程序文件,如:

4、中断运行中的代码
在任意代码运行时按下Ctrl-C,无论脚本运行到哪一步,都会引起keyboardInterrupt。除了一些特殊情况,这导致所有的python程序立即停止运行。
5、Ipython的常见快捷键
- Ctrl-P 或上箭头键 后向搜索命令历史中以当前输入的文本开头的命令
- Ctrl-N 或下箭头键 前向搜索命令历史中以当前输入的文本开头的命令
- Ctrl-R 按行读取的反向历史搜索(部分匹配)
- Ctrl-Shift-v 从剪贴板粘贴文本
- Ctrl-C 中止当前正在执行的代码
- Ctrl-A 将光标移动到行首
- Ctrl-E 将光标移动到行尾
- Ctrl-K 删除从光标开始至行尾的文本
- Ctrl-U 清除当前行的所有文本译注12
- Ctrl-F 将光标向前移动一个字符
- Ctrl-b 将光标向后移动一个字符
- Ctrl-L 清屏
小爬再来说说Pandas,它所包含的数据结构和数据处理工具的设计使得在python中进行数据清洗和分析异常方便和快捷。
我们一般这样导入Pandas:
import pandas as pd
pandas中有两个非常有名的类Series Dataframe,如果只想导入这两个类,可以这样:
from pandas import Series,Dataframe
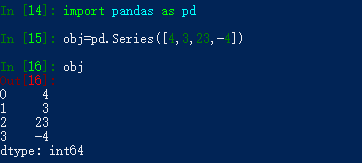
1、Series
Series是一维数组对象,它包含一个值序列,并且含数据标签,称为索引(Index):
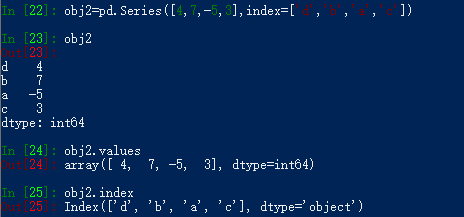
我们可以通过values属性和Index属性分别获得Series对象的值和索引:
我们可以基于条件查找特定值:

它也可以逐元素进行简单运算:

我们还可以这样作逻辑判断: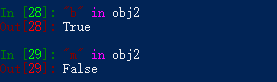
我们甚至可以根据python字典快速生成一个Series对象:
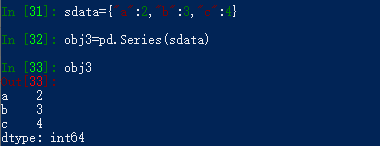
我们还可以用一个列表对象当成参数传给series对象当作索引(元素个数必须一致)
Series的索引可以通过按位置赋值的方式进行改变:

2、Dataframe
Dataframe表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型,这跟我们熟悉的excel工作表太像了,所以很多原本用Excel来作的数据分析就可以使用Dataframe来处理,毕竟它的运算速度堪比数据库sql语句,比一般的excel计算快不少。
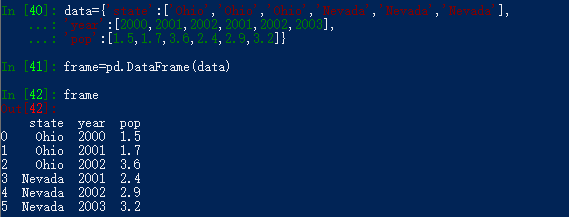
我们有多种方法去创建DataFrame,最常用的方法是利用包含等长度列表或Numpy数组的字典来生成DataFrame,产生的DataFrame会自动为Series分配索引,并且列会按照排序的顺序排列:
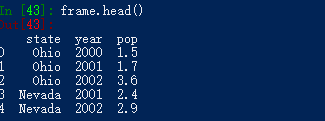
对于大型DataFrame,head方法将会只选出头部的五行:
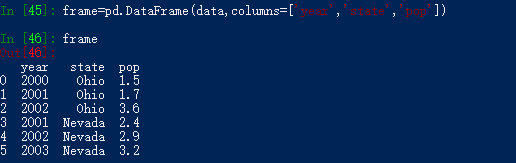
我们可以指定DataFrame的索引:

DataFrame中的一列,可以将字典型标记或属性那样检索为Series:

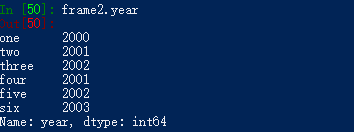
我们也可以用df[字段名]表示法:
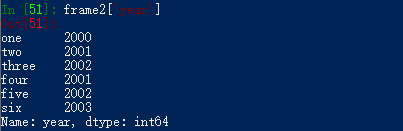

del方法可以用于移除之前新建的列:

mark,后续会再记录更多的pandas使用心得,并应用到实际的项目中!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号