

Python笔记记录
python2和python3的不同: Unicode(统一码、万国码),在3里面可以直接写中文了。
python2里rae_input与python3中的input效果一样
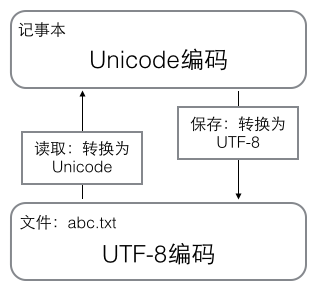
在计算机内存中,统一用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换成UTF-8保存到文件。
用记事本编辑的时候,从文件读取的UTF-8字符被转换成Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换成UTF-8保存到文件:
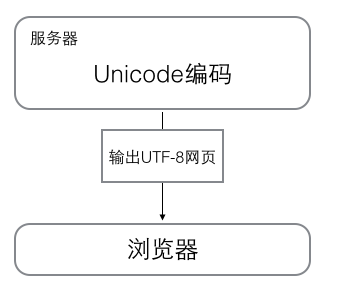
浏览网页的时候,服务器会把动态生成的Unicode内容转换成UTF-8在传输到浏览器:
python基础:
字符串
转义字符:\ 可以转移很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\

如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义

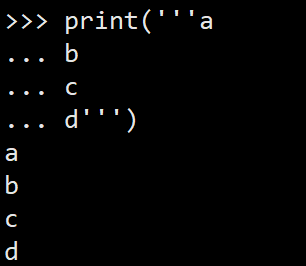
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容
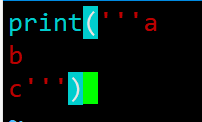
如果写成程序并存为.py文件,就是:
布尔值
True & False 可以用and、or、not进行运算
Python字符串问题
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示: x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:

纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
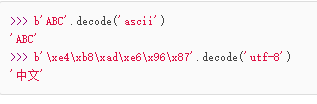
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
计算str包含多少个字符,可以用len()函数
格式化
%运算符就是用来格式化字符串的,在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。
常用占位符有:

format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:

list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,可以用一个list表示: classmates = ['tom', 'jane', 'boy']
可以用len()来获取list元素个数,可以用索引来访问list中每一个位置的元素
也可以把元素插入到指定的位置,比如索引号为1的位置:
classmates.insert(1, 'Jack')
要删除list末尾的元素,用pop()方法
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改
比如,列出班里所有同学的名字 classmates = ('tom', 'jane', 'boy')
注意: 只有1个元素的tuple定义时必须加一个逗号,,来消除歧义: t = (1,)
dict
键-值存储(key-value)
例如 d = {'Tom' : 23, 'Jane' : 26, 'Michael' : 18}
如果要增加字典的值,则可以 d['Adam'] = 99
判断key是否存在: 'Tom' in d 通过返回的布尔值来判断是否存在
获取value可以这样:d.get('Tom')
删除key: d.pop('Tom')
通过key计算位置的算法称为哈希算法(Hash)
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合: s = set([1, 2, 3])
重复元素在set中自动被过滤
通过add(key)方法可以添加元素到set中; 例:s.add(4)
通过remove(key)方法可以删除元素;例:s.remove(4)
函数
调用函数
求绝对值的函数abs,调用abs函数: abs(-20) 返回结果就是20
调用max函数,返回最大的那个值: max(2, 7)
数据类型转换
整型:int 浮点型:float 字符型:str 布尔型:bool
函数举例:添加了错误和异常处理 (数据类型检查可以用内置函数isinstance()实现)
def my_abs(x): if not isinstance(x, (int, float)): raise TypeError('bad operand type') if x >= 0: return x else: return -x
函数的参数
位置参数
def my_abs(x, n, b): 其中x n b都是位置参数
默认参数
def my_abs(x, n, b=3): 其中b=3就是默认参数
可变参数
def calc(*numbers): 就是可以传任意个数的参数,这些可变参数在函数调用时自动组装为一个tuple
关键字参数
def person(name, age, **kw): 也可以传入任意个数的参数,但这些关键字参数在函数内部自动组装过程一个dict
命名关键字参数
def person(name, age, *, city, job): 命名关键字参数需要一个特殊的分隔符*,*后面的参数被视为命名关键字参数
调用方式如下: person('Tom', 24, city='Beijing', job='Engineer')
注: 如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名
