elasticsearch 初步
本文主要内容:
1、elasticsearch的认识(是个啥,能干啥)
2、安装启动、简单集群及关键配置
3、名词解释
4、存取数据,中文分词
---------------------------------------------------------------------------------------------------
1、elasticsearch的认识
elasticsearch是一个开源的实时分布式搜索分析引擎,底层使用lucene实现。lucene使用较为复杂,es将其做成一个单独的服务,方便开发人员使用。这么说不太方便理解,通俗的讲,可以把它理解成一个分布式的海量数据库,而且使用方便。
比较详细的介绍可以参考官网的文档以及权威指南:
2、安装启动、简单集群及关键配置
该部分就是一个安装过程,附带了配置说明
a、单机版
单节点的es比较简单,直接下载启动即可;
下载:https://www.elastic.co/downloads在官网点击下载,找自己需要的版本下载即可;
启动:解压后,bin目录,./elasticsearch 回车即可。
注意:不可用root账号启动,因为es为了防止危险脚本的注入,禁止root启动;内存不要过小,默认内存配置是1G,如果当前内存小于1G,会报错,考虑加大内存或者修改es默认内存配置,es默认占用的jvm堆内存大小设置路径:config/jvm.options中的-Xms跟-Xmx。
b、集群搭建
一般是3点集群或者5点集群,理由当然是尽量防止脑裂问题。本地只有一台虚拟机,比较懒,就双机集群吧。
|
a
|
172.20.10.2
|
9200
|
物理机
|
|
b
|
172.20.10.3
|
9200
|
虚拟机
|
使用的es版本为6.4.3,要修改的配置文件为conf/elasticsearch.yml,主要修改以下选项:
#集群名称 cluster.name: my-application #节点名称 node.name: node-1 # 是否可以作为master节点,默认true node.master: true #本机地址 network.host: 172.20.10.2 #本机es端口 http.port: 9200 #单播模式下,具有master资格的节点列表,新加入的节点向这个列表中的节点发送请求来加入集群 discovery.zen.ping.unicast.hosts: ["172.20.10.2", "172.20.10.3"] #一个节点需要看到的具有master资格的节点的最小数量 discovery.zen.minimum_master_nodes: 1
以上,集群名称用于区分网络环境中的不同es集群。集群中,不是所有节点都会参与master选举,这样的话会因为节点太多而过于复杂,故一般es集群中只设置几个节点用于master,其它节点只作为数据节点,不参与主节点竞争;有master资格的节点需要尽量让其它节点看到自己;一个节点需要看到一定数量的具有master资格节点才能加入集群并在其中执行操作,官方推荐的数字是(N/2)+1,其中N为具有master资格的节点数量;
当然,生产环境的话,一般数据跟程序是不在同一目录的,主要目的是方便es的版本升级,避免数据覆盖。因此我们把数据跟日志目录移动到别的目录:
#es的数据存储目录 path.data: /var/elasticsearch/data #es日志存储目录 path.logs: /var/elasticsearch/logs
相应的,es的配置文件在每次升级之后也会被覆盖,这不是我们想要的,故而也应该提取出来。比如本次是将config移动到了/opt/elasticsearch/目录下,同目录下有elasticsearch-6.4.3目录,也就是我们es的home目录。修改后,相应的启动有两种方式:
a、参数启动
在es的home目录/bin下执行 ES_PATH_CONF=/opt/elasticsearch/config ./elasticsearch
b、设置环境变量
在~/.bash_profile添加
ES_PATH_CONF=/opt/elasticsearch/config export ES_PATH_CONF
两行,然后可以正常启动。
分别启动,结束后执行:curl -X GET "http://172.20.10.2:9200/_cat/health?v",查看集群运行状态:

node.total是所有节点数量,可以看到有两个节点。
本次启动过程中碰到两个问题:
ERROR: [2] bootstrap checks failed [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
第一个问题,是说当前es用户拥有的可创建文件描述的权限太低,解决办法:
切换到root用户进行修改:
vi /etc/security/limits.conf
在最后添加:
*** hard nofile 65536 *** soft nofile 65536
其中,*** 是启动ES的用户
第二个问题,是单个jvm能开启的最大线程数太小,
切换root用户,执行:sysctl -w vm.max_map_count=655360进行修改即可。
3、名词解释
虽然es已经启动起来了,可我们貌似对它并没有什么了解,那就从名词解释开始吧!
