21/7/11 读书笔记 smcql: Secure Querying for Federated Databases
SMCSQL:一种用于安全查询的联合数据库
ps:这篇目前还读得不透彻
摘要
在数据信息异常发达的当下,许多需要涉及数据的应用被公众关于隐私安全和安全监管的担忧阻碍。本文中定义了两个主要概念,其一是Private Data Network,PDN,描述一个用于在多方互不信任的参与者之间的联合数据库(Federated Database);其二是Secure multiparty computation,SMC,描述了多方安全计算协议。
PDN中,在所有数据库参与者均不泄露各自私有信息的情况下,用户将查询请求发送给一个诚实(honest)的代理者,然后该代理者根据请求内容,依靠SMC来协调各个数据库参与者实现请求内容,最终将请求结果返回给用户。
本文中介绍了一种用于执行PDE查询的框架——SMCQL。该系统能够将SQL语句翻译成SMC原语,从而完成安全多方计算。同时,本文还提出了一种启发式的优化方法,用于降低PDN对于SMC的使用(因为SMC通常会耗用大量的计算资源)。
1.介绍
进一步详细介绍了Federated database system。
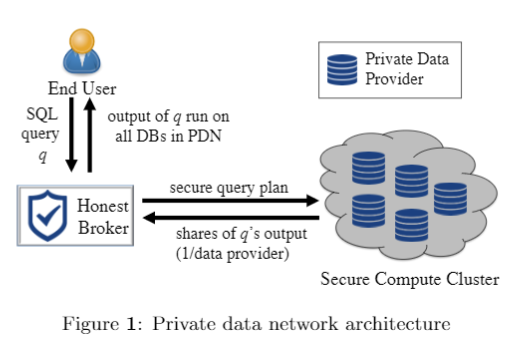
所有参与者都根据诚实代理(Honest Broker)提供的安全协议进行计算,并由诚实代理将多个data share进行整合,从而提供给用户完整的请求结果。在系统建立时,整个PDN会对表的内容进行统一定义,并且为不同的属性设定不同的安全级别,诚实代理会和所有参与者一起在安全的前提下完成这个表的链接。
SMC计算通常来说会比明文计算花费很多数量级倍数的时间,因此需要尽可能减少SMC运算在整个处理过程中的占比。诚实代理会提前通过模拟追踪敏感数据在语法树种的流动来计划好何时应该使用SMC运算,之后利用启发性的方法来进行优化,最后,代理会给出一系列操作来描述这个优化后的计划。
本文在这里提到了SMCQL是面向semi-honest场景的,即保证参与者都遵守相关协议,仅仅试图不经意获取到其他参与者的私有信息。
本文通过一种rule-based的方式保护敏感数据,所有参与者都会定义其所允许执行的请求类型。文章假设使用常识性规则和额外的激励能够实现大规模的数据共享。不同于采用同态加密的outsourced computation的先前工作,PDN是将数据保留给其持有者,利用SMC来隐藏具体的计算过程而不是隐藏具体的数据。PDN将安全计算分摊给所有参与者,并只采用一个轻量级的诚实代理来协调请求处理过程。
本文还提出了将SQL转换成SMC原语的方式,这种设想能够让编程人员无需自己去考虑具体的安全协议,只需要提供描述业务逻辑的SQL语句,本文提出的方法就能自动将其翻译成SMC原语从而实现功能。
本文的主要贡献:
