
Sudoku(第二次作业)
[这里是github](https://github.com/031502243/Sudoku/tree/master/Desktop/shudu)
工具清单:
- 编程语言:C++
- 编程IDE:XCode
- 效能分析工具:XCode
- 源代码管理平台:Github
#PSP2.1
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ————— | ————— |
| · Estimate | · 估计这个任务需要多少时间 | 16h | ————— |
| Development | 开发 | ————— | ————— |
| · Analysis | · 需求分析 (包括学习新技术) | 3h | 2h |
| · Design Spec | · 生成设计文档 | 10min | 10min |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10min | 0min |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10min | 0min |
| · Design | · 具体设计 | 1h | 1h |
| · Coding | · 具体编码 | 5h | 4h |
| · Code Review | · 代码复审 | 3h | 2h |
| · Test | · 测试(自我测试,修改代码,提交修改) | 1h | 2h |
| Reporting | 报告 | ————— | ————— |
| · Test Report | · 测试报告 | 3h | 4h |
| · Size Measurement | · 计算工作量 | 10min | 20min |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10min | 0min |
| 合计 | 16h50min | 15h30min | |
关于这个表格我想要说一下..关于生成设计文档、设计复审、代码规范..目前貌似好像是用不到,希望学长老师可以在这里指点一下。
解题思路
一开始看到这个作业的题目,首先想到的当然是数独的实现。第一秒在我脑海中想到的是,八十一个格子,每个格子随机填一个数,然后判断行是否冲突,列是否冲突,所属的9*9格子中的数字是否冲突,如果不冲突就填上这个数字,如果冲突了就重新随机一个数字填。
