Java线程池
一、什么是线程池
为了避免系统频繁的创建线程,我们可以让创建的线程复用。由线程池统一管理线程的创建和回收以及销毁的过程,当使用需要使用一个线程的时候,就从线程池中取出一个空闲线程,当完成工作后,并不是关闭线程,而是将这个线程退回到线程池,供其他任务使用。创建线程池的几个原因:
- 频繁的创建销毁线程可能会耗尽cpu和内存资源
- 任务的执行时间在小于创建和销毁线程的时间的情况下,得不偿失。
- 线程本身需要占用内存空间,大量的线程会抢占宝贵的内存资源。
- 大量线程的回收会给GC带来压力,延长GC的停顿时间。
在java中提供了一套Executor框架,类ThreadPoolExecutor表示一个线程池。而Executors类扮演着线程池工厂的角色,使用Executors可以获取一个拥有特定功能的线程池。线程池的核心成员如下图:
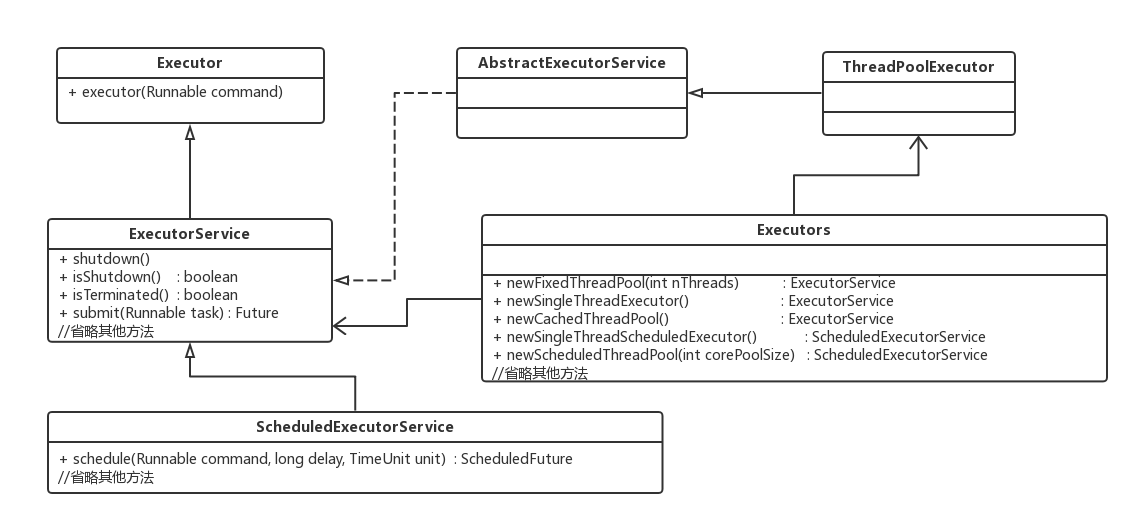
二、创建线程池
我们可以使用Executors提供的几个工厂方法进行创建,主要方法包括:
- public static ExecutorService newFixedThreadPool(int nThreads)
- public static ExecutorService newSingleThreadExecutor()
- public static ExecutorService newCachedThreadPool()
- public static ScheduledExecutorService newSingleThreadScheduledExecutor()
- public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
以上每个方法都返回具有不同功能的线程池,详细介绍如下:
newFixedThreadPool(int nThreads)方法:
该方法返回一个固定线程数量的线程池。线程池中的数量始终不变,当有新的任务提交时,线程池中如果存在空闲线程,则立即执行。若没有,则新的任务会暂存在一个等待队列中,等有空闲的线程的时候再执行任务队列中的任务。
newSingleThreadExecutor()方法:
该方法返回一个只有一个线程的线程池。如果要提交的任务大于一个,则多余的任务会被保存到任务队列,等到线程空闲,按照先入先出的顺序执行队列中的任务。
newCachedThreadPool()方法:
该方法返回一个可以根据实际任务情况而调整线程数量的线程池,线程池的数量不确定。如果有空闲线程,则使用空闲线程,如果所有的线程都在工作,则新任务提交的时候会新建一个线程来处理任务。线程在执行完毕后,将返回给线程池进行复用。
newSingleThreadScheduledExecutor()方法:
该方法返回的对象是ScheduledExecutorService类型的,线程池大小为1,ScheduledExecutorService相当于在ExecutorService接口上扩展了在给定时间执行任务的功能,例如可以在某个固定的延时后执行任务,或者周期性的执行任务等。
newScheduledThreadPool(int corePoolSize)方法:
该方法返回一个ScheduledExecutorService对象,它除了可以定时执行任务外,还可以指定线程池的线程数量。
1、创建固定大小的线程池:
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ThreadPoolExecutorDemo { public static void main(String[] args) { ExecutorService threadPool = Executors.newFixedThreadPool(3); Task t = new Task(); for(int i = 0; i < 9; i++) { threadPool.submit(t); } threadPool.shutdown(); } } class Task implements Runnable{ @Override public void run() { //任务执行时间为2秒 System.out.println(Thread.currentThread().getId() + ":" + System.currentTimeMillis() / 1000); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } } //输出: 10:1534431428 11:1534431428 12:1534431428 10:1534431430 12:1534431430 11:1534431430 10:1534431432 12:1534431432 11:1534431432
从上面的代码输出的结果可以看出,我们创建了具有3个线程的线程池,每次最多有三个任务同时执行,我们提交的9个任务会分批执行,而且每一批执行时间正好差2秒钟。