- 一种新的联合数据库生成方式(指PDN架构)
- 一个将SQL翻译成SMC原语的代码生成器
- 一个用于PDN请求执行的启发式优化方法
- 对该系统在现实医疗数据上效果的深入测试评估
2.背景
这一节主要介绍了SMC的方式,以及SMCQL在这一方面的考量
SMCQL主要采用混淆电路(garbled circuits)和ORAM(Oblivious RAM)来实现SMC运算,主要是因为这两者都比较成熟,优化比较好。SMCQL利用混淆电路来计算在多方数据上的操作,利用ORAM来保护数据在执行者间的传输(在每次读写时都打乱包含数据的tuple,从而使得数据的访问细节对于被访问者来说是未知的)。我们可以为每个数据库操作单独设计一个混淆电路,利用ORAM完成操作间的数据传递,从而避免了设计一个复杂的臃肿的大型混淆电路来执行一系列的操作。
3.系统概览
本节描述了SMCQL的工作流程。对于一个诚实代理,其工作过程可以用下图来描述:
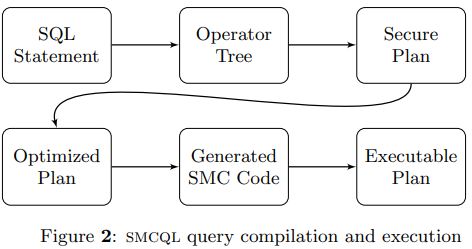
- 诚实代理接收到客户发来的一条SQL语句,该语句是违反PDN分享原则的
- 诚实代理将这条语句解析成一个有向无环图,其描述了各个参与者通过join和aggregate等操作来实现请求的过程,被视为一棵语法树。
- 诚实代理随后检查这个树,以保证其满足PDN的协议要求
- 通过识别出这棵树的满足PDN要求的最小子树,来产出一个secure plan。这一步通过让诚实代理由下至上遍历整棵树并对敏感数据建模实现。
- 将这棵树通过启发式的方法优化成多个小的SMC单元,并对SMC数量进行优化
- 诚实代理通过优化后的plan生成一系列的SMC代码用于协调各个参与者完成请求
- 每个参与者各自按照其自身的协议执行SQL请求,并在诚实代理提供的SMC代码下进行协作
当前该系统支持多种SQL操作,包括selection、projection、aggregation、limit、some window aggregates,对于join操作目前仅支持equi-join、theta-join、cross products。
4.安全请求的执行者
本节主要探讨如何在PDN中将计划转换成一系列可执行的安全的代码。
首先需要在计划中加入一些步骤用于将多方的数据tuple进行组合,随后针对每个操作单独生成代码。代码的主要结构是使用混淆电路进行多方计算,并将结果通过ORAM进行存储。被混淆了的计算结果在语法树中传递,直到根节点,然后每个参与者在根节点的share都会被发送给诚实代理,诚实代理总结后得出最终结果。
为了创建这种代码,本文使用了一种称为ObliVM的语言,这个语言先将代码转换成包含逻辑门和ORAM的集合,然后在执行阶段再生成混淆电路。这个语言与底层的混淆电路协议相互解耦,使得使用不同的协议时对于编程者可以无缝切换。
