C# 高并发、抢单解决思路
高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时 间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统 的并发用户数。
高并发一直是网站上线后会遇到的一个严峻的考验,渡过了一切都好,渡不过就是宕机。
在电商时代如此发达的今天,高并发无此不在双十一 、618、双十二,还有雷猴王的某米手机抢购。首先我们要分析高并发究竟会给我们开发者带来什么样的挑战
大量的请求,如果仅仅只有一台服务器肯定是吃不消的,通常一些公司都是一台服务器上部署了很多个网站也充当了数据库服务器、redis服务器。如果要应用高并发没有足够的硬件支持是不行的。我们需要进行 分布式集群 以及 负载均衡
硬件支持有了过后,我们就需要下一步的分析
这时我们还需要提高网站的吞吐量,怎么提高呢?首先我们需要针对IO密集型做异步化操作,抢单的页面不只是有抢单按钮,还有商品的介绍,图片,文字描述等。对于这些数据我们要进行缓存,一万个用户一万次请求都从数据库中取数据与只取一次剩下9999次从缓存中取效率自然是不一样的
上面说的都是为了解决一个 高 字,而并发才是我们真正需要准备的,假如两个用户同时请求,这时库存还有1,程序里先判断库存是不是1,现在都符合条件,然后进行生成订单等操作。就发生了资源共享的问题,明明只有一个订单,但是两个用户都完成了订单,那么这个商品应该给谁呢?
并发
假设现在是一个电商网站,今天要举办活动,有10个商品低价销售,但是会来抢购的人会特别多,最后只有十个人可以成功的买到商品
假设的逻辑,我们用户进行了请求,我们把他们的信息放到库里,但是只有前十个人是可以购买商品的,因为库存只有10个
也许我们可以用锁来解决并发的问题,但是锁无疑带来的是效率的低下,用户体验也极低。我们想要的是快速返回,但是后面那一堆的逻辑怎么办呢?我们可以使用RabbitMq队列,用户的请求到达了抢单接口,我们只向队列中丢一条数据后就立即返回
这时又来了一个问题,会有同一个用户多次进行请求的情况,如果像之前的逻辑,前10条信息有二条是属于一个人的呢,(这里假设每个人只可以购买一次)我们就需要进行判断了,同一个账户发送的多次请求,我们只认为第一次请求是有效的,剩下的都请都直接返回。因为是并发,我们又怎么做到第一次请求有效呢?这时我们可以使用Redis incr存储用户的标识,Redis是单线程的,不存在并发的问题。incr返回为1那么是第一次请求,为N则是第N请求那么它就是无效的。这是请求标识
请求标识我们可以在抢单接口就进行判断,也就是先拿用户的标识去Incr,返回为1则丢到队列,不为1则不丢到队列。
也可以在rabbitmq的消费端进行处理,从rabbitmq消息队列中拿到用户信息后,进行incr。再进行下一步操作
丢到了消息队列中,我们还需要去处理,consumer我们肯定是要有多个的,我们可以使用平分分发与手动交付。在这里我们把用户的信息进行入库,当然入库后我们再向Redis中存入一条入库标识
上面都是在后端,客户端这里点击了抢单按钮后可以立即导向排队界面(是不是很熟悉,某米。。。)在这个界面进行轮询五秒一次,判断当前用户在库中的位置,如果是前十,那么就进行订单操作,不是。。。那就再等,看看会不会有其他用户放弃购买资格。
也可以使用Memcache锁
product_lock_key 为票锁key
当product_key存在于memcached中时,所有用户都可以进入下单流程。
当进入支付流程时,首先往memcached存放add(product_lock_key, “1″),如果返回成功,进入支付流程。如果不成,则说明已经有人进入支付流程,则线程等待N秒,递归执行add操作。
测试方法:
本地模拟测试网站高访问高并发采用的测试工具是大名鼎鼎的Loadrunner,这个工具做测试的一般都知道。
秒杀解决
页面静态化(CDN)、限流、引入Redis
1、在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成性能问题的
必须使用缓存,将需要秒杀的商品放入缓存中,并使用锁来处理其并发情况。当接到用户秒杀提交订单的情况下,先将商品数量递减(加锁/解锁)后再进行其他方面的处理,处理失败在将数据递增1(加锁/解锁),否则表示交易成功。
当商品数量递减到0时,表示商品秒杀完毕,拒绝其他用户的请求。
2、这个肯定不能直接操作数据库的,会挂的。直接读库写库对数据库压力太大,要用缓存。
