缓存穿透
一、什么是缓存穿透
面试的时候经常被问到redis缓存穿透怎么解决,其实不止是redis,其他的缓存系统可能也存在这样的问题,除了缓存穿透,还有缓存击穿,缓存雪崩等问题。我们知道,在开发一个高并发的应用的时候,考虑到数据库的压力,我们一般都会在服务层和存储层加上缓存系统,来减轻数据库的负担,每次请求都会先查缓存,如果缓存不存在才查询数据库,如果从数据库查询到了结果,则把查询到的结果写入缓存,当下次再次查询这个数据的时候就直接从缓存中取数据,不走数据库。
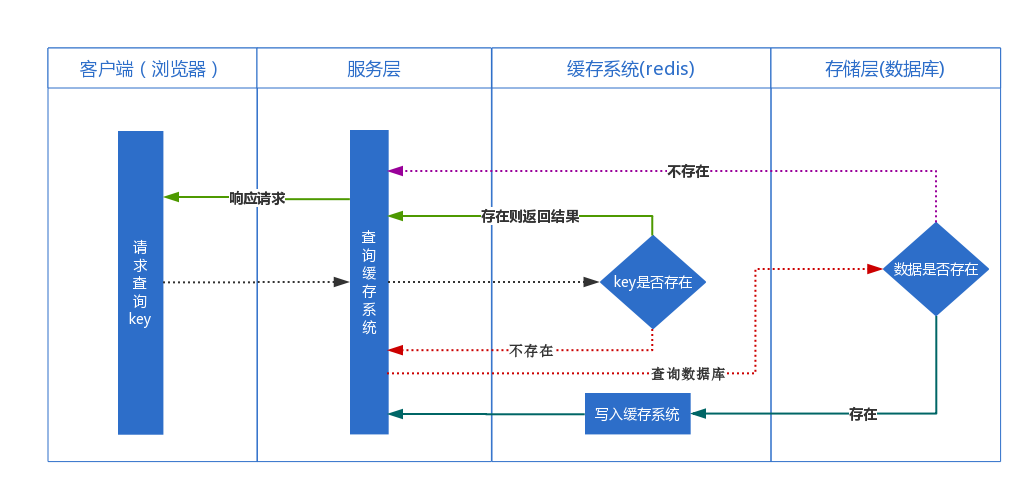
缓存穿透:指从缓存系统中查询一个不存在的数据或者说是查询一个不存在的key时,被查询的key保证肯定是不存在的,那么我们就需要去存储层(数据库)中查询是否存在,如果查询不到数据则不写入缓存,那么将导致这个不存在的数据每次请求都要查询存储层,当有人利用不存在的key频繁攻击我们的应用,并且流量很大的时候,数据库很有可能会挂掉,缓存也就失去了意义。
二、解决方案
解决的办法常用的有两种:
1)缓存空对象
如果我们在数据库中没有查询到数据,那么我们也可以把这个空结果添加到缓存,这样下次再遇到这个不存在的key,就不走数据库了。这样会引发两个问题:问题1、浪费内存。虽然缓存的value为空,但是这样的key-value对在很多的情况下还是很耗内存空间的。解决方案是:需要给每个空值的key-value对设置一个较短的过期时间,最好不要超过5分钟。问题2:缓存和数据不同步。当数据库中真的存在这个key的时候,假如这个key的缓存时间设置的为5分钟,那么这5分钟内数据都是不一致的。解决方案是:使用消息队列或者其他方式,当数据库的数据变更的时候,清除这个被缓存的key。这种缓存空对象的方案适合数据频繁变化实时性高的场景
2)使用布隆过滤器拦截
将所有存在的key使用布隆过滤器保存起来,在请求资源之前,先在控制层去查询这个key在布隆过滤器中是否存在。不存在则直接丢弃请求,减轻存储层的压力。这种方式适合数据相对固定,实时性低的场景,当然空间利用的也比较少。下面来说下什么是布隆过滤器:
布隆过滤器:是一种多哈希函数映射的快速查找算法。它可以判断出某个元素肯定不在集合里或者可能在集合里,即它不会漏判,但可能会误判。通常应用在一些需要快速判断某个元素是否属于集合,但不严格要求100%正确的场合。为什么说可以判断出某个元素肯定不在集合中,或者可能在集合中呢,看下原理就明白了。
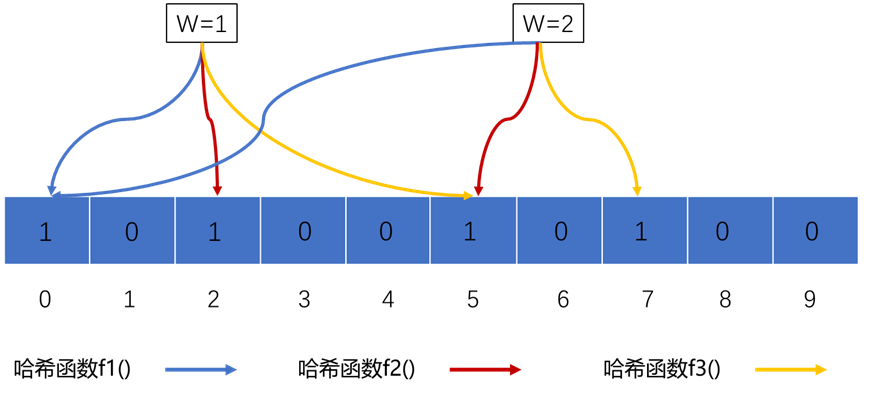
基本原理:一个空的布隆过滤器是一个m位的位数组,什么是位,一个字节是8位,说的就是那个位。初始的时候所有位的值都为0。定义了k个不同的符合均匀随机分布的哈希函数,每个函数把要添加的元素映射到位数组的m位中的某一位。也就是说,假如我们要存放一个元素w=1,位数组长度m=10,一共有3个哈希函数(k=3),假设分别为y1=f1(x),y2=f2(x),y3=f3(x),w分别经过这三个哈希函数计算后的值为0 2 5,也就是说w哈希后落在了第0,第2,第5位,所有这几个位置在位数组中的值就为1。即位数组为:1 0 1 0 0 1 0 0 0 0,如果再有个元素w=2添加到位数组呢?那么还是通过这个三个哈希函数去计算它落在位数组的那个位置,假如为0 5 7 ,然后对应位置置为1,但是这样就会有个问题,如果客户端查询一个元素,先经过布隆过滤器,假设元素w=3,哈希后它的位置是 0 2 7,你会发现其实我们没有插入w=3这个元素,但是它哈希后的位置的值都是1,因为刚刚插入w=1和w=2的时候对应的位置已经置为1了,这种情况就是误判。但是布隆过滤器可以保证某个元素肯定不在集合中,加入w=4,哈希后的位置为 0 3 5,发现位置3的值为0,说明w=4肯定是不存在的,因为如果它存在,那么3的位置就不可能为0。这样也就能解释前面那句话“可以判断出某个元素肯定不在集合中,或者可能在集合中”。有一点需要注意,布隆过滤器不支持删除一个key,因为有可能其他的key也映射到要删除key的某个位置上,一旦删除就混乱了。
关于误判率的计算,请参考:https://www.cnblogs.com/Jack47/p/bloom_filter_intro.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号