每个操作在转换成安全代码时,都需要一个对应的模板函数,这个模板函数接受过滤器谓词(filter predicates)、输入的大小作为输入,其为一种操作定义了安全代码的具体工作流程。模板和逻辑门、ORAM共同构成了PDN的低级表示,并在执行阶段编译出混淆电路。
本节最后指出SMC的计算开销通常会比明文计算高出3~4个数量级,并指出本文通过利用SQL语义优化SMC原语内部的具体执行过程,使得在优化对于SMC协议透明的情况下提升了性能。
5.建模
本节主要介绍了SMCQL面向用户提供的协议,其在属性层面对用户访问数据的权限和场景进行了限制。同时还介绍了SMCQL的安全类型系统,并指出该系统是如何帮助诚实代理对计划进行优化的。
面向用户的安全协议
协议的前提是一个用于描述数据表内各列属性对应的安全级别的信息集合,本文中设置了三个等级public、protected、private:
- public:完全共享可读
- protected:对于自身可见,并对用户和诚实代理条件可见。用k-anonymous描述一个protected属性的安全度,指该属性的一条记录至少和k-1个记录不可区分。在这种情况下,用户和诚实代理是可以通过协调多个参与者来获取这些数据的。
- private:对用户不可见,对自身可见
敏感数据的流动
对于优化请求,采取的第一个方法是在保持安全需求的前提下最小化所需的操作数量。
本节介绍了其定义的形式系统:


该系统中将所有的对象描述为phrase,每个phrase可以是一个expression、set、operator:
- expression:表示属性的引用、常量、算数与比较运算符、逻辑连接符
- set:表示expression的集合
- operator:以一个set为输入,输出一个set
该系统还定义了high和low两个安全级别,分别对应public和private类型(之后将protected视作private),一个expression是low的,当且仅当其中引用的所有属性都不是high的;一个set是low的,当且仅当其中所有的expression都是low的。


上图还描述了operator中的low和high的定义,不再赘述。其中R-NEST描述了一个操作的安全等级应当高于其子结点;R-NEST-BIN针对二元操作,如果一个子结点的安全等级为high,则该结点也为high。
本文基于这套形式系统来描述其operator-tree的结构,并从而通过安全等级的传递来描述敏感数据在树结构中的流动。
6.对于SMC的优化
在根据形式系统定义了operator-tree(文中用secure plan表示)后,本文将这个逻辑上的plan通过启发式的方法将整个大的计划分割成小的可变的实际计划。优化方案主要通过分割输入数据从而将evaluation过程分割为更多更小的计算单元。
优化方案定义了三种执行模式:
- Plain:operator是low的,其在源数据库中执行evaluation