但是这个方法有几个问题: - 1.实现有问题。填最后一个格子(第九行第九列)的时候,本应只有一个数字可以填,但是如果这个数字发生冲突,就会出现死循环,永远得不到答案。 - 2.性能太差,单看第一行,每次填数字的时候都是随机的数字,不能判断之前填过的数字,假设前八个格子填过了12345678,填最后一个格子的时候,一直随机不到9,就会浪费太多的时间。第一行就会出现这样的问题,可想而知填完整个数独会浪费多少时间。
于是我开始百思不得其解,上网百度了别人实现数独的方法,发现了一个很神奇的方法--回溯法。
那么回溯法是什么呢?正如之前举过的例子,填最后一个格子(第九行第九列)的时候,如果没有数字可以填,就返回上一步(第九行第八列),重新填上一个格子,如果还是无法实现最终结果,那就再退一步,重新填第九行第七列的格子,以此类推。这样就总是能得出最终解。
那么可以实现了以后,暴力随机数字的方法当然是不可取了,看到网上很多人都是先把第一列填好,再填第二列、第三列,每填一个数字都判断一下行冲突,列冲突,格冲突。那么有没有方法能少一次判断呢?于是想到了可以先把每一行的1填了,再填每一行的2...以此类推。这样肯定没有行冲突,只需要判断列冲突和格冲突就可以了。那么数字填进去的规则是什么呢?如果每次都指定一行的同一个位置,那么数独的个数就大大减少,不如每次填数字都填入一行中的随机的位置,这样就可以解决刚刚的问题了。取随机数的方法,使用的是srand() rand()。[这里是使用方法。](http://blog.csdn.net/zqy2000zqy/article/details/1174978)
设计实现
- 没有用到类。
- 整个数独用数组实现,所以需要一个初始化数组的函数,并且将数组sudoku[0][0]初始化为题目要求。
- 需要一个判断填数的时候是否会出现冲突的judge()函数。布尔类型函数,如果填数成功,则返回true,若填数失败,即数字冲突,则返回false。
- 回溯函数reset(),如果填数失败,则应该回溯。
- 填数字的函数set()。布尔类型,放置在while循环中。
- 将结果打印出来的函数printSudoku()。
以下是相关函数的流程图(第一次做这个不知道做的对不对)。

代码说明
- 头文件
#include<iostream>
#include<ctime>
#include<fstream>
#define N (4+3)%9+1
- 初始化数组函数--initSudoku()
void initSudoku(){
for(int i = 0 ; i < 9 ; i++){
for (int j = 0 ; j < 9 ; j++){
sudoku[i][j] = 0;
}
}
sudoku[0][0] = N ;//将sudoku[0][0]设置为题目要求
}
- 判断冲突函数--judge()
