
函数进阶:闭包、装饰器、列表生成式、生成器、迭代器
名称空间
命名空间(又称“名称空间”): 存放名字的地方 (概念性的东西)。例如:变量x = 1, 1存放在内存中,命名空间就是存放名字x与1绑定关系的地方。
名称空间有3种:
- locals:是函数内的(或者是locals所在的那一层的)名称空间|,包括局部变量和形参
- globals:全局变量
- builtins: 内置模块的名字空间
不同变量的作用域不同就是由这个变量所在的命名空间决定的
作用域即范围:
1. 全局范围: 全局存活,全局有效
2. 局部范围: 临时存活, 局部有效
查看作用域方法:
globals()
locals()
作用域的查找顺序: LEGB
L: locals
E: enclosing (相邻的)
G:globals
B: builtins
闭包:
def func(): n = 10 def func2(): print('func2:', n) return func2 # 没有执行func2, 只是把func2的函数名(func2的内存地址) f = func() #执行func函数, 此时func()得到的结果是func2的内存地址,即f就是func2的内存地址 f() # 执行f, 由于f就是func2的内存地址,此时执行的就是func2函数 # 输出结果: # func2: 10 # 在函数(func)外部执行了函数内部的子函数(func2),而且子函数(func2)还能够调用其父级函数(func)作用域里面所有的值。 这种现象就是闭包
装饰器:
软件开发“开放-封闭” 原则:已经实现的功能代码不允许被修改,但可以被扩展。
另外,不要改变别人函数的调用方式
现在公司有一个网站模块功能如下:
def home(): print('---------主页----------') def america(): print('--------欧美专区-------') def japan(): print('--------日韩专区-------')
现在需要在america 和 japan这两个板块前加上以下登录认证功能:
login_status = False def login(): info = ['neo', 'abc123'] # 储存的用户信息 global login_status if not login_status: name_input = input('用户名:') password_input = input('密码:') if name_input == info[0] and password_input == info[1]: print('登陆成功') login_status = True else: print('密码错误') exit() else: print('用户已登录,通过检测')
现有如下几种方法可选:
1. 直接在America和Japan模块里面加上login认证程序, 如:
def japan(): login() # 把自己写的认证程序加到别人写好的模块里面 print('--------日韩专区-------')
这种方式违反“封闭”原则,pass。
2. 把america和japan这两个函数名当做参数传到login函数里面,如:
login_status = False def login(func): info = ['neo', 'abc123'] # 储存的用户信息 global login_status if login_status == False: name_input = input('用户名:') password_input = input('密码:') if name_input == info[0] and password_input == info[1]: print('登陆成功') login_status = True else: print('密码错误') exit() if login_status == True: print('用户已登录,通过检测') func() #把需要认证的模块函数名传进来调用执行 def home(): print('---------主页----------') def america(): print('--------欧美专区-------') def japan(): print('--------日韩专区-------') login(japan) #需要认证时,就把函数名当做参数变量传给login函数
这种方式改变了原模块(如japan())的调用方式
3. 装饰器:
login_status = False def login(func): def inner(): info = ['neo', 'abc123'] # 储存的用户信息 global login_status if login_status == False: name_input = input('用户名:') password_input = input('密码:') if name_input == info[0] and password_input == info[1]: print('登陆成功') login_status = True else: print('密码错误') exit() if login_status == True: print('用户已登录,通过检测') func() #把需要认证的模块函数名传进来调用执行 return inner #login()执行的时候,得到的结果只是 把inner的函数名(内存地址)返回给login(func) def home(): print('---------主页----------') def america(): print('--------欧美专区-------') def japan(): print('--------日韩专区-------') japan = login(japan) # login(japan)的执行结果是得到了inner函数的内存地址,再赋值给前面的japan 变量后,变量japan就是inner函数的内存地址。 japan() # 此时执行japan函数其实执行的里面的inner函数,由于闭包的父级函数执行完后里面的变量内存并不会释放、子函数inner里面能够使用login函数里面的所有参数变量,所以inner里面的变量func执行的时候会向login函数调用其传入的先前的japan函数。 这就是装饰器的原理。 #装饰器的正规写法: @login def japan(): print('---------日韩专区--------') # 1.两个函数组成一个闭包,装饰函数做父级,被装饰的函数放在子级函数里面,子级函数名return给父级 # 2. 被修饰的函数名作为参数传给父级函数 # 3.子级函数里面包括装饰代码(如:登录认证)和 被装饰的函数(如:japan())
附: 装饰器参数传递
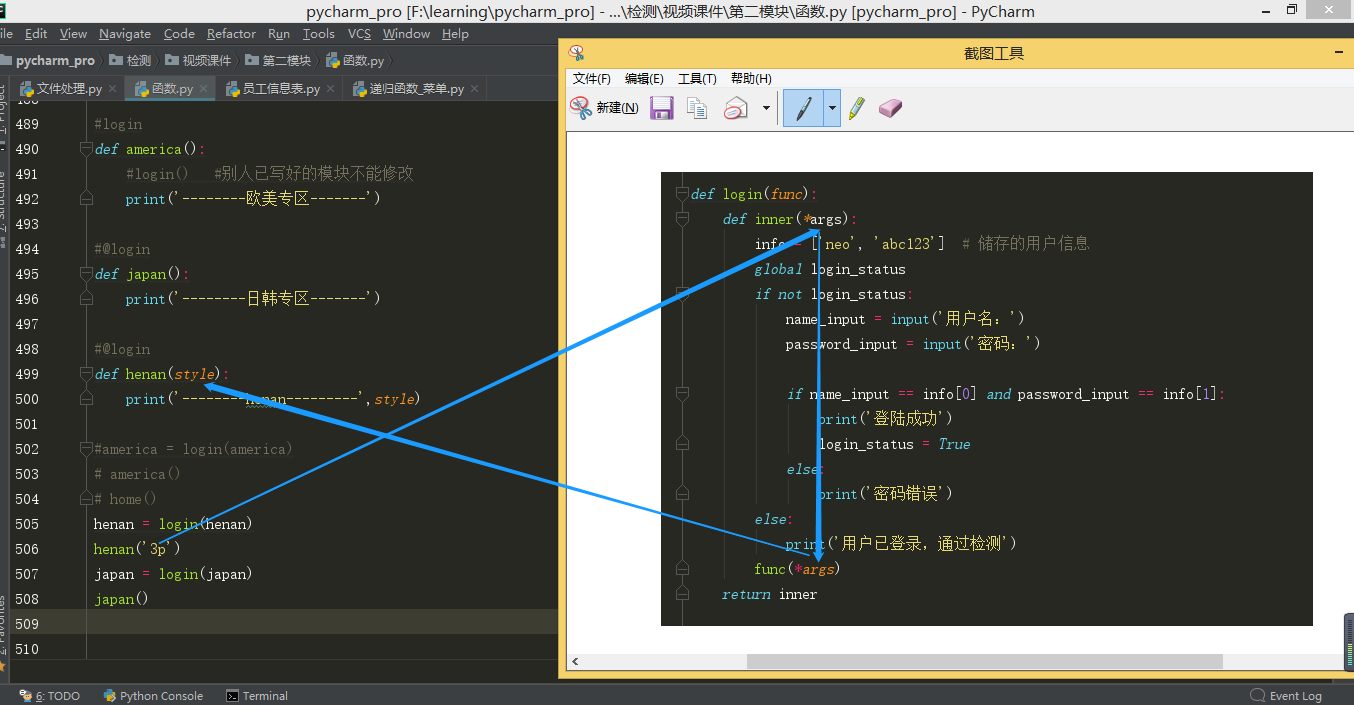
利用非固定参数 *args和 **kwargs 传不固定个数的参数
login_status = False def login(func): def inner(*args, **kwargs): info = ['neo', 'abc123'] # 储存的用户信息 global login_status if login_status == False: name_input = input('用户名:') password_input = input('密码:') if name_input == info[0] and password_input == info[1]: print('登陆成功') login_status = True else: print('密码错误') exit() if login_status == True: print('用户已登录,通过检测') func(*args, **kwargs) #把需要认证的模块函数名传进来调用执行 return inner #login()执行的时候,得到的结果只是 把inner的函数名(内存地址)返回给login(func) def home(): print('---------主页----------') @login def america(x,y,z): print('--------欧美专区-------',x,y,z) @login def japan(sytle): # 由于inner中的形参是非固定参数*args和**kwargs,所以传给inner函数多少个变量都行 print('--------日韩专区-------',style) japan('3p'’) # 此时japan(‘3p’)执行的是inner函数,由于原先的japan函数里面需要传一个变量,这个japan函数也需要传一个变量。变量传的顺序是: 新生成的这个japan函数 ---> inner函数 ---> inner里面的func函数(此时的func函数是原先的japan函数) ---> 原先的japan函数
带参数的装饰器:
login_status = False def login(style): # 由于装饰器带参数,这里需要加一个形参 def outer(func): #这一层需要传入被装饰的函数名并利用return调用里面的inner函数 def inner(*args, **kwargs): info = ['neo', 'abc123'] # 储存的用户信息 global login_status if login_status == False: name_input = input('用户名:') password_input = input('密码:') if name_input == info[0] and password_input == info[1]: print('登陆成功') login_status = True else: print('密码错误') exit() if login_status == True: print('用户已登录,通过检测') func(*args, **kwargs) return inner #把inner的内存地址返回给outer函数 return outer #把outer的内存地址返回给login函数 def home(): print('---------主页----------') @login('weixin') def america(x,y,z): print('--------欧美专区-------',x,y,z) @login('qq') # 这句话可分解成两步理解: 1. 