- Sliced:high的operator在被一个被low的expression所水平分割的输入集合上执行
- Secure:high的operator在所有与输入数据有关的参与者中利用SMC程序执行
其中Sliced类型需要额外理解一下:每个Sliced的operator在接受明文输入后,需要利用slice key对输入进行二进制化加密。具有相同slice key的不同值被独立计算。
Slice的进一步详细理解:以一个联合查询为例,假如我同时查找Table1和Table2中id相同的数据并进行整合,那么这里的slice key指的就是不同的id值,而Slice就是指相同slice key的数据被一起进行混淆,形成混淆表。注意slice key一定要是public的属性,因为需要根据其信息进行slice。

可见Slice能够大幅减少数据的量级,而且slice key在可能的取值空间内越是均匀,则其效果越显著
其中系统通过以下的方式为操作赋予执行模式:

Slice是一个用于减少Secure模式的有效方法,进一步降低了SMC运算的占比。
更进一步,考虑某些特殊操作,比如COUNT(*)在涉及private attribute时,我们可将其分为两步,第一步在各个参与者中各自计算相应的数量,第二步利用SMC方法进行求和。可见第一步是low的,而第二步是high的,我们称这样的operator是splittable operator。每个splitable operator能够被分为两个安全等级不同的phrase,将其视作两个等级不同的子句而不是一个high的整体,能够进一步减小SMC开销。
再进一步,我们可以仅在涉及多方的情况下才使用SMC方法,称为semi-join。理由和上面的一样,我们可以将请求执行分为两个部分,在仅涉及自身一个参与者的情况下,可以采用明文计算而无需SMC方法;在涉及发送和传递数据时才使用SMC方法。
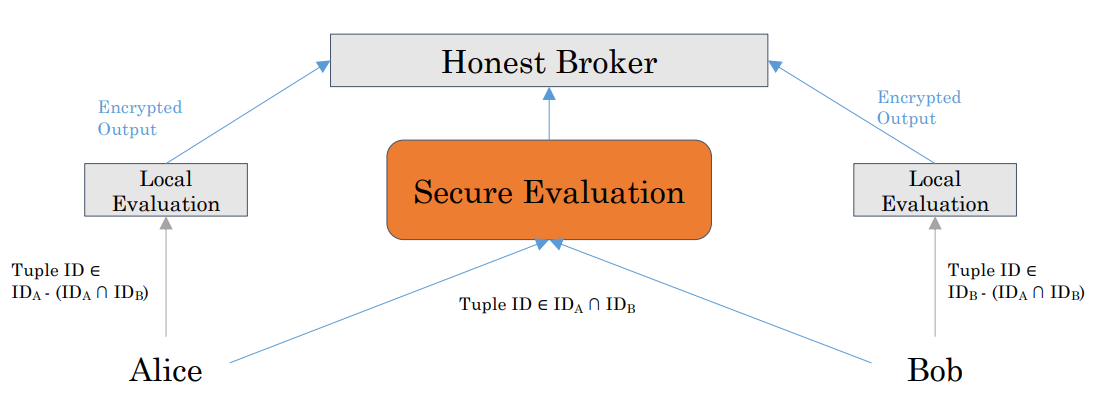
图中,我们将独属于Alice和Bob的数据各自在其本地进行了计算,只有对Alice和Bob都有的数据才进行SMC,这同样要求我们用于判断的属性(图中为Tuple ID)应该是public的。
7.测试
本节中测试了SMCQL架构的性能,主要包括启发式优化对于使用SMC带来的提升、测试了SMC在各种各样的operator上造成的影响、测试了SMCQL在面对不断增大的数据集时的可拓展性、和理想的Federated Database的性能对比。
首先定义三个workload作为测试的情景:
-
Comorbidity:
SELECT diag, COUNT(*) cnt FROM diagnoses WHERE patient_id IN cdiff_cohort GROUP BY diag ORDER BY cnt LIMIT 10; -
Recurrent C.Diff:
WITH rcd AS ( SELECT pid, time, row_no() OVER (PARTITION BY pid ORDER BY time) FROM diagnosis WHERE diag=cdiff) SELECT DISTINCT pid FROM rcd r1 JOIN rcd r2 ON r1.pid = r2.pid WHERE r2.time - r1.time >= 15 DAYS AND r2.time - r1.time <= 56 DAYS AND r2.row_no = r1.row_no + 1; -
Asipirin Count:
SELECT COUNT(DISTINCT pid) FROM diagnosis d JOIN medication m ON d.pid = m.pid WHERE d.diag = hd AND m.med = aspirin AND d.time <= m.time;
首先以对HealthLNK数据集的随机采样为输入,测试了三种不同条件下,SMCQL在三种情景中的性能表现:
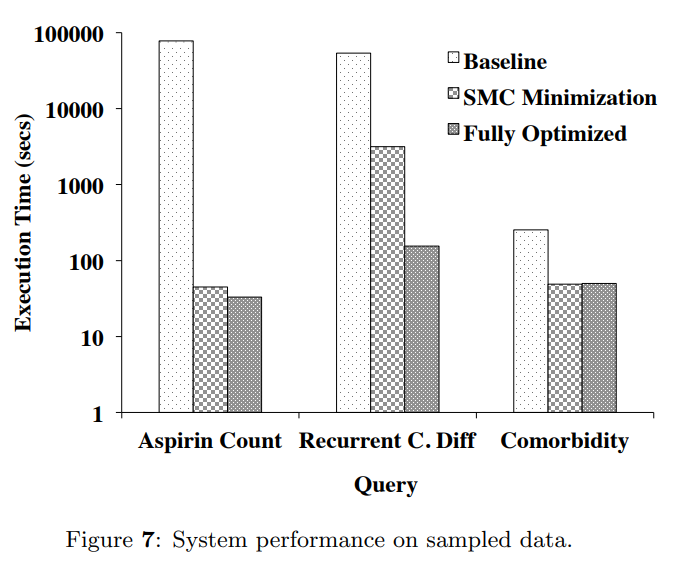
其中baseline对应所有属性都被视作private的,从而不进行任何优化;SMC Minimization对应通过分析high和low而减少了对于SMC的使用,包括splittable operators;Fully Optimized对应继续采用slice execution的方法进行优化。
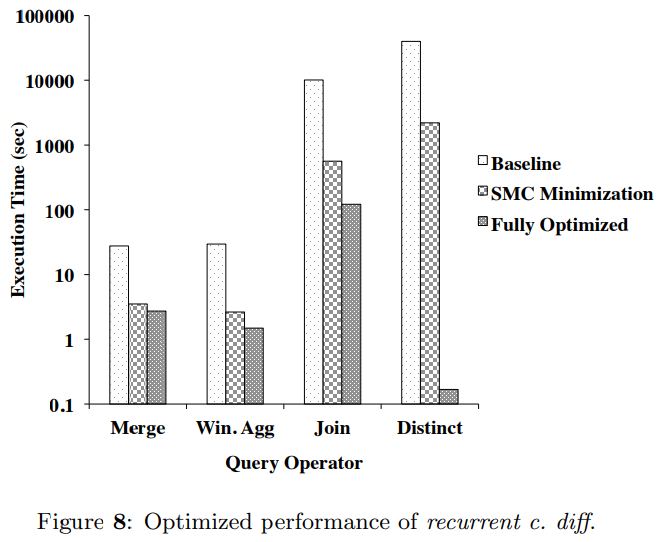
然后本文以recurrent c. diff场景为例,进一步测试了不同条件对于每个operator的性能影响:
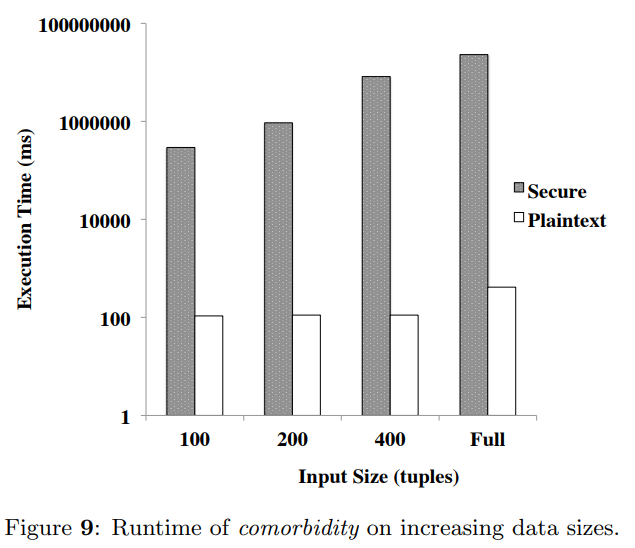
再然后本文在comorbidity情景下使用不同的输入大小,测试了Secure状态和明文状态下的性能差异。本文将Secure在Scale增大时的性能降低主要归结于不经意传输时需要传输和打乱的数据的规模增大。
随后,本文就Figure 7中的测试进一步扩大了数据集,使用全年的数据进行测试,指出Asipirin Count和*Recurrent C. diff *中性能的明显降低,与join操作的\(O(n^2)\)的oblivious evaluation有关:
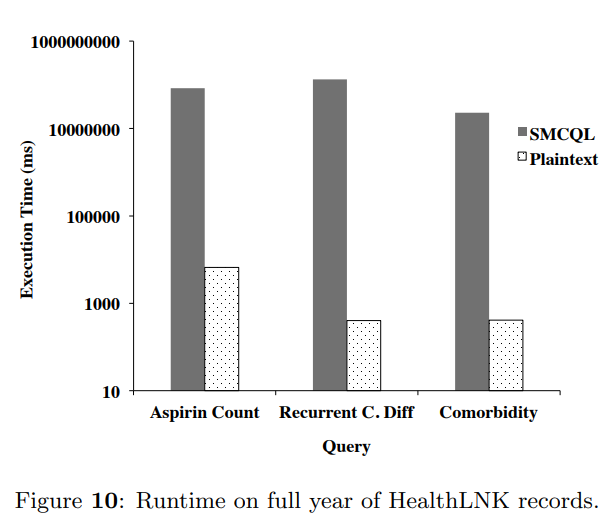
本文通过测试得出:
join操作是最为耗费计算资源的oblivious operator- Slicing方法在面对在slice key空间内被均匀划分的数据集时能够最有效地提高效率
- 面对数据集的扩大,执行时间大幅上升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号