.NET+SqlServer 实现数据读写分离
如今,我们操作数据库一般用ORM框架
现在用.NET Core + EFCore + SqlServer 实现数据读写分离
介绍
为什么要读写分离?
降低数据库服务器的压力
如何实现读写分离?
1.一个主库多个从库
2.配置主库复制数据到从库
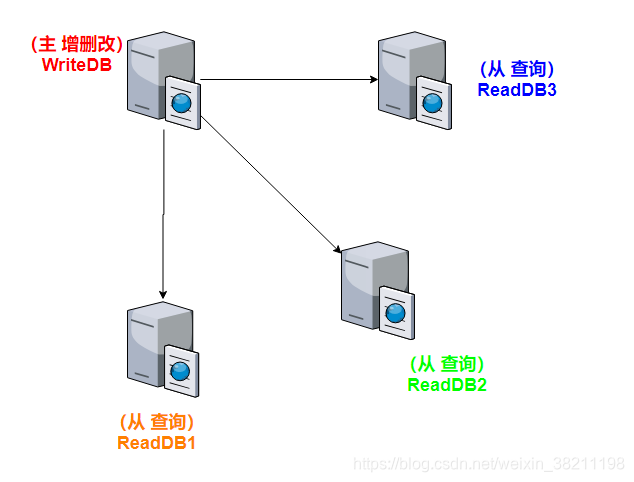
为什么一个主库多个从库?
一般查询多于增删改,这就是我们常说的二八原则,20%操作是增删改,80%操作是查询
是否有缺点?
有延迟
如何解决延迟问题?
比较及时性的数据还是通过主库查询
具体如何实现?
通过发布服务器,主库发布,而从库订阅,从而实现主从库
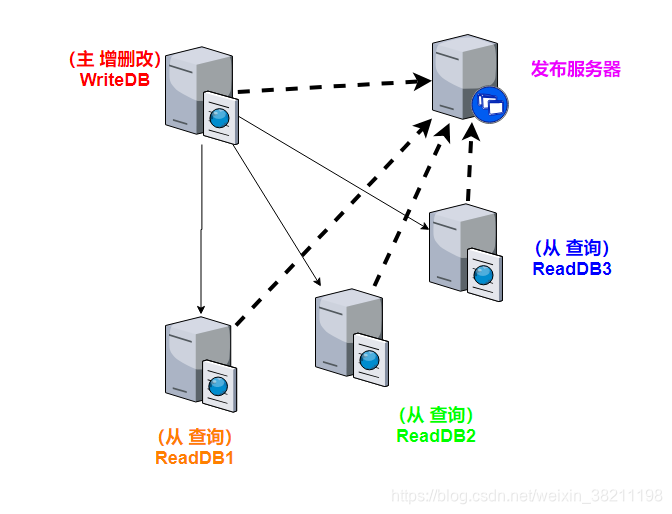
实现
SqlServer 实现
1.使用SqlServer 2019,新建一个主库,创建表,再通过本地发布创建发布,
然后通过本地订阅订阅主库,创建两个从库

