

MSSQL删除重复数据
DECLARE @table TABLE(gd varchar(100), [time] datetime)
INSERT INTO @table
SELECT 'gd550765', '2009-08-14 16:02:07.293'
UNION ALL SELECT 'gd550765', '2009-08-14 16:19:41.000'
UNION ALL SELECT 'gd550765', '2009-08-14 16:06:01.530'
UNION ALL SELECT 'gd75', '2009-08-14 16:31:06.810'
UNION ALL SELECT 'gd75', '2009-08-14 16:31:12.483'
UNION ALL SELECT 'gd77', '2009-08-14 16:32:20.310'
UNION ALL SELECT 'gd77', '2009-08-14 16:32:37.640'
SELECT * FROM @table
取数据(去掉重复数据),好一点的办法:
SELECT * FROM @table a
WHERE NOT EXISTS(SELECT 1 FROM @table WHERE gd=a.gd AND [time]>a.[time])
烂一点的办法:
SELECT gd, max([time]) FROM @table a GROUP BY gd
删除表中重复记录
http://www.cnblogs.com/LazyBee/archive/2008/06/05/1214102.html
删除表中重复记录
最近由于要给旧系统的表中增加主键(SQL Server2000的表),由于旧表中存在重复记录所以导致增加不上,所以需要写一段SQL语句来删除所有的重复记录(就是必须保留重复记录中的一条,维持数据记录的唯一性),我知道园子里大虾多,所以在这里集思广益,看看大家都有什么好的办法:
方法一:
1 为了保证完整性,首先启动一个事务
2 声明一个表变量(在这里使用表变量主要是考虑重复的数据不是很多,同时为了获得更好的性能;当然如果重复的数据特别多,使用临时表是更
好的选择,因为表变量的数据都是存在内存中的,如果数据量大,可能导致内存吃紧。)用于存储重复性的数据,这个需要定义成和源表一样。
3 将重复记录的一条插入到表变量中。
4 删除所有有重复记录的记录
5 将表变量中的记录插入的源表中。
6 如果出错,回滚事务,否则提交事务
以下是相应的sql语句块:
 Begin Tran LazyBee
Begin Tran LazyBee2
declare @tmp Table3
(lLIstHeader_id int,lEncounter_id int,dtLastUpdate_dt datetime,4
sLastUpdate_id char(10),iConcurrency_id int)5
6
Insert @tmp(lLIstHeader_id,lEncounter_id,dtLastUpdate_dt,sLastUpdate_id,iConcurrency_id)7
select lListHeader_id,lEncounter_id,dtLastUpdate_dt,sLastUpdate_id,iConcurrency_id 8
from lstHeaderencounter9
group by lListHeader_id,lEncounter_id,dtLastUpdate_dt,sLastUpdate_id,iConcurrency_id 10
having count(*)>1 11
12
delete lstHeaderencounter from @tmp d 13
where d.lListHeader_id=lstHeaderencounter.lListHeader_id and 14
d.lEncounter_id=lstHeaderencounter.lEncounter_id15
16
insert lstHeaderencounter(lLIstHeader_id,lEncounter_id,dtLastUpdate_dt,sLastUpdate_id,iConcurrency_id)17
select lListHeader_id,lEncounter_id,dtLastUpdate_dt,sLastUpdate_id,iConcurrency_id 18
from @tmp19
20
if @@error<>021
Begin22
print 'roll back'23
RollBack Tran LazyBee24
End25
else26
Begin27
print 'Success'28
Commit Tran LazyBee29
End30
我知道这个方法不够通用,因为如果有多个类似重复记录的表存在,将每次都要修改表定义和插入语句的字段内容,不知各位有没有好的方法或意见,大家讨论讨论:)
刚在网上找到另外一些解决方案,感觉也挺不错的
方法二:
1 创建一个临时表,这个临时表的结构和源表一样
2 给这个临时表增加一个唯一索引(根据需要),并且选中忽略重复值
3 将源表的记录全部插入临时表中,这时会因为重复记录出现3604的错误。
4 删除源表的记录,将临时表的记录插入源表中,然后删除临时表。
方法三(主要针对重复记录完全相同的情况):
1 利用distinct将唯一记录插入临时表中
2 然后将唯一记录再倒回源表中
