
在java中使用dom4j解析xml
虽然Java中已经有了Dom和Sax这两种标准解析方式
但其操作起来并不轻松,对于我这么一个初学者来说,其中部分代码是活生生的恶心
为此,伟大的第三方开发组开发出了Jdom和Dom4j等工具
鉴于目前的趋势,我们这里来讲讲Dom4j的基本用法,不涉及递归等复杂操作
Dom4j的用法很多,官网上的示例有那么点儿晦涩,这里就不写了
首先我们需要出创建一个xml文档,然后才能对其解析
xml文档:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="001"> <title>Harry Potter</title> <author>J K. Rowling</author> </book> <book id="002"> <title>Learning XML</title> <author>Erik T. Ray</author> </book> </books> |
示例一:用List列表的方式来解析xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | import java.io.File;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class Demo { public static void main(String[] args) throws Exception { SAXReader reader = new SAXReader(); File file = new File("books.xml"); Document document = reader.read(file); Element root = document.getRootElement(); List<Element> childElements = root.elements(); for (Element child : childElements) { //未知属性名情况下 /*List<Attribute> attributeList = child.attributes(); for (Attribute attr : attributeList) { System.out.println(attr.getName() + ": " + attr.getValue()); }*/ //已知属性名情况下 System.out.println("id: " + child.attributeValue("id")); //未知子元素名情况下 /*List<Element> elementList = child.elements(); for (Element ele : elementList) { System.out.println(ele.getName() + ": " + ele.getText()); } System.out.println();*/ //已知子元素名的情况下 System.out.println("title" + child.elementText("title")); System.out.println("author" + child.elementText("author")); //这行是为了格式化美观而存在 System.out.println(); } }} |
示例二:使用Iterator迭代器的方式来解析xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | import java.io.File;import java.util.Iterator;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class Demo { public static void main(String[] args) throws Exception { SAXReader reader = new SAXReader(); Document document = reader.read(new File("books.xml")); Element root = document.getRootElement(); Iterator it = root.elementIterator(); while (it.hasNext()) { Element element = (Element) it.next(); //未知属性名称情况下 /*Iterator attrIt = element.attributeIterator(); while (attrIt.hasNext()) { Attribute a = (Attribute) attrIt.next(); System.out.println(a.getValue()); }*/ //已知属性名称情况下 System.out.println("id: " + element.attributeValue("id")); //未知元素名情况下 /*Iterator eleIt = element.elementIterator(); while (eleIt.hasNext()) { Element e = (Element) eleIt.next(); System.out.println(e.getName() + ": " + e.getText()); } System.out.println();*/ //已知元素名情况下 System.out.println("title: " + element.elementText("title")); System.out.println("author: " + element.elementText("author")); System.out.println(); } }} |
运行结果:
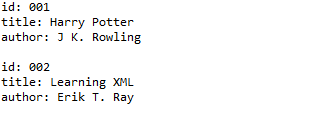
示例三:创建xml文档并输出到文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | import java.io.File;import java.io.FileOutputStream;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.OutputFormat;import org.dom4j.io.XMLWriter;public class Demo { public static void main(String[] args) throws Exception { Document doc = DocumentHelper.createDocument(); //增加根节点 Element books = doc.addElement("books"); //增加子元素 Element book1 = books.addElement("book"); Element title1 = book1.addElement("title"); Element author1 = book1.addElement("author"); Element book2 = books.addElement("book"); Element title2 = book2.addElement("title"); Element author2 = book2.addElement("author"); //为子节点添加属性 book1.addAttribute("id", "001"); //为元素添加内容 title1.setText("Harry Potter"); author1.setText("J K. Rowling"); book2.addAttribute("id", "002"); title2.setText("Learning XML"); author2.setText("Erik T. Ray"); //实例化输出格式对象 OutputFormat format = OutputFormat.createPrettyPrint(); //设置输出编码 format.setEncoding("UTF-8"); //创建需要写入的File对象 File file = new File("D:" + File.separator + "books.xml"); //生成XMLWriter对象,构造函数中的参数为需要输出的文件流和格式 XMLWriter writer = new XMLWriter(new FileOutputStream(file), format); //开始写入,write方法中包含上面创建的Document对象 writer.write(doc); }} |
运行结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构