2.配置AlwaysOn高可用性

https://www.cnblogs.com/chenmh/p/4484176.html
.NET Core MVC项目实现
项目结构

首先,在appsettings.json配置数据库连接字符串
{ "Logging": { "LogLevel": { "Default": "Information", "Microsoft": "Warning", "Microsoft.Hosting.Lifetime": "Information" } }, "AllowedHosts": "*", "ConnectionStrings": { "EFCoreTestToRead": "Server=GREAMBWANG-DC\\MSSQLSERVER2019;Database=EFCoreTestToRead01;Trusted_Connection=True;,Server=GREAMBWANG-DC\\MSSQLSERVER2019;Database=EFCoreTestToRead02;Trusted_Connection=True;", "EFCoreTestToWrite": "Server=GREAMBWANG-DC\\MSSQLSERVER2019;Database=EFCoreTest;Trusted_Connection=True;" } }
Models层实现
创建模型
public class UserInfo { [Key] public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } }
创建上下文
public class EFCoreContext : DbContext { public EFCoreContext(string connectionString) { ConnectionString = connectionString; //创建数据库 //Database.EnsureCreated(); } private string ConnectionString { get; } public DbSet<UserInfo> UserInfo { get; set; } /// <summary> /// 配置连接数据库 /// </summary> /// <param name="optionsBuilder"></param> protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) { //base.OnConfiguring(optionsBuilder); optionsBuilder.UseSqlServer(ConnectionString); } protected override void OnModelCreating(ModelBuilder modelBuilder) { //base.OnModelCreating(modelBuilder); //初始化数据 modelBuilder.Entity<UserInfo>().HasData(new List<UserInfo>() { new UserInfo() { Id = 1, Name = "哈哈", Age = 17 }, new UserInfo() { Id = 2, Name = "呵呵", Age = 18 }, new UserInfo() { Id = 3, Name = "嘻嘻", Age = 19 } }); } }
创建上下文工厂
读写枚举
public enum WriteAndReadEnum { Write, Read }
接口
public interface IDbContextFactory { EFCoreContext CreateContext(WriteAndReadEnum writeAndRead); }
实现
在实现数据查询上,可以使用不同的策略,一般有随机策略,权重策略,轮询策略
随机策略:随机选择一个从库进行查询
权重策略:根据权重比例选择从库查询
轮询策略:根据顺序选择从库查询
Models层完成
public class DbContextFactory : IDbContextFactory { private IConfiguration Configuration { get; } private string[] ReadConnectionStrings; public DbContextFactory(IConfiguration configuration) { Configuration = configuration; ReadConnectionStrings = Configuration.GetConnectionString("EFCoreTestToRead").Split(","); } public EFCoreContext CreateContext(WriteAndReadEnum writeAndRead) { string connectionString = string.Empty; switch (writeAndRead) { case WriteAndReadEnum.Write: connectionString = Configuration.GetConnectionString("EFCoreTestToWrite"); break; case WriteAndReadEnum.Read: connectionString = GetReadConnectionString(); break; default: break; } return new EFCoreContext(connectionString); } private string GetReadConnectionString() { /* * 随机策略 * 权重策略 * 轮询策略 */ //随机策略 string connectionString = ReadConnectionStrings[new Random().Next(0, ReadConnectionStrings.Length)]; return connectionString; } }
在Web层中
在Startup的ConfigureServices方法添加依赖注入
services.AddScoped<IDbContextFactory, DbContextFactory>();
操作
public class HomeController : Controller { private readonly ILogger<HomeController> _logger; public IDbContextFactory DbContextFactory { get; } public HomeController(ILogger<HomeController> logger,IDbContextFactory dbContextFactory) { _logger = logger; DbContextFactory = dbContextFactory; } public IActionResult Index() { //写入操作 EFCoreContext writeContext = DbContextFactory.CreateContext(WriteAndReadEnum.Write); writeContext.UserInfo.Add(new UserInfo() { Name = "AA", Age = 20 }); writeContext.SaveChanges(); //查询操作 EFCoreContext readContext = DbContextFactory.CreateContext(WriteAndReadEnum.Read); UserInfo userInfo = readContext.UserInfo.OrderByDescending(u => u.Id).FirstOrDefault(); return View(); } }
总结
sqlserver读写分离后,读库和主库会有一定时间的延迟,当业务逻辑是增加记录后马上刷新列表之类的逻辑时
alwayson ?
其实这个延迟一般情况下不会太大, 一般几十ms 到 几百 ms. 也可以在增加记录之后 Thread.Sleep(1000) 休眠一秒, 然后再刷新列表, 问题不大的。
特别重要的(关系到钱)的业务, 就只能直接读主库了。
要是不容许有不一致性,那你就别分离了。
但是也可以 业务逻辑是增加记录后马上刷新列表之类的逻辑时-->新增成功之后将数据添加到本地集合(BindingList/ObservableCollection)这样能将结果通知到UI列表显示,而不是再从新读取全部数据。
实际上读写分离相当程度上是增加了问题、增加了困难,而不是减少了问题。真正应该首先做到的是,尽量在逻辑中避免使用事务概念、甚至避免使用关系数据库,尽量将面向数据库增删改查的程序改为面向(几百万)微服务的并发程序。然而很多人没有这方面的理解,认为把数据库分库分表读写分离这类“优化”最简单,所以一味地浪费精力在看似最简单实则已经逐步脱离时代的优化概念上。
分离数据库不是什么好主意,甚至可以说是“坑爹”的。现在的大规模高性能的程序,实际上是去掉增删改查数据库层概念,而是面向全局一致性分布式数据缓存层来编程。
高性能系统是去低级的数据库层,而是使用中间件层,也就是在后台业务逻辑处理中也要至少三层设计。
具备维护功能的代码本身应该是读写在写的数据库上,而不是写在写数据库,而读在读数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号