Select distinct * into #Tmp from tableNameDrop table tableNameSelect * into tableName from #TmpDrop table #Tmp
方法四(主要针对记录部分字段相同的记录):
这种方法和方法一有点类似,不过实现方法不同而已。在这里使用了两个临时表.我们假设重复字段为lListHeader_id,lEncounter_id,要求得到这两
个字段的唯一结果集,我们保留重复记录的第一条,当然如果保留重复记录的最后一条可以使用max代替min:
Select identity(int,1,1) as autoID, * into #Tmp from tableNameSelect min(autoID) as autoID into #Tmp2 from #Tmp group by lListHeader_id,lEncounter_idSelect * from #Tmp where autoID in (Select autoID from #Tmp2)
方法五(也是针对部分字段相同的记录)
纯SQL直接删除:
Delete lstStructureItems from 2
(select lStructure_id,lListHeader_id,lList_id,max(lParent_id) as lParent_id,max(lOrder_num) as lOrder_num,lDoctor_id 3
from lstStructureItems 4
group by lStructure_id,lListHeader_id,lList_id,lDoctor_id5
having count(*)>1) d 6
where7
lstStructureItems.lStructure_id=d.lStructure_id and8
lstStructureItems.lListHeader_id=d.lListHeader_id and9
lstStructureItems.lList_id=d.lList_id and10
lstStructureItems.lDoctor_id=d.lDoctor_id and11
(lstStructureItems.lParent_id<>d.lParent_id or12
lstStructureItems.lOrder_num<>d.lOrder_num)13
在这里我们为了给lStructure_id,lListHeader_id,lList_id,lDoctor_id四个字段增加一个唯一索引,所以需要只保留这四个字段保持唯一的值,其他的都需要删除。所以我们采用将这四个字段进行group by,然后保留lParent_id和lOrder_num最大值的记录(注:这里假设表中不存在两条完全相同的记录,如果存在的话只能通过前面的方法来进行删除)。
常见问题解答--Sql删除重复数据
http://www.cnblogs.com/Richet/archive/2008/07/28/1254764.html
sql学习过程中,碰到了删除冗余数据的问题。经过搜索,查找,终于解决了此问题
第一种,数据全部重复,如下图:
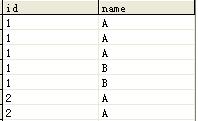
需要得到以下的结果:

删除重复的记录(重复记录保留1条),可以按以下方法删除
seleet distinct * into #Tmp from TableName
drop table TableName
select * into TableName from #Tmp
drop table #Tmp
第二种,数据部分字段重复,ID不重复 ,如下图:
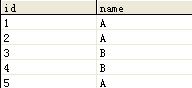
需要得到以下结果:
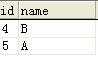
下面的语句可以达到要求:
delete 表 where id not in(
SELECT MAX(id) AS id FROM 表 GROUP BY rows) --- 删除重复行
select * from 表 where id in(
SELECT MAX(id) AS id FROM 表 GROUP BY rows) --重复行只查询一条
注:如有错误,多多指教!
http://topic.csdn.net/u/20090206/17/d76373fa-045d-4c95-a044-747802f5c36e.html
id name
1 aa
1 aa
2 bb
3 bb
4 cc
1 aa
4 cc
id和nam都是普通的字段而已
请问大虾们:如何用一条SQL语句来删除重复值,比如不用临时表什么的等
结果
id name
1 aa
2 bb
3 bb
4 cc
删除:可以借用临时表
查询:select distinct * from tb
select *
from
(select id,Row_number()over(partition by id,name order by id) as cnt
from table) As A
where cnt =1 //没试用
//先这样,有空网站搜索一下,整理一下,验证一下,包括查询(去重复数据),删除重复数据。
作者:Net205
出处:http://net205.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

