用python 来炒股二 BeautifulSoup爬虫信息新闻文章
使用python 炒股,最先要用的是数据收集,下文用爬取新闻实例来简述
数据获取
1. 打开指定得财经资讯网站,例如中证时报:http://stock.stcn.com/dapan/index.shtml
2. 建议用chrome浏览器来分析网站结构,指定需要提取的文章列表
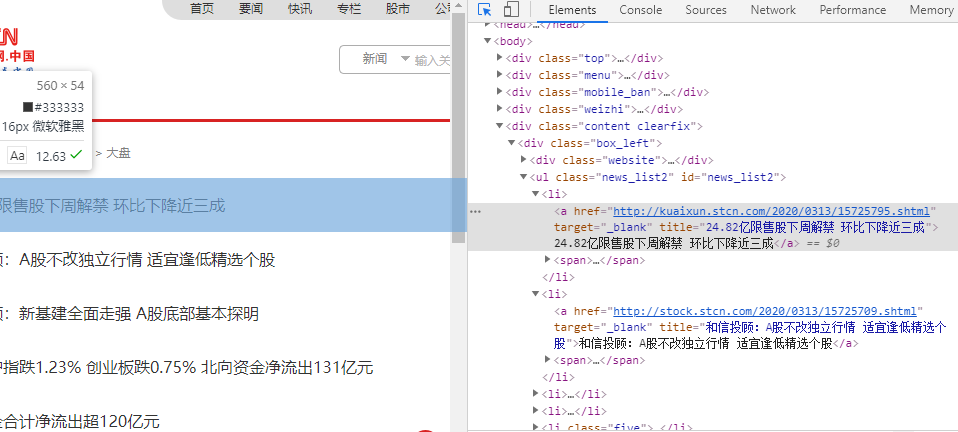
分析可得路径:
<head> , <body>, <div>'' ,<div>''' .... <li> <a>
此处路径较深,又涉及多重定位,若用find 只查一次,而用find_all 可查询多次,使用find_all 更合理。
多层嵌套div,要想提取下层的内容,有多种方法,这里例举常用的:
可以用最后一个 name='ul',attrs={'class':"news_list2"}, 也可以使用 name='div',attrs={'class':"content clearfix"}
假设第一层的 tag = 搜索结果
再来定位第二层的文章 sub_tag find in tag
如果网页的数据中,都是文章,简单提取的方式如:
soup.find_all("a") #在所有数据中找节点a
但结果往往不如意,因为常常会遇到其他广告或者推荐文章列表也显示进来。需要用if 或者for 条件来筛选,或者用正则方式匹配
代码示例
1.新建 .py 文件,导入BS
from bs4 import BeautifulSoup import requests import time import json url = 'http://stock.stcn.com/dapan/index.shtml' wb_data = requests.post(url) soup = BeautifulSoup(wb_data.content,'lxml')
2. for 循环定位文章节点
这种写法得优势:
- 避免用if 时多增加临时变量,节省内存开辟空间。即使这个<DIV> 是多个单中嵌套
- 用双重for 来查询定位时采用子类方式,迭代生成也节约了空间
- 特别说明,此时的路径虽然唯一,但是用 find_all 而不同find 是因为考虑到find 查询返回的结果不利于后续的操作,给后续嵌套的for 循环带来方便
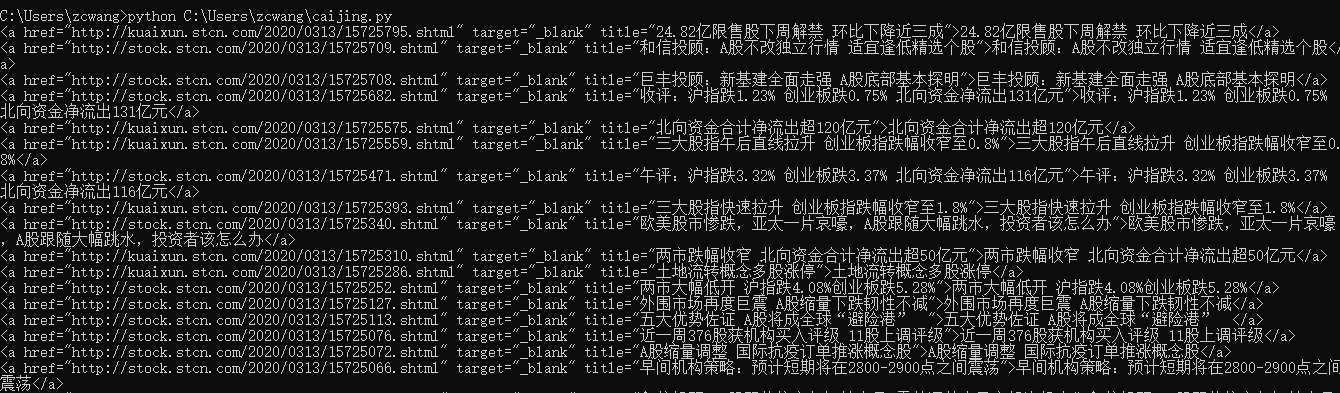
for tag in soup.find_all(name='ul',attrs={'class':"news_list2"}): for sub in tag.find_all("a"): print(sub)
3.显示结果:
于是对数据进行筛选,如果只保留文章标题
for tag in soup.find_all(name='ul',attrs={'class':"news_list2"}):
for sub in tag.find_all("a"):
print(sub.string) #因为sub仍然是个子对象tag,使用string 来提取字符串信息


 浙公网安备 33010602011771号
浙公网安备 33010602011771号