使用场景举例
本部分内容包括:
1、学习原生api的必要性;
2、原生api的书写语法总结;
3、应用场景举例;
----------------------------------------------------------------------------------------------------------------------------------------------------------
1、学习原生api的必要性
我们对mongodb针对mongoTemplate与原生api进行了简单的使用,通过对比,可以很直观的发现mongoTemplate使用更加简单,可以在不用了解mongodb的查询api的情况下直接按照sql的查询逻辑进行书写,但一切真的那么完美么,显然不是。原生api对查询更加的灵活,更重要的是它与通过命令行以及客户端工具进行查询时,对查询条件的书写是一致的,这在开发及运维的过程中是很重要的。不熟悉mongodb的查询语法就无法展开运维工作,也很难在开发时对数据库的数据进行随时查询。
2、原生api的语法总结
首先,我们看一下mongodb查询条件的几个简单写法,毕竟复杂的查询也是简单的条件拼接出来的嘛
A、and 查询
查询 age <20 and country='china'的用户
写法:{"age":{$lt:20},"country":{$eq:'china'}}
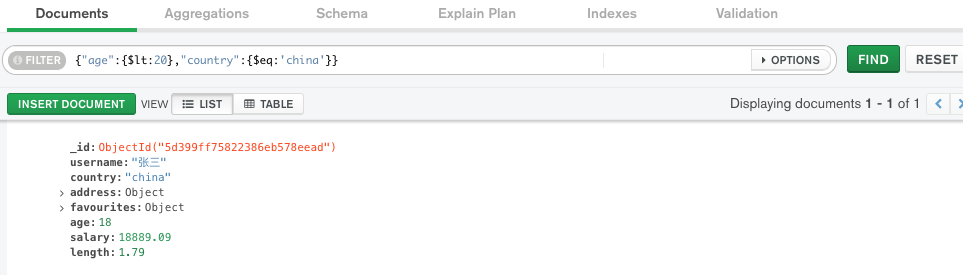
当然,这是用工具查的,如果用命令行,应该写作db.users.find({"age":{$lt:20},"country":{$eq:'china'}}).pretty(),最后的pretty是用来格式化查询结果的。
基本语法就是{"条件字段1":{运算符:目标值},"条件字段2":{运算符:目标值}},可以连续多个条件;运算符有$eq, $gt, $lt, $lte, $gte, $ne等;
B、or 查询
查询 salary > 9999 or length < 1.5
写法:{$or:[{"salary":{$gt:9999}}, {"length":{$lt:1.5}}]}
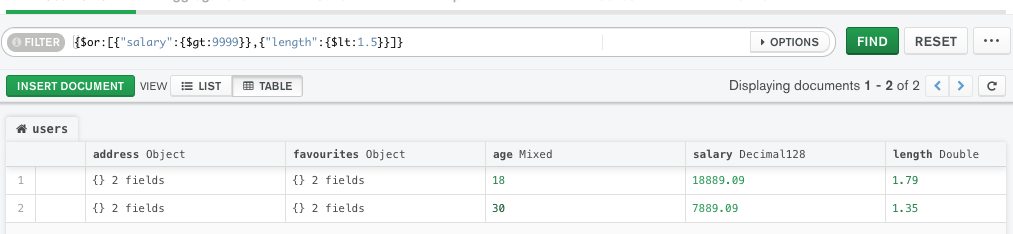
字段的条件书写还是{"条件字段":{运算符:目标值}},区别只是将所有or连接的条件组装成了一个数组,且在数组的外边有一个运算符$or;
C、and 跟 or联合使用
查询 country=china and (alary > 9999 or length < 1.5)
写法:{"country":{$eq:'china'}, $or:[{"salary":{$gt:9999}}, {"length":{$lt:1.5}}]}
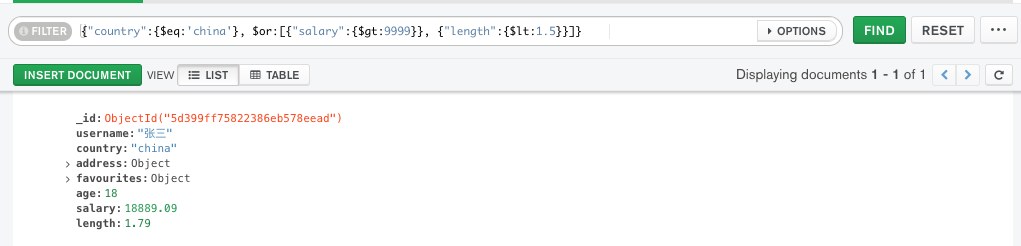
注意括号的配对,所有查询条件最外层有花括号{},具体的查询条件没有花括号,是直接键值对,键为字段名,值为一个对象,一般是判断条件跟目标值;
D、like 查询
查询 username like '张%'
写法:{"username":{$regex:'张.*'}}
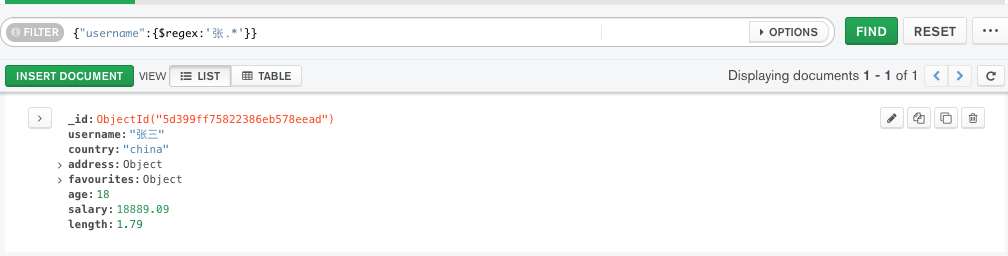