近实时:es是一个近乎实时的搜索平台,所谓近实时就是说从索引文档到返回结果还是需要一点时间的,但不太长,通常是1秒。
索引:(名词)es存储数据的地方,是具有某些类似特征的文档的集合。类似于关系数据库中的“数据库”或者“表”。
(动词)将数据存到es的索引的过程,叫做索引。
文档:文档是es中的一个json文件,相当于关系数据库中的一行记录。文档存储在索引中,有类型跟id。一个索引可以保存多种类型的文档,相当于一个student表中可以放teacher跟student,不太贴切,但暂且这么理解吧。es7中类型将被删除,相当于与student表只能存student数据了。
类型:就是orm中的那个o的类型吧,es7中将被移除。
分片:数据存储在索引中,索引的存储量可能会超过单个节点的硬件限制条件。比如1TB大小的索引,如果放在单节点,会因为太大而导致搜索太慢或者干脆硬盘没有这么大,而无法进行存储。为了解决这个问题,es提供了分片机制,在创建索引时指定分片数量,指定后不可更改。每个分片都是一个功能齐全且独立的“索引”。
分片副本:顾名思义,就是分片的一个拷贝,在发生网络故障时可以保证损坏的节点数据正常使用。
4、存取数据,中文分词
对es数据的操作可以通过es提供的rest api来完成,curl命令不方便使用,之前有chrome插件sense可以方便使用,但最新的chrome商店中删掉了该插件,网络上的改版也会被浏览器提示安全问题或者编码问题,我们此处使用kibana。
kibana默认连接localhost,需要在es的配置文件中添加 network.host: [localhost, 172.20.10.2],否则会导致无法连接到es。启动后访问localhost:5601 --> Dev Tools 打开es 的rest api访问工具。
