

代码随想录——回溯19重新安排行程
1.代码随想录-逆波兰式、滑动窗口最大值2.代码随想录-栈与队列-有效的括号(括号匹配)3.代码随想录——栈与队列8-前K个高频元素4.二叉树的递归遍历和迭代遍历5.代码随想录——二叉树-11.完全二叉树的节点个数6.代码随想录——二叉树-12.平衡二叉树7.代码随想录——二叉树17-路径总和8.代码随想录——二叉树19.最大二叉树9.代码随想录——二叉树21、合并二叉树(附:递归算法复杂度分析)10.代码随想录——二叉树23、验证二叉搜索树11.代码随想录——25二叉搜索树的最小绝对值差(递归遍历如何记录前后两个指针)12.代码随想录——25.二叉搜索树中的众数13.代码随想录——26、二叉(搜索)树的最近公共祖先14.代码随想录——回溯8、组合总和II15.代码随想录——回溯9.分割回文串
16.代码随想录——回溯19重新安排行程
17.代码随想录——回溯 N皇后18.代码随想录——贪心8.跳跃游戏II19.代码随想录——贪心9.K次取反后最大化的数组和 && std::sort函数的第三个参数说明20.代码随想录——贪心13.分发糖果21.代码随想录——贪心算法:根据身高重建队列 & Vector原理22.代码随想录——贪心算法22单调递增的数字23.代码随想录——贪心23监控二叉树24.代码随想录——动态规划5.周总结25.代码随想录——动态规划9不同的二叉搜索树26.代码随想录——动态规划01背包27.代码随想录——动态规划13.分割等和子集28.代码随想录——动态规划14最后一块石头的重量II(01背包)29.动态规划——dp的含义归类(完全背包和01背包区别)30.动态规划——26单词拆分31.代码随想录——动态规划背包问题总结32.代码随想录——动态规划31打家劫舍III(树状DP)33.代码随想录——动态规划、股票问题34.代码随想录——单调栈35.回溯总结
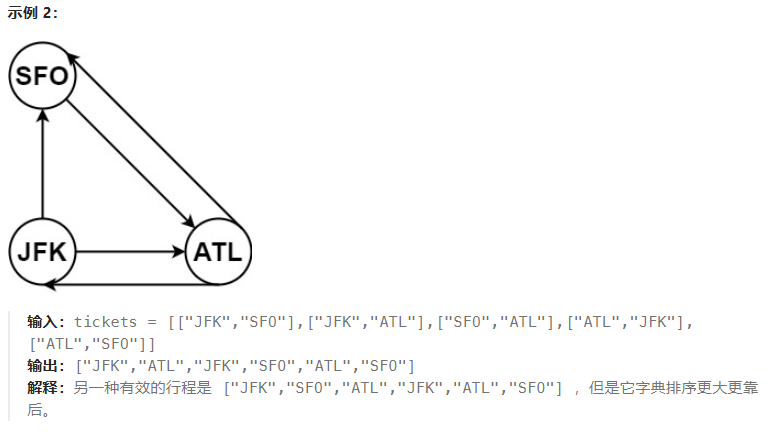
思路
回溯——超时代码
把选机票当成走迷宫问题,选择一次机票就进入下一个地点,然后标记此次路径已使用。直接使用回溯模板。
vector<string> result;
vector<string> path;
void backTracking(vector<vector<string>>& tickets,vector<bool>& used,int k){
if(k == tickets.size()){//所有机票都用过了
if(result.size()==0 || Compare(path,result)){
result=path;//如果现在的字典排序更小,就更换
}
return;
}
string cur;//现在在哪里
if(path.size()==0){
cur = "JFK";
path.emplace_back("JFK");
}
for(int i=0;i<tickets.size();i++){
cur = path[path.size()-1];
if(tickets[i][0] == cur){//机票满足cur->xx
if(used[i]== false){//机票还没用过
path.emplace_back(tickets[i][1]);//填入目的地
used[i] = true;//标记机票已使用
backTracking(tickets,used,k+1);
used[i]= false;//回溯,取消标记+目的地
path.pop_back();
}
}
}
}
bool Compare(vector<string>& path,vector<string>& result){
for(int i =0;i<path.size();i++){
string a = path[i];
string b = result[i];
if(a < b)return true;
else if( a > b)return false;
}
return false;
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
//所有的机票 必须都用一次 且 只能用一次 —— 回溯走迷宫
//只返回字典序最小的组合
vector<bool> used(tickets.size());
backTracking(tickets,used,0);
return result;
}
正确的回溯(深搜)代码
错误代码问题显而易见:
- 需要把所有行程找到,并且手动比较字典序
- 每次需要把所有机票遍历一次,没有使用数据结构进行优化
优化:
- 排序 + DFS
- 在进行回溯前,按照起点和终点对机票列表进行排序,这样字典序较小的路径会优先被探索,从而无需手动比较路径字典序,减少 Compare 的计算开销。
- 因为路径是按字典序构造的,第一个合法结果就是字典序最小的。DFS在找到第一个合法解后立即返回,避免无意义的继续搜索。
- 邻接表优化搜索空间
- 使用邻接表存储机票信息,并排序邻接表中的目的地,这样每次可以直接访问与当前地点相关的机票,减少不必要的遍历。
- 具体而言:邻接表即一对多的映射,可以使用std::unordered_map;排序字符串就是用std::map 或者std::multimap 或者 std::multiset。
这样存放映射关系可以定义为 unordered_map<string, multiset
含义如下:
unordered_map<string, multiset> targets:unordered_map<出发机场, 到达机场的集合> targets
unordered_map<string, map<string, int>> targets:unordered_map<出发机场, map<到达机场, 航班次数>> targets
这里我选择后者,因为后者可以"航班次数"这个字段的数字做相应的增减标记机票是否使用过
vector<string> result;
unordered_map<string,map<string,int>> targets;//unordered_map<起始机场,map<到达机场,航班次数>> 次数0或1,标记是否用过该机票
bool backTracking(int targetNum,string cur){//因为机票按字典序排序,所以找到有效行程时就是最小字典序,直接返回
if(result.size() == targetNum + 1){
return true;
}
for(pair<const string,int>& target : targets[cur]){
if(target.second > 0){
target.second--;
result.emplace_back(target.first);
if(backTracking(targetNum,target.first))return true;//如果找到了就一直return true
result.pop_back();
target.second++;
}
}
return false;
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
for(vector<string>& ticket : tickets){
targets[ticket[0]][ticket[1]]++;
}
result.emplace_back("JFK");
backTracking(tickets.size(),"JFK");
return result;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现