bool Judge(int x, int y, int val)
{
if(sudoku[y][x] != 0)//非空
return false;
int x0, y0;
// for(x0 = 0;x0<9;x0++)
// {
// if (sudo[y][x0] == val)//行冲突
// return false;
// }
for (y0 = 0; y0<9; y0++)
{
if (sudoku[y0][x] == val)//列冲突
return false;
}
for(y0 = y / 3 * 3 ; y0<y / 3 * 3 + 3 ; y0++)
{
for(x0 = x / 3 * 3 ; x0 < x / 3 * 3 + 3 ; x0++)
{
if(sudoku[y0][x0] == val)//格冲突
return false;
}
}
sudoku[y][x] = val;
return true;
}
- 回溯函数--reset()
void reset(int x, int y)
{
sudoku[y][x] = 0;
}
- 填数函数--set()
bool set(int y, int val)
{
int xOrd[9] ;
int i, k, tmp;
for(i=0;i<9;i++)
{
xOrd[i] = i;
}
for(i = 0;i<9;i++) //生成当前行的扫描序列,实现随机填入位置
{
k = rand() % 9;
tmp = xOrd[k];
xOrd[k] = xOrd[i];
xOrd[i] = tmp;
}
for (int i = 0 ; i < 9 ; i++)
{
int x = xOrd[i];
if (val == N && x == 0 && y == 0)//判断是不是第一行第一列的位置
{
if(set(y + 1,val))//下一行继续填当前数
return true;
}
if (Judge(x, y, val))
{
if (y == 8)//最后一行
{
if (val == 9 || set(0, val + 1))
return true;
}
else
{
if(set(y + 1,val))//下一行继续填当前数
return true;
}
reset(x, y);//回溯
}
}
return false;
}
- 将结果打印出来的函数printSudoku()。
void printSudoku()
{
for (int y = 0;y<9;y++)
{
for(int x = 0;x<9;x++)
{
// cout<< sudoku[y][x] << " ";