a、增
添加一条数据到megacorp索引的employee类型下,id是1:
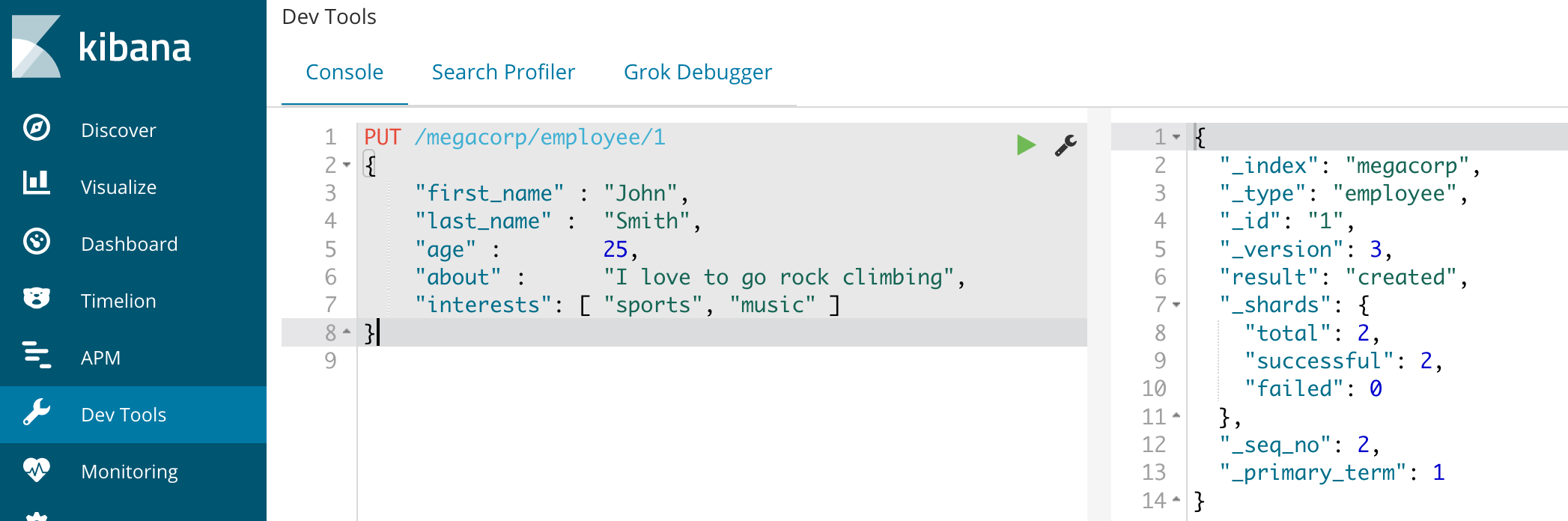
右边,_version表示该记录的版本号,3表示被修改过3次,我本地是增加后删除了一次,第二次新增,故而版本是3。
批量增加:

批量处理有一些格式上要注意的地方:
1、操作命令跟内容交替出现,每个独占一行;
即使文档内容有很多,都是json格式,必须在一行,否则会报错:"type": "illegal_argument_exception", "reason": "Malformed action/metadata line [3], expected START_OBJECT but found [VALUE_STRING]"
2、更新操作要有doc或者script,否则报错:Validation Failed: 1: script or doc is missing
3、操作有4种,index、create、update跟delete,index跟create的区别是如果存在,是否替换,index会替换,create不会。
b、删
单条删除比较简单,就是delete /索引名/类别/id ,比较常用的是通过查询api来删除
删掉年龄为32的员工:

c、改
update在上文增操作中有涉及;
通过脚本,将id为3的员工年龄加5
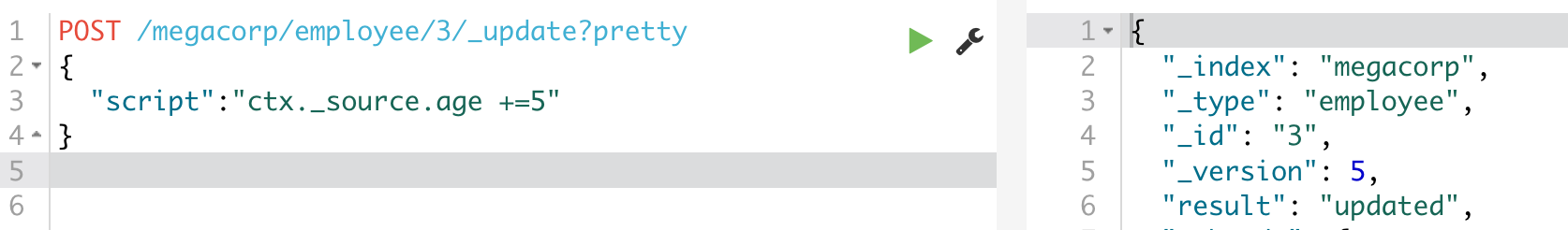
当然也有按api查询进行更新:https://www.elastic.co/guide/en/elasticsearch/reference/6.4/docs-update-by-query.html