2、创建计划任务线程池
newScheduledThreadPool()方法返回一个ScheduledExecutorService对象,它的主要方法如下:
-
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); //command代表任务,delay代表多长时间后执行,unit是时间单位。这个任务只会执行一次
-
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); //command代表任务,initialDelay代表延迟,就是多长时间后开始执行第一次任务,period代表周期,就是每period秒执行一次任务,unit代表时间单位。如果任务的执行时间小于period,那么任务会正常的每period时间执行一次,而如果任务执行时间大于period,那么任务相当于不间断的执行。
-
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit); //command代表任务,initialDelay代表延迟,就是多少秒后开始执行第一次任务,delay代表两次任务之间间隔多少秒,unit是时间单位,相当于每隔任务执行时间和delay时间之和的时间后执行一次。
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class NewScheduledThreadPoolDemo { static class Task implements Runnable{ @Override public void run() { System.out.println("当前执行任务的时间戳:" + System.currentTimeMillis() / 1000); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { ScheduledExecutorService pool = Executors.newScheduledThreadPool(3); Task t = new Task(); pool.schedule(t , 3, TimeUnit.SECONDS); //3秒后执行任务1次 //pool.scheduleAtFixedRate(t, 0, 2, TimeUnit.SECONDS); //每2秒执行一次任务 //pool.scheduleWithFixedDelay(t, 0, 3, TimeUnit.SECONDS); //上一次任务执行完毕后再过3秒执行下次任务 } }
三、线程池的内部实现原理
前面说的几种创建线程池的方法,其实原理都是调用了ThreadPoolExecutor的构造方法实现的,只是传入的参数不一样。
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
下面来详细的分析下ThreadPoolExecutor这个类的构造方法的参数,首先给出一个参数最齐全的构造方法:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
函数的参数含义如下:
- corePoolSize:指定了线程池中的线程数量。
- maximumPoolSize:指定线程池中的最大线程数量。
- keepAliveTime:当线程池数量超过corePoolSize的时候,多余的空闲线程的存活时间,也就是说这些超过corePoolSize的空闲线程,在多长时间后会被销毁。
- unit:KeepAliveTime的时间单位。
- workQueue:任务队列,被提交但是未执行的任务都会保存在任务队列中。
- threadFactory:线程工厂,用来创建线程,一般都用默认的即可。
- handler:拒绝策略。当任务太多无法处理的时候,如何拒绝任务。
线程池的逻辑调度:
当线程池中的线程数小于corePoolSize的时候,如果有任务提交,则新建线程,使用线程工厂threadFactory创建。若大于corePoolSize,则会把新的任务添加到等待队列workQueue里,这里的等待队列也有不同的类型,不是说等待队列想添加就添加的,下面会详细说。如果等待队列满了,并且总线程数不大于maximumPoolSize,则继续创建新的线程执行任务。如果线程数已经达到maximumPoolSize,且等待队列也满了,那么就会执行拒绝策略,相当于调用handler.rejectedExecution(Runnable r, ThreadPoolExecutor e)方法,拒绝策略有四种,下面会详细说,每种拒绝策略的处理都不一样。当线程池中线程数量大于corePoolSize,并且存在空闲线程的时候,这些多余的线程最多存活keepAliveTime长时间,时间单位是unit。
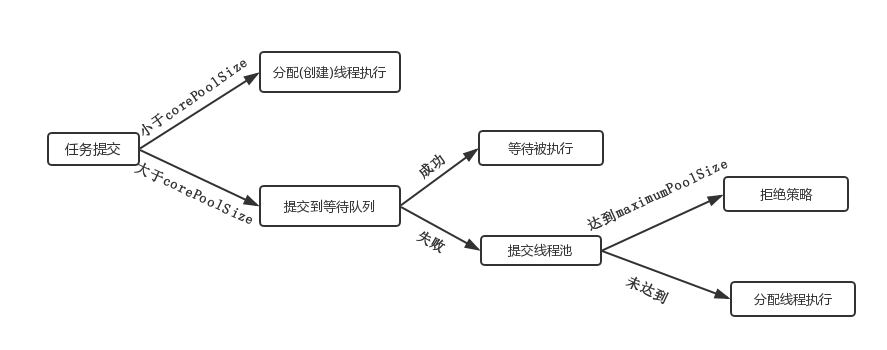
任务队列workQueue详解:
从上面的分析我们知道,当没有线程供任务使用的时候,提交的任务就会被加入到等待队列。这个参数是BlockingQueue接口类型的,泛型是Runnable,根据功能不同,在线程池的构造方法中可以使用下面几种类型的BlockingQueue。
- 直接提交的队列:该功能使用SynchronousQueue实现。它是一个特殊的BlockingQueue,SynchronousQueue没有容量,每个删除操作都要等待一个相应的插入操作,每个插入操作要等待每个删除操作。提交的任务不会真实的保存,而总是将新任务提交给线程池。如果没有空闲的线程,则尝试新建线程,如果线程数已达到最大值,那么执行拒绝策略。如果使用SynchronousQueue队列,通常maximumPoolSize一般要设置的很大,否则很容易就会执行拒绝策略,例如newCachedThreadPool()就是使用的这种方式,参考上面给出的三个构造方法。
- 有界的任务队列:可以使用ArrayBlockingQueue实现,构造方法必须指定队列的容量。public ArrayBlockingQueue(int capacity),如果使用的是有界队列,那么很好理解,当线程池中的线程数小于corePoolSize,并且有新的任务提交时,就会新建线程。如果达到corePoolSize,则会将新任务加入等待队列,如果等待队列已满,没有空闲线程,并且总线程未达到maximumPoolSize,则继续新建线程执行。如果等待队列也满了,线程也达到最大了,那么将执行拒绝策略。也就是或,只有在有界队列满的时候,才有可能把线程数提升到corePoolSize以上。
- 无界的任务队列:可以使用LinkedBlockingQueue实现,它与有界队列相比,除非系统资源耗尽,否则无界队列永远不存在入队失败的情况。也就说,线程数达到corePoolSize的时候,就不会继续往上加了,如果有空闲线程,就执行新任务,否则就入队,因为等待队列永远不会满,所以参数maximumPoolSize就没什么意义了,当然了无界队列也可以指定容量大小。newFixedThreadPool和newSingleThreadExecutor使用的就是没有指定大小的无界队列作为等待队列。
- 优先的任务队列:它相当于带有执行优先级的队列,通过PriorityBlockingQueue实现,可以控制任务的执行先后顺序,它同时也是一个无界队列。对于有界队列ArrayBlockingQueue,或者未指定大小的无界队列LinkedBlockingQueue,都是按照先进先出的算法处理的,而PriorityBlockingQueue则可以根据任务自身的优先级顺序先后执行。
从前面的分析,我们再来看下前面讲的几种线程池,newFixedThreadPool()它实际上返回一个corePoolSize和maximumPoolSize大小一样的,并且使用无界队列LinkedBlockingQueue作为任务队列的线程池。当任务提交频繁的时候,虽然不会执行拒绝策略,但是队列的迅速膨胀,有可能导致系统资源耗尽。newSingleThreadExecutor()返回的是单线程线程池,相当于newFixedThreadPool()方法的一种特殊情况。而对于newCachedThreadPool()方法返回一个corePoolSize为0,maximumPoolSize为无穷大的线程池,这意味着没有任务的时候,该线程池内无线程,而当任务被提交的时候,且没有空闲线程的时候则会加入到等待队列,前面说了newCachedThreadPool是使用SynchronousQueue作为等待队列,SynchronousQueue是一种直接提交的队列,它总是迫使线程池增加新的线程执行任务,当任务执行完毕后,由于corePoolSize=0,因此空闲线程在指定的60秒被回收。
拒绝策略详解:
当任务数量超过线程池可以处理的范围的时候,还要定义一些后序的处理机制,这时就需要使用拒绝策略,拒绝策略相当于系统超负荷运行的时候的补救措施。JDK内置了四种拒绝策略:
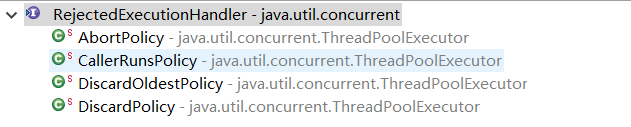
这四种策略类都是RejectedExecutionHandler接口的子类,接口中只有一个抽象方法就是void rejectedExecution(Runnable r, ThreadPoolExecutor executor);这四个类都是在线程池类ThreadPoolExecutor内部实现的。当执行拒绝策略的时候,相当于调用handler.rejectedExecution()方法
- AbortPolicy策略:该策略直接抛出异常,这也是ThreadPoolExecutor类的默认拒绝策略。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString()); }
- CallerRunsPolicy策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务,这样做虽然不会丢弃任务,但是,任务提交的性能就可能会急剧下降。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } }
- DiscardOledestPolicy策略:该策略会丢弃最老的请求,也就是下一个将被执行的任务,然后尝试再次提交任务。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } }
- DiscardPolicy策略:它相当于直接丢弃任务,不做任何处理。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { }
当然,我们也可以自己扩展拒绝策略,只要handler参数传入一个RejectedExecutionHandler接口的子类就行,拒绝策略我们自己去实现。
线程的创建:
前面介绍的内容基本上已经把线程池的原理说的差不多了,但是我们还不知道线程是怎么创建出来的。之前介绍的ThreadPoolExecutor类的构造方法中有一个参数是threadFactory,它是ThreadFactory类型的,而在ThreadFactory接口中就一个抽象方法Thread newThread(Runnable r);这个方法就负责创建线程,一般情况下,我们使用默认的就行。Executors类有个defaultThreadFactory()方法,可以为我们返回一个ThreadFactory的子类对象,当然我们也可以自己扩展,自己实现newThread()方法。
四、扩展线程池
如果我们向对每个任务进行监控,例如在任务执行前和执行后做一些操作,应该怎么办呢?java已经帮我们想好了。在ThreadPoolExecutor类的内部有三个方法,可以对线程池进行控制。这个三个方法默认的情况下什么都不做,方法体内容为空。
//任务执行前执行该方法 protected void beforeExecute(Thread t, Runnable r) { } //任务执行后执行该方法 protected void afterExecute(Runnable r, Throwable t) { } //线程池退出执行该方法 protected void terminated() { }
是不是和springmvc的登录拦截器很像,下面写了小例子演示一下:
import java.util.concurrent.ExecutorService; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; public class ExtThreadPool { static class Task implements Runnable{ private String name; public Task(String name) { this.name = name; } @Override public void run() { System.out.println("Thread ID:" + Thread.currentThread().getId() + " " + name + ":正在执行!"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { ExecutorService pool = new ThreadPoolExecutor(3, 3, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>()) { //任务执行之前调用 @Override protected void beforeExecute(Thread t, Runnable r) { Task task = (Task)r; System.out.println(task.name + ":开始执行!" ); } //任务执行之后调用 @Override protected void afterExecute(Runnable r, Throwable t) { Task task = (Task)r; System.out.println(task.name + ":执行结束!" ); } //线程池关闭后调用 @Override protected void terminated() { System.out.println("线程池已关闭!"); } }; for(int i = 0; i < 3; i++) { Task t = new Task("TASK-" + (i + 1)); pool.execute(t); } pool.shutdown(); } } 输出: TASK-2:开始执行! TASK-3:开始执行! TASK-1:开始执行! Thread ID:10 TASK-1:正在执行! Thread ID:11 TASK-2:正在执行! Thread ID:12 TASK-3:正在执行! TASK-3:执行结束! TASK-1:执行结束! TASK-2:执行结束! 线程池已关闭!
参考:《Java高并发程序设计》----葛一鸣,郭超

 浙公网安备 33010602011771号
浙公网安备 33010602011771号