注意,这里不是百分号%,而是.*,一个小数点跟一个*号;,匹配是通过正则运算;具体的正则规则比较多,不做赘述;
E、order 排序
查询 order by age asc, salary desc
写法:sort({"age":1,'salary':-1})
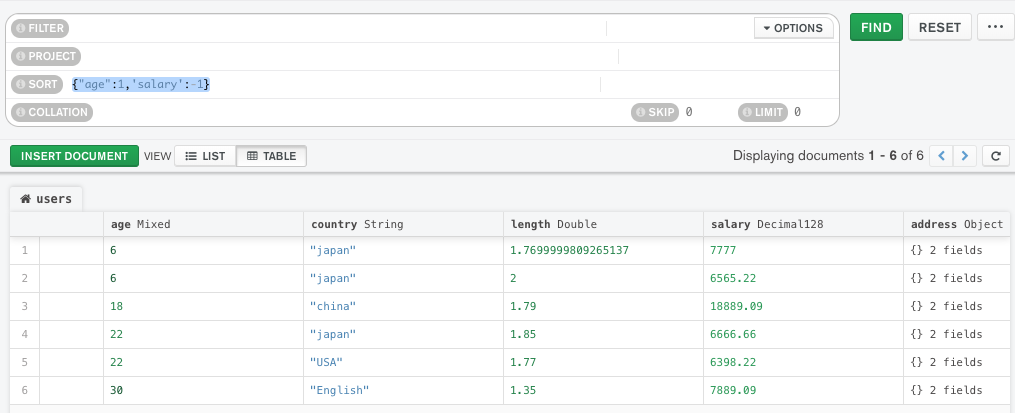
注意,这里1位升序,-1为降序排列
F、分页,查询m到n条
查询 limit m,(n-m) --mysql语法
写法:db.xxx.find().skip(m).limit(n-m)

G、group 分组
查询 select max(salary),avg(length) from users where age>18 gourp by country; 查询每个国家的最大薪资跟平均身高;
写法:
db.users.aggregate([
{
$match:{
"age":{"$gt":18}
}
},
{
$group:{
"_id":{"country":"$country"},
"avg_salary":{"$max":"$salary"},
"avg_length":{"$avg":"$length"}
}
}
])
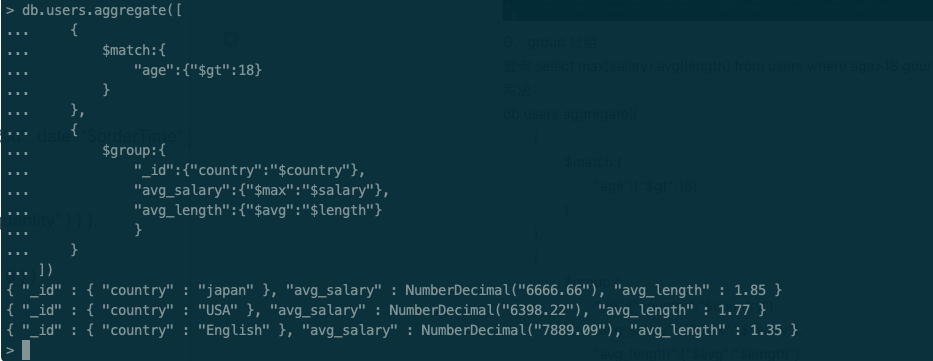
其中,$match为where的过滤条件,排序字段为$group的"_id"字段,如果有多个排序字段,直接在对象中添加即可;
以上即为常见的sql查询以及对应的mongodb的查询写法,虽然语法跟传统sql不一样,但基本逻辑并无大的差别,感性认识上,mongodb的语法结构大概就是 字段名:{比较条件:比较值},熟悉了mongodb的基本语法,我们再看几个典型的使用场景;
3、应用场景举例
实际使用中,查询一般是多个条件的组合,查询结果可能也要作相应处理,这里就会用到聚合操作。
聚合可以理解为就是一个管道,管道里的每一步的输出都作为下一步的输入数据:
输入文档 ----> 管道操作1 ----> 管道操作2 ----> 管道操作3 ----> 输出文档
常用的管道操作:
$project: 投影,指定输出文档 中的字段
$match: 过来条件
$limit: 限制返回的文档数
$skip: 跳过指定数量的文档
$unwind: 将文档中的某一个数组类型的字段拆分为多条,每条包含数组中的一个值
$group:将集合中的文档分组,用于统计结果
$sort:将输入文档排序后输出
应用举例:
1、假设微博用户信息存放在mongodb中,要求用户界面默认显示3条评论,点击显示更多,可以查看接下来的4条记录;数据格式如下:
数据:
var cang = {"username" : "cang laoshi",
"country" : "japan",
"address" : {"aCode" : "411000","add" : "东郡"},
"favorites" : {
"movies" : ["蜘蛛侠","钢铁侠","蝙蝠侠"],
"cites" : ["青岛","东莞","上海"]
},
"salary":NumberDecimal("9999.88"),
"comments":[
{
"author": "jack1",
"content": "jack的评论1",