先是运行login('qq'),此时得到的结果是 outer函数的内存地址 2. login('qq')变成outer的内存地址后,就变成了不带参数的装饰器的情况(例如前面分析的那一种) def japan(style): print('--------日韩专区-------') japan('3p') #执行装饰器
# 注:即使是多层闭包,最里层的变量也可以去它的爷爷级去调用参数。 哪怕是多层闭包,在程序彻底运行完前,参数变量的内存地址也不会释放,还可以被里面的各层函数调用。
生成器:
现有需求: 给列表 [0,1,2,3,4,5,6,7,8,9] 中的每个值加1
可以利用如下代码实现:
a = [0,1,2,3,4,5,6,7,8,9]
print(list(map(lambda x:x+1,a)))
还有一种新写法:
a = [0,1,2,3,4,5,6,7,8,9] a = [ i+1 for i in range(10)] # 这种写法就叫列表生成式 print(a) # 输出结果: # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
列表生成式语法:
[ 生成规则(三元运算) for i in 原先的列表 ]
如:
a = [0,1,2,3,4,5,6,7,8,9] a = [ i if i<5 else i*i for i in range(10)] # for 后面可以循环任何iterables, 如字典、列表、字符串等, 通过前面的运算把结果放到一个列表(或元祖)里面,但不能放到字典里面 print(a) # 输出结果: # [0, 1, 2, 3, 4, 25, 36, 49, 64, 81]
a = {'neo':'abc','alex':123}
b = [a[i] for i in a ]
print(b)
# 输出结果:
# ['abc', 123]
生成器(generator):
列表生成式:
a = [ i for i in range(10)]
我们把上面的列表生成式改动一下:
a = ( i for i in range(10)) # 把列表符号[]改成括号() # 利用这种方式就变成了一个生成器
print(a)
# 输出结果:
# <generator object <genexpr> at 0x0000001885E70EB8> # 打印结果显示a是一个生成器(generator)的内存地址, 此时a里面没有任何东西,它只是一个算法,但它已经有了生成数据的能力,让a产生数据的方式是利用next()去调用a
print(next(a)) # 输出结果为: 0
print(next(a)) # 输出结果为: 1
print(next(a)) # 输出结果为: 2
print(next(a)) # 输出结果为: 3
print(next(a)) # 输出结果为: 4
print(next(a)) # 输出结果为: 5
print(next(a)) # 输出结果为: 6
print(next(a)) # 输出结果为: 7
print(next(a)) # 输出结果为: 8
print(next(a)) # 输出结果为: 9 # 每利用next()调用一次a,a都会向下产生一个数据,并且不能后退。每生产完一个数据,生成器就停在了这个位置,下次再调用生产时,它会接着前一次的数据继续向下一个生产。所以,每个数据只能生产一次。
print(next(a)) # 输出结果为: 报错,并显示“StopIteration” # 所以 利用next的方式在调用完生成器里面的数据后会报错
生成器的特性:
1. 我想要什么数据它不会立即产生,我取一次它才创建一次
2. 生成器只能往前走(往下一个生产),不能往回退,原先生产过的值不可能再生产一次; 并且, 生产完数据后再利用next调用会报错
调用生成器一种是利用next(),还可以利用for循环调用。 例如:
a = ( i for i in range(10)) for i in a: # a为生成器内存地址 print(i) # 输出结果: # 0 # 1 # 2 # 3 # 4 # 5 # 6 # 7 # 8 # 9 # 利用for循环取生成器里面的地址,取完之后也不会报错,所以通常利用这种方式。
另外,next()可以手动调用生成器,也可以利用while调用,如:
a = ( i for i in range(5)) while True: print(next(a)) # 0 # 1 # 2 # 3 # 4 # 报错,StopIteration # 注: next()调用生成器有两种方式: 1. 手动一个个调用; 2. 利用while调用。 这两种方式的本质都是在利用next(),所以调用完之后都会报错。