把你要卖出的商品比如10个商品放到缓存中;然后在memcache里设置一个计数器来记录请求数,这个请求书你可以以你要秒杀卖出的商品数为基数,比如你想卖出10个商品,只允许100个请求进来。那当计数器达到100的时候,后面进来的就显示秒杀结束,这样可以减轻你的服务器的压力。然后根据这100个请求,先付款的先得后付款的提示商品以秒杀完。
3、首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。
这个直接可以使用加锁机制去解决,乐观锁或者悲观锁。
乐观锁,就是在数据库设计一个版本号的字段,每次修改都使其+1,这样在提交时比对提交前的版本号就知道是不是并发提交了,但是有个缺点就是只能是应用中控制,如果有跨应用修改同一条数据乐观锁就没办法了,这个时候可以考虑悲观锁。
悲观锁,就是直接在数据库层面将数据锁死,类似于oralce中使用select xxxxx from xxxx where xx=xx for update,这样其他线程将无法提交数据。
除了加锁的方式也可以使用接收锁定的方式,思路是在数据库中设计一个状态标识位,用户在对数据进行修改前,将状态标识位标识为正在编辑的状态,这样其他用户要编辑此条记录时系统将发现有其他用户正在编辑,则拒绝其编辑的请求,类似于你在操作系统中某文件正在执行,然后你要修改该文件时,系统会提醒你该文件不可编辑或删除。
4、不建议在数据库层面加锁,建议通过服务端的内存锁(锁主键)。当某个用户要修改某个id的数据时,把要修改的id存入memcache,若其他用户触发修改此id的数据时,读到memcache有这个id的值时,就阻止那个用户修改。
5、实际应用中,并不是让mysql去直面大并发读写,会借助“外力”,比如缓存、利用主从库实现读写分离、分表、使用队列写入等方法来降低并发读写。
6.随机抛弃请求 看运气了 redis的set 有个方法srandmember
实际上硬件才是根本
负载均衡 :多台服务器
读写分离:数据库作为数据持久化工具,必定在并发访问频繁且负载压力较大的情况下成为系统性能的‘瓶颈’。即使使用上面的本地缓存等方式来解决频繁访问数据库的问题,但仍旧会有大量的并发请求要访问动态数据, 其中的‘读写分离’方案就是一种被广泛采用的方案
数据库锁的介绍(一般不建议用)
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。 通过 jdbc 实现时 sql 语句只要在整个语句之后加 for update 即可。例如: select …for update
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适
共享锁:(读取)操作创建的锁。其他用户可以并发读取数据,但任何事物都不能获取数据上的排它锁,直到已释放所有共享锁。
共享锁(S锁)又称为读锁,若事务T对数据对象A加上S锁,则事务T只能读A;其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排它锁:排它锁又称为写锁((eXclusive lock,简记为X锁)),若事物T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。它防止任何其它事务获取资源上的锁,直到在事务的末尾将资源上的原始锁释放为止。
互斥锁是一个互斥的同步对象,意味着同一时间有且仅有一个线程可以获取它。
互斥锁可适用于一个共享资源每次只能被一个线程访问的情况
小结:
悲观锁:查询加锁 【select ...... for update】
乐观锁:修改加锁 【版本号控制】
排它锁:事务A可以查询、修改,直到事务A释放为止才可以执行下一个事务
共享锁:事务A可以查询、修改,同时事务B也可以查询但不能修改
互斥锁:同一资源同一时间只能被一个线程访问
大量用户访问解决
大型网站,比如门户网站,在面对大量用户访问、高并发请求方面带来的问题
1大并发:在同一个时间点,有大量的客户来访问我们的网站,如果访问量过大,就可能造成网站瘫痪。
2大流量:当网站大后,有大量的图片,视频, 这样就会对流量要求高,需要更多更大的带宽。
3大存储:你的数据量会成海量的数据,如果我们的数据放入一张表,是无法应对的。可能对数据保存和查询出现问题。
基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器,(对架构分层+负载均衡+集群)这几个解决思路在一定程度上意味着更大的投入。
解决方案:
一、提高硬件能力、增加系统服务器。(当服务器增加到某个程度的时候系统所能提供的并发访问量几乎不变,所以不能根本解决问题)
二、使用缓存(本地缓存:本地可以使用JDK自带的 Map、Guava Cache.分布式缓存:Redis、Memcache.本地缓存不适用于提高系统并发量,一般是用处用在程序中。比如Spring是如何实现单例的呢?大家如果看过源码的话,应该知道,Spiring把已经初始过的变量放在一个Map中,下次再要使用这个变量的时候,先判断Map中有没有,这也就是系统中常见的单例模式的实现。
分布式缓存利器Redis集群,Redis集群的搭建至少需要三主三从。 1. 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。 2. 节点的fail是通过集群中超过半数的节点检测失效时才生效(所以一个集群中至少要有三个节点)。 3. 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。 4. 集群中每一个节点都存放不同的内容,每一个节点都应有备份机。 5. redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了16384 个哈希槽,当需要在Redis 集群中放置一个key-value 时,redis先对 key 使用 crc16 算法算出一个结果,然后把结果对16384 求余数,这样每个key 都会对应一个编号在0-16383 之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点。
三 、消息队列 (解耦+削峰+异步)通过异步处理提高系统性能,降低系统耦合性
在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。
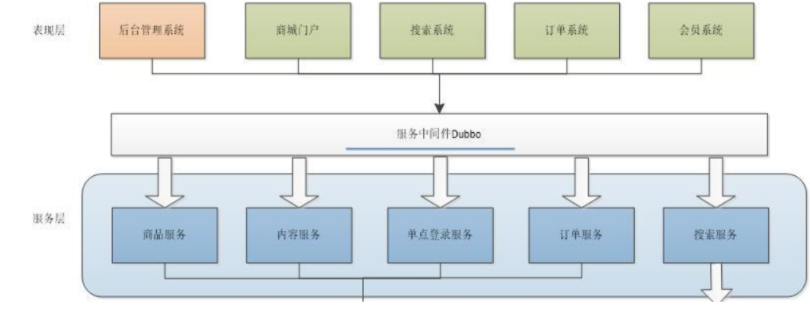
通过使用消息中间件对Dubbo服务间的调用进行解耦, 消息中间件可利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,可以在分布式环境下扩展进程间的通信。通过消息中间件,应用程序或组件之间可以进行可靠的异步通讯,从而降低系统之间的耦合度,提高系统的可扩展性和可用性。
四 、采用分布式开发 (不同的服务部署在不同的机器节点上,并且一个服务也可以部署在多台机器上,然后利用 Nginx 负载均衡访问。这样就解决了单点部署(All In)的缺点,大大提高的系统并发量)
五 、数据库分库(读写分离)、分表(水平分表、垂直分表)
PXC高可用集群与Replication集群结合方案
这种的集群在遇到单表数据量超过2000万的时候,mysql性能会受损,所以一个集群还不够,我们需要把数据分到另一个集群,这个称为“切片”,就是把大量的数据拆分到不同的集群中,每个集群的数据都是不一样的,通过MyCat这个阿里巴巴的开源中间件,可以把sql分到不同的集群里面去。
六、 采用集群 (多台机器提供相同的服务)系统架构方案
七、CDN 加速 (将一些静态资源比如图片、视频等等缓存到离用户最近的网络节点)
八、浏览器缓存 页面静态化(使用php自己的ob缓存技术实现, 主流的mvc框架(tp,yii,laravel)模板引擎一般都自带页面静态化 )
九、使用合适的连接池(数据库连接池、线程池等等)
十、适当使用多线程进行开发。
十一、使用镜像
镜像是大型网站常采用的提高性能和数据安全性的方式,镜像的技术可以解决不同网络接入商和地域带来的用户访问速度差异,比如ChinaNet和EduNet之间的差异就促使了很多网站在教育网内搭建镜像站点,数据进行定时更新或者实时更新。有很多专业的现成的解决架构和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
十二、图片服务器分离
大家知道,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他们都有独立的、甚至很多台的图片服务器。这样的架构可以降低提供页面访问请求的服务器系统压力,并且可以保证系统不会因为图片问题而崩溃。
在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时候可以尽量少支持、尽可能少的LoadModule,保证更高的系统消耗和执行效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号