Hive安装配置以及整合HBase和hadoop
Hive安装配置以及整合
1.基本说明
本文以mesos上安装hadoop为基础,有些地方与独立安装hadoop集群不同,请注意。
安装前提是已经正确完成了hadoop,Hbase的安装并且能够正常启动。(具体参照我前面的文章)
官方文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
2.下载安装
wget http://mirror.bjtu.edu.cn/apache/hive/hive-0.9.0/hive-0.9.0.tar.gz tar -zxvf hive-0.9.0.tar.gz
3.配置
3.1 /etc/profile中添加如下
export HIVE_HOME=/home/hadoop/hive-0.9.0 export PATH=$PATH:/home/hadoop/hive-0.9.0/bin
export JAVA_HOME=/usr/java/jdk1.6.0_43
3.2 $HIVE_HOME/hive-config.sh
export HIVE_HOME=/home/hadoop/hive-0.9.0 export HADOOP_HOME=/home/hadoop/mesos-0.9.0/hadoop/hadoop-0.20.205.0 export JAVA_HOME=/usr/java/jdk1.6.0_43
3.3 用默认文件生成hive-site.xml,hive-default.xml,hive-env.sh
cd $HIVE_HOME
cp hive-site.xml.template hive-default.xml
cp hive-site.xml.template hive-site.xml
cp hive-env.sh.template hive-env.sh
3.4 hive-site.xml
在结尾加上以下部分 <property> <name>hive.aux.jars.path</name> <value>file:///home/hadoop/hive-0.9.0/lib/zookeeper-3.4.3.jar,file:///home/hadoop/hive-0.9.0/lib/hive-hbase-hanlder-0.9.0.jar,file:///home/hadoop/hbase-0.92.2/hbase-0.92.2.jar</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>slavesrv1,slavesrv2,slavesrv3</value> </property>
3.5 hive-env.sh
在开头增加如下三条(因为hadoop用的mesos做资源管理)
# Google protobuf (necessary for running the MesosScheduler).
export PROTOBUF_JAR=${HADOOP_HOME}/protobuf-2.4.1.jar
# Mesos.
export MESOS_JAR=${HADOOP_HOME}/mesos-0.9.0.jar
# Native Mesos library.
export MESOS_NATIVE_LIBRARY=/home/hadoop/mesos/lib/libmesos-0.9.0.so
3.6 将一些用到的jar复制到$HIVE_HOME/lib下
cp $HADOOP_HOME/protobuf-2.4.1.jar $HIVE_HOME/lib
cp $HADOOP_HOME/mesos-0.9.0.jar
cp $HBASE_HOME/hbase-0.92.2.jar $HIVE_HOME/lib
cp $HADOOP_HOME/hadoop-core-0.20.205.0.jar $HIVE_HOME/lib
3.7 修改$HADOOP_HOME/conf/hadoop-env.sh
最后加入以下内容(否则会出现classDefNouFound的错误)
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HBASE_HOME/hbase-0.92.2.jar:$CLASSPATH:$HADOOP_HOME/bin:$HBASE_HOME/lib:$HIVE_HOME/lib
3.8 修改hive-log4j.properties
cd $HIVE_HOME/conf
cp hive-log4j.properties.template hive-log4j.properties
vi hive-log4j.properties
用'/jvm'搜索到org.apache.hadoop.metrics.jvm.EventCounter
改成
org.apache.hadoop.log.metrics.EventCounter
这样启动时候的一个警告就没了
4.使用测试
4.1 保证已经正常启动hadoop以及hbase
注意:因为采用的mesos上安装hadoop,所以hadoop启动只要到start-dfs.sh这里即可。不要start-all.sh.
然后要启动jobtracker一定要在$HADOOP_HOME下采用bin/hadoop jobtracker的方式启动,否则hive执行mapreduce任务会出错.
4.2 启动hive
hadoop@mastersrv:~$ hive
Logging initialized using configuration in file:XXXXX
file=XXXXXXX.txt
hive>
这样你就进入hive的shell了
4.3 设定参数
hive> SET mapred.job.tracker=mastersrv:54310;
4.4 测试内容
在Hive中创建一张表,相互关联的表
CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,id:val") TBLPROPERTIES ("hbase.table.name" = "test");
在运行一个在Hive中建表语句,并且将数据导入
建表
CREATE TABLE pokes (foo INT, bar STRING);
数据导入
LOAD DATA LOCAL INPATH '/home/hadoop/hive-0.9.0/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
在Hive与HBase关联的表中 插入一条数据
INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=98;
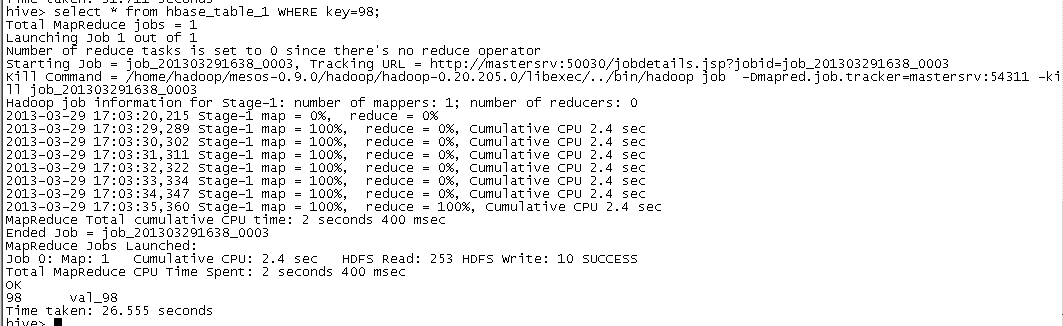
再查询下是否已经在(结果在最后)
select * from hbase_table_1 WHERE key=98;
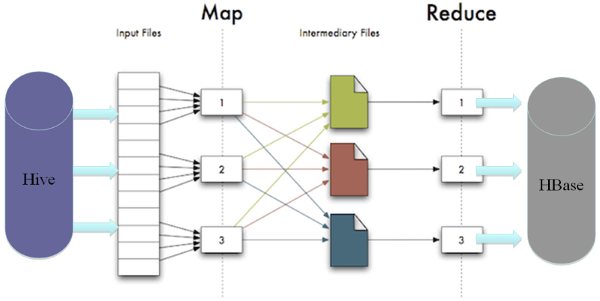
过程图:
步骤1:

步骤2:

步骤3:

步骤4:

步骤5:
PS:退出hive的shell使用quit;
可以再hbase的shell下查看test表的信息,发现已经确实存储在hbase上了

这个插入数据的操作将会变成一个mapreduce任务。并且将结果保存到hbase中。原理如下图所示。