d、查
查询单个: get /索引/类型/id,条件查询的api比较复杂;
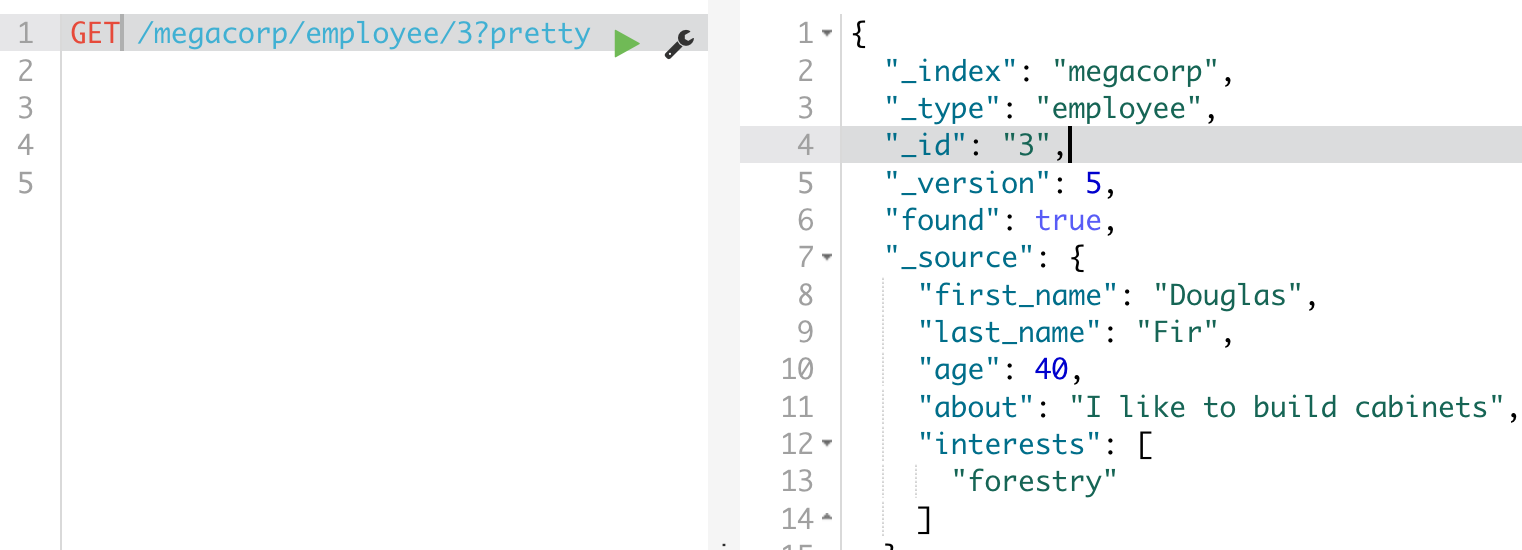
整个的查询api还是有些复杂的:https://www.elastic.co/guide/en/elasticsearch/reference/6.4/getting-started-search-API.html
中文分词
es自带的默认分词器对中文的处理是拆成一个个汉字进行处理的,这显然不合理,比较好用的中文分词器是ik分词器https://github.com/medcl/elasticsearch-analysis-ik
找到es对应版本,下载解压,然后在es/plugins下建ik文件夹,放到这里后重启es即可。该部分详细操作请参照https://www.cnblogs.com/zlslch/p/6440373.html
本地安装完成后测试:
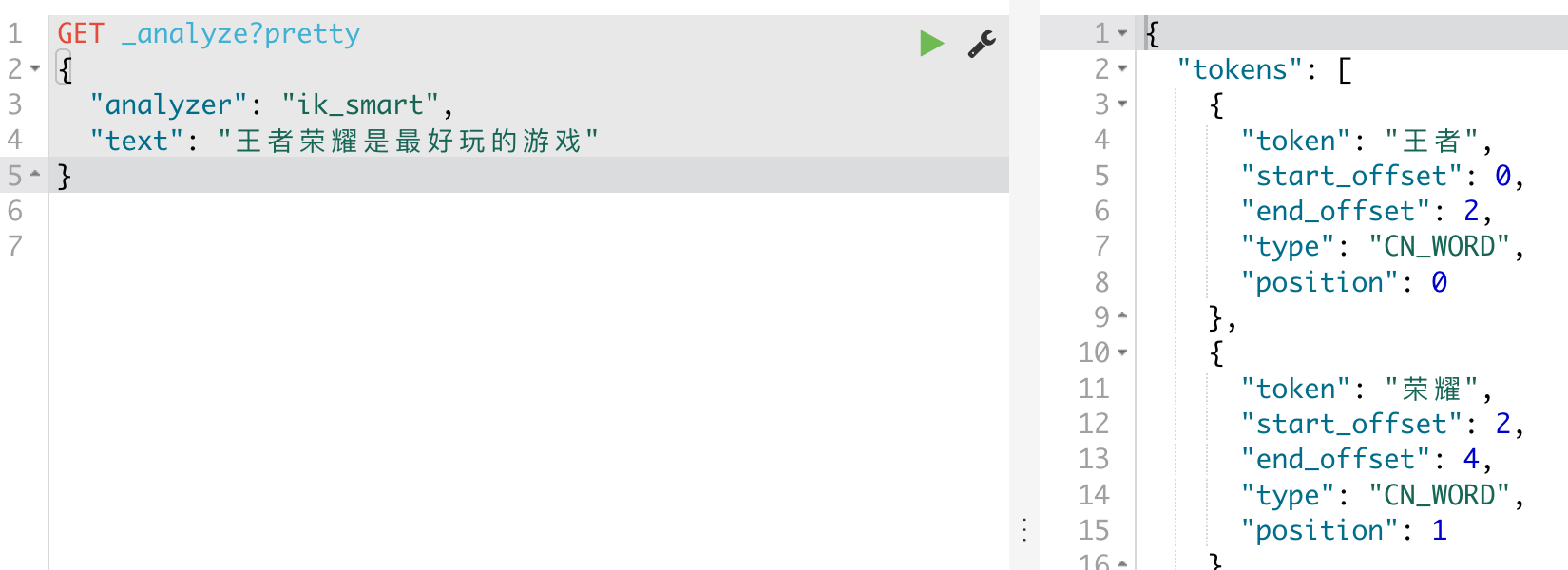
可以看到,把王者跟荣耀分别作为了一个单词,虽不是我们期望的,但也还可以理解。通过分词器,我们还可以自定义词语,近义词等。
---------------------------------------------------------------------------------------------------
大概就先这样吧,稍后分析es的内部数据存储逻辑以及分词器的一些常用操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号