fout<< sudoku[y][x] << " ";
}
// cout<< endl;
fout<< endl;
}
// cout << endl;
fout << endl;
}
- main()
int main(int argc, char* argv[])
{
srand((unsigned)time(NULL));
fout.open("sudoku.txt");
int n ;
while (!(cin >> n)) {
cin.clear();
// reset input
while (cin.get() != '\n')
continue;
// get rid of bad input
cout << "Please enter a number: ";
}
while(n--){
initSudoku(); //每次循环都要初始化数独数组
while (!set(0, 1));
printSudoku();
// cout << endl;
}
fout.close();
// cout<< "1";
return 0;
}
程序运行
运行过程中
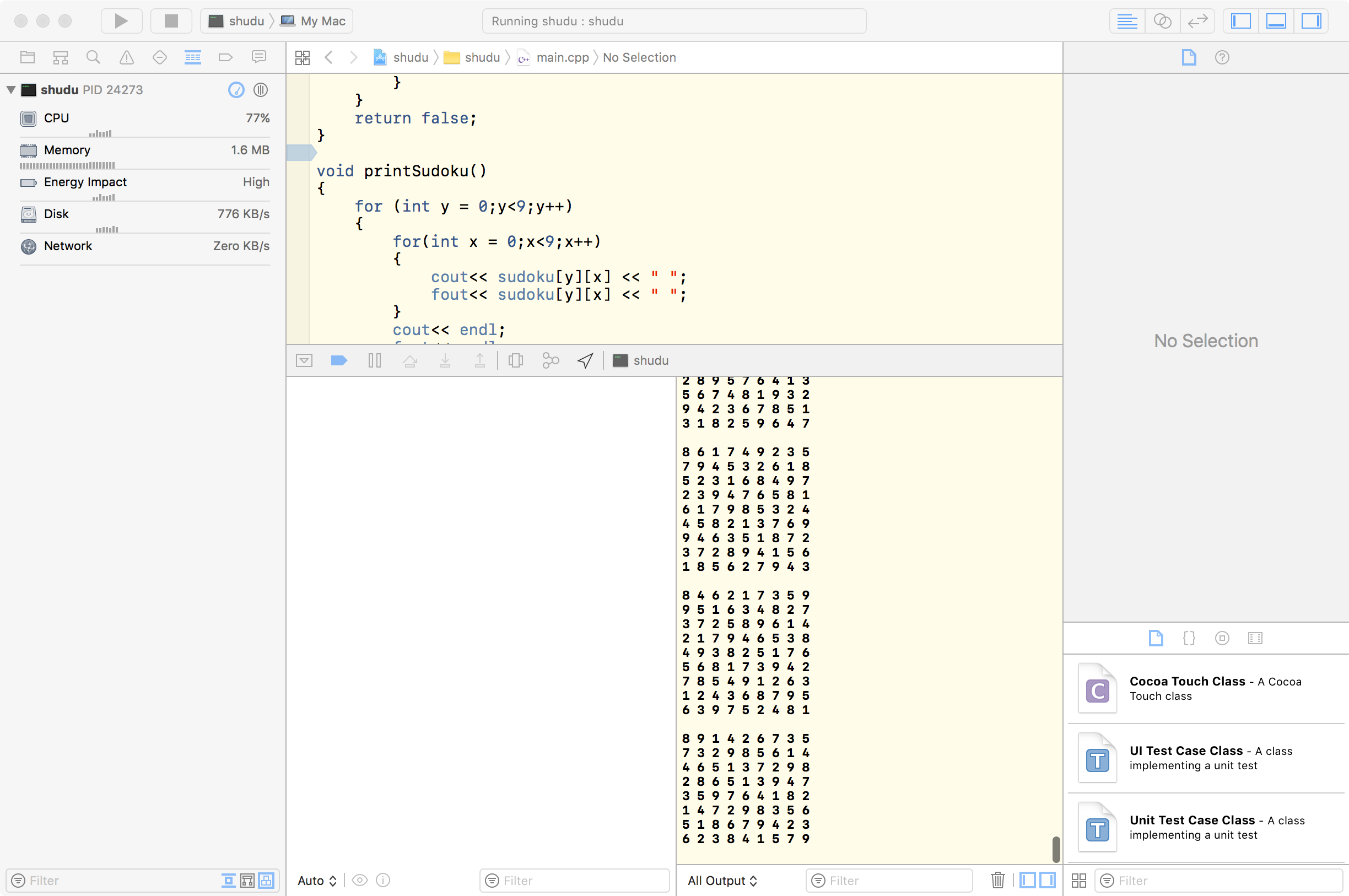
n = 2的运行结果

#性能分析
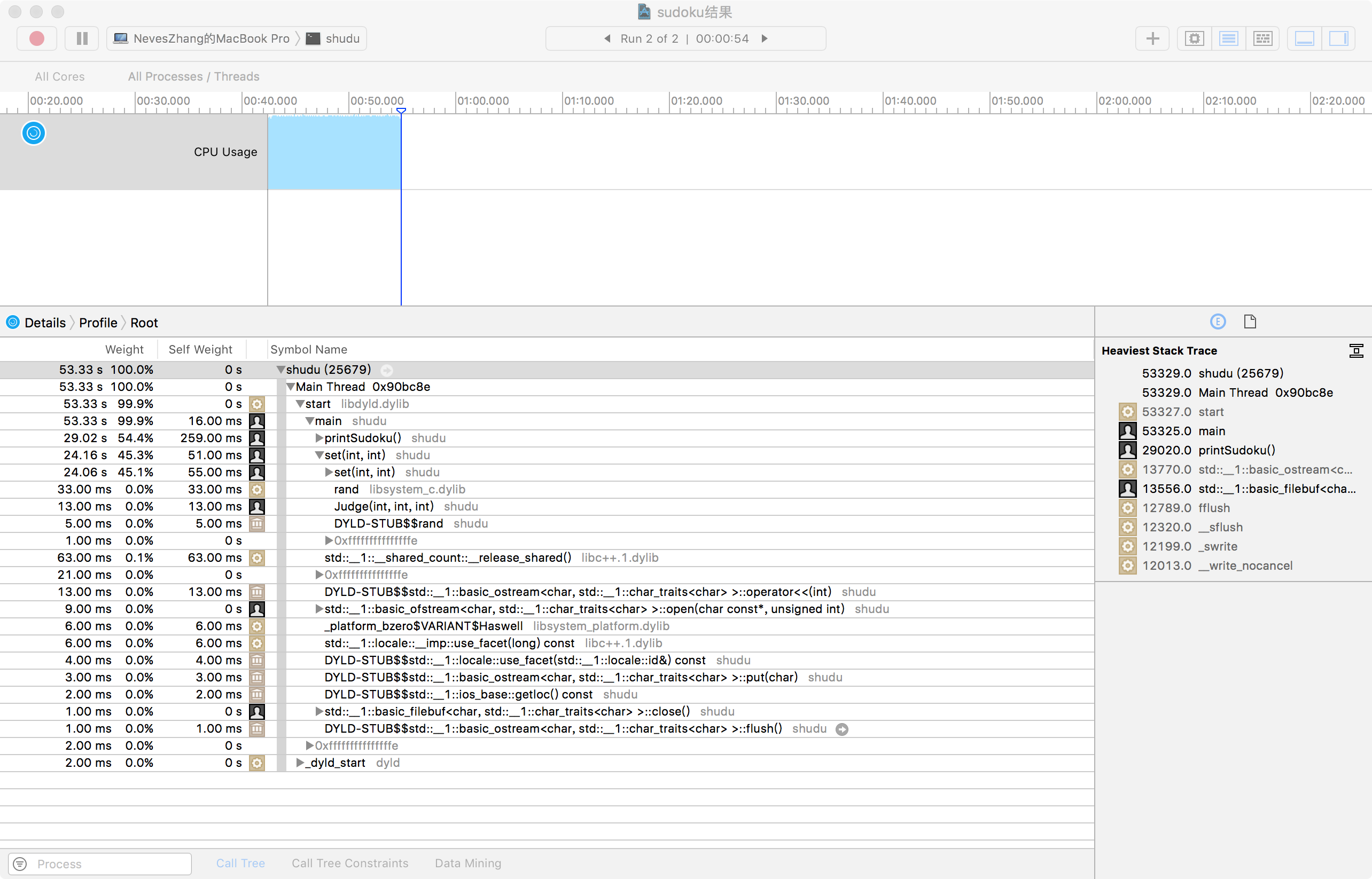
运行了1000000个数据最后用时53.33s。令我没想到的是,花时间最多的一个函数是打印函数,占总时间的54.4%,花了29秒钟。思考了许久,认为如果可以一行一行,每一行从左往右的填数字,就可以直接输出,会节省很多时间,但是这就有违我一开始的设计思路,会多一次行冲突判断的。希望老师与学长可以指出来如何能改进我的输出函数。剩下的大部分时间都是set函数,占总时间的45.3%,和我预期一样,这个函数耗时很长,因为里面有包含循环的judge函数。rand函数耗时是set函数中最多的,这一点我比较意外。
改进思路在解题思路的部分已经说明了,解题思路就是已经改进了本来的想法,减少了一重循环-判断行冲突。对于减少set函数时长目前还没有很好的想法,希望之后在浏览同学的博客的时候能有所启发。也希望老师与学长多提一些建议。最终拿来测试的程序没有输出在控制台,也减少了一些时间。
关于github的使用
github mac 使用
git push报错error: failed to push some refs to 'git@github.com:
PS:老师能不能想个办法,测试环境不要在windows下...因为班上还是有一部分同学用的不是windows环境..所以就得一直麻烦其他同学生成exe文件,自己电脑上也不能尝试..不知道有木有成功oo