"commentTime": ISODate("2017-12-11T04:26:18.234Z")
},
{
"author": "jack2",
"content": "jack的评论2",
"commentTime": ISODate("2017-12-12T04:26:18.234Z")
},
{
"author": "jack3",
"content": "jack的评论3",
"commentTime": ISODate("2017-12-13T04:26:18.234Z")
},
{
"author": "jack4",
"content": "jack的评论4",
"commentTime": ISODate("2017-12-14T04:26:18.234Z")
},
{
"author": "jack5",
"content": "jack的评论5",
"commentTime": ISODate("2017-12-15T04:26:18.234Z")
},
{
"author": "jack6",
"content": "jack的评论6",
"commentTime": ISODate("2017-12-16T04:26:18.234Z")
},
{
"author": "jack7",
"content": "jack的评论7",
"commentTime": ISODate("2017-12-17T04:26:18.234Z")
}
]};
db.users.insert(cang);
应该这么写:
db.users.find({"username":"cang laoshi"},{"comments":{"$slice":[3,4]},"$elemMatch":""})
解释一下:find()中两个参数,第一个为查询条件,必须有,第二个参数为投影设置,可有可无;投影的意思是从查询结果中只找我们需要的进行显示,而把敏感信息隐藏;一般写法为{字段名:1,字段名2:0} 1的意思为显示,0为隐藏,需要注意的是写的时候,如果多个字段,要么都是1要么都是0,混搭是不行的,mongodb约束如此,没得解释;$slice用于返回内容片段而不是全部,后边[3,4]的意思为从第3个元素(从0开始计数)连续取4个;$elemMatch一般用于内嵌文档匹配,此处用作投影使用;

需要注意的是,此处如果不使用$elemMatch,而仍需要只有comments投影的效果,在comments跟$slice后添加comments:1是无效的,因为后面的会把前边的配置覆盖掉,最终效果是查询并显示了所有的comments;避免方式之一是将评论放在comments.list中,也就是将文档多添加了一层list,可以在设置$slice的时候用comments.list,但这样会导致文档结构多了一层无用list,这么设计并不好。
2、数据结构仍然跟上结构类似,但增加几条数据,然后查询 tony1或者jack1 评论过的用户
应该这么写:db.users.find({"comments.author":{"$in":["tony1","jack1"]}})
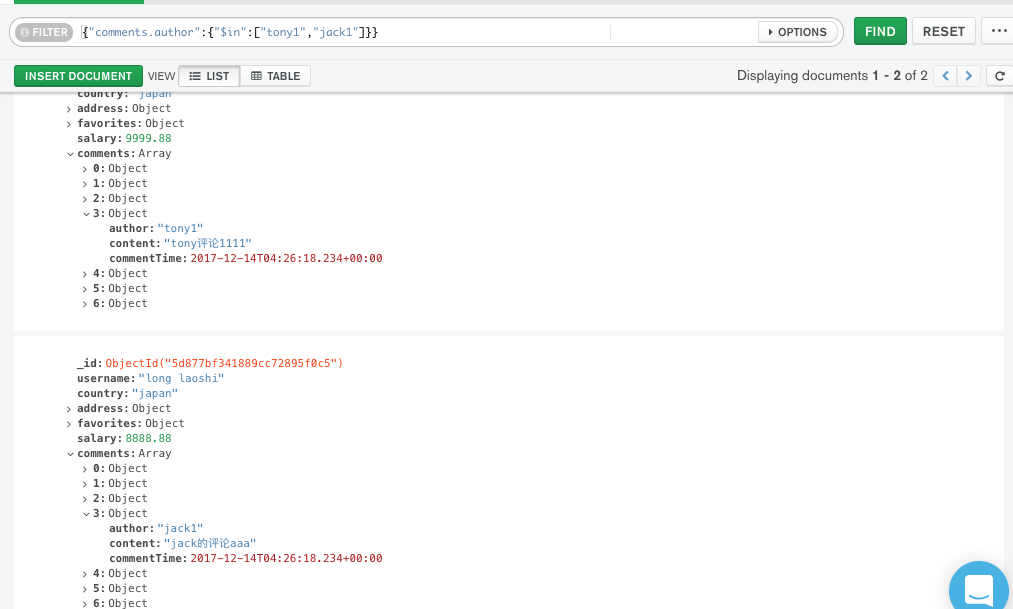
当然,这里也可以用or来实现,写的会略微复杂一些;同理,另一个问题,tony1跟jack1都评论过的用户应该怎么写呢?
答案:db.users.find({"comments.author":{"$all":["tony1","jack1"]}})
3、查找jack3的评论为"板凳板凳"的用户名
db.users.find({"comments":{"$elemMatch":{"author":"jack3","content":"板凳板凳"}}})
4、将1 的场景详细化:
查看评论,打开页面默认显示3条;点击查看更多,新加载3条;按照评论时间降序排列;
解决办法之一:
1、查找的时候进行排序,先排序后查找,相对来说是比较麻烦的,但可以在新增的时候就对评论进行排序,那么查询的时候就无序关心排序问题了;
2、默认3条跟查看更多类似于分页,在示例1中有;
3、如果有多种排序需求,该如何处理;
按照上面思路,新增评论:
db.users.updateOne({{"username":"name111"},{
"$push":{
"comments":{
"$each":[{
"author":"james",
"content":"我的评论aaa",
”commentTime“:ISODate("2019-01-09T04:23:23.233Z")
},
{
"author":"james2",
"content":"我的评论aaa2",
”commentTime“:ISODate("2019-02-09T04:23:23.233Z")
}],
"$sort":{"commentTime":-1}
}
}
}});
updateOne的两个参数分别为查询条件跟更新的数据,$push为新增之意,comments为更新的字段,$each表示所有数据都遵循此操作,$sort为插入时的排序字段,-1表示倒序;
分页查询,不再赘述,只提供一种写法:db.users.find({"username":"cang laoshi"},{"comments":{"$slice":[0,3]},"id":1});会只显示id跟comments,且comments只有3条;
对于排序,我们的解决思路是插入的时候就进行排序,但这里有个问题,如果我们有多种排序需求,比如按照评论的点赞数进行排序,或者按照作者的知名度(知名度的计算过程不考虑)进行排序,该怎么处理?答案是使用聚合,例如:
db.users.aggregate([
{"$match":{"username":"cang laoshi"}},
{"$unwind":"$comments"}, //将文档中的某一个数组类型字段拆分为多条,没条包含数组中的一个值
{"$sort":{"comments.author.xxx":1}}, //排序
{"$project":{"comments":1}}, //投影
{"$skip":0},
{"$limit":3}
])
unwind这个不太好理解,参考文章https://www.cnblogs.com/wangxiaoheng/articles/9699625.html这个有个例子,说的比较清楚了;
不过多举例了,通过以上我们发现,mongodb的查询api还是比较琐碎的,想要用好的话,还是需要一定练习的。
回想一下mongodb的查询api,假设有这么个需求,该怎么查:有个订单表,要求统计2016年5月6号之前,每个用户每个月消费了多少钱,并按照用户名排序
答案:
db.orders.aggregate([
{"$match":{"orderTime":{"$lt":new Date("2016-05-06T00:00:00.000Z")}}},
{"$group":{"_id":{"userName":"$useCode","month":{"$month":"$orderTime"}},"total":{"$sum":"$price"}}},
{"$sort":{"total":1}}
])
----------------------------
我们注意到,上边的查询示例并没有join操作,是mongodb不支持关联查询么?
这个,倒不是说mongodb不支持关联查询,如果要做的话也是可以的,这就是DBRef相关内容,但mongodb的设计理念是尽量使用单表内嵌,而不是表关联;比如,论坛系统,如果用关系库来设计,可能要有用户表,论贴表,评论表等,但用mongodb的话,可能一个用户表就够了,发表的帖子,自己的评论等都作为字段内容内嵌到用户信息里边即可,这也是mongodb设计的方便之处;但mongodb约束单个文档内容不能超过16M,当超过16M的时候,需要选择DBRef,将大数据放到另外一张表中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号