range() 底层就是用生成器实现的 (Python3中)
Python2中 range(10)直接就是个列表(立即生成)
a = range(10) print(a) # 输出结果: # [0,1,2,3,4,5,6,7,8,9] #在Python2中range()直接就是列表, 但在Python3中,range()只是一个生成器,一种算法,根本没有创建列表
# 在Python2中,xrange()的功能就相当于Python3中的range()
# Python3中已经没有xrange()了
利用函数实现斐波那契数列(前两数为1,后面的数等于前面的两个数之和):
# 需求: 打印斐波那契数列的第10个值: def fib(max): a = 0 b = 1 count = 0 while count < max: print(b) a,b = b,a+b # 这种写法要注意: 此时b赋值给a,是把原先b的值赋值给a;a+b赋值给b,是把原先a的值和原先b的值赋给b count += 1 fib(10) # 输出结果: # 1 # 1 # 2 # 3 # 5 # 8 # 13 # 21 # 34 # 55
上面的fib()函数稍作修改就能变成生成器:
def fib(max): a = 0 b = 1 count = 0 while count < max: yield b # 只要加了yield,函数就会变成生成器。并且yield后面的对象(如:b)会return给调用fiber(max)函数的对象(例如:fiber(10)),只有在利用next()或for循环调用生成器的时候,fib()函数里面的代码才会一次次执行(就是说 不调用生成器的话,程序就永远冻结在了yield这一步,只有调用生成器(如next)它才会继续执行)。 a,b = b,a+b count += 1 f = fib(10) # 由于fib()函数里面有yield,所以fib(10)执行fib(max)函数时,函数内部的代码并没有任何的执行,只是把这个函数变成了一个生成器。 # 此时fib(10)的打印结果是:<generator object fib at 0x000000E6605D0EB8> # 需要把生成器的内存地址赋值给一个变量 print(next(f)) # 输出结果: 1 print(next(f)) # 输出结果: 1 print(next(f)) # 输出结果: 2 print(next(f)) # 输出结果: 3 print(next(f)) # 输出结果: 5 print(next(f)) # 输出结果: 8 print(next(f)) # 输出结果: 13 print(next(f)) # 输出结果: 21 print(next(f)) # 输出结果: 34 print(next(f)) # 输出结果: 55
总结1:
1. 原先函数只能在里面执行,你要是想要里面的执行结果只能return,一return整个函数就停止执行了;但生成器可以把函数里面执行的每一个值、每一个结果返回出来
2. 只要函数内部有yield, 函数名加()后,函数内部的代码根本不执行,只是生成了一个生成器对象
总结2:
生成器的创建方法:
1. 类似列表生成式的方法(但不是列表)
2. 函数内带有yield
这两种创建方式的区别: 类似列表生成式的方法最复杂只能处理一个三元运算
总结3:
Python2中: range == list xrange == 生成器 Python3中: range == 生成器 xrange 不存在
总结4: return vs yield
return: 返回数据,并终止函数
yield: 返回数据,并冻结函数当前的执行过程; 如果想要继续执行生成器,只能利用类似next()的方法再次唤醒程序。
def fib(max): a = 0 b = 1 count = 0 while count < max: yield b a,b = b,a+b count += 1 f = fib(10) for i in f: print(i)
next() 的作用: 唤醒被冻结(如yield)的函数执行过程,直到遇到下一个yield。
注: 类似列表生成式的方法底层也是yield函数
循环读取文件的原理也是生成器:
f = open('test.txt','r') for i in f: #在循环f的时候就是在循环一个生成器 print(i) # 循环一边就读取一行
注: next(生成器)的另一种写法: 生成器.__next__() (next两个各有两个下划线)
只要函数里面有yield,它就会变成一个生成器,遇到return生成器就会终止,生成器就会报错:
def range2(n): count=0 while count < n: yield count count += 1 new_range = range2(3) print(next(new_range)) print(next(new_range)) print(next(new_range)) print(next(new_range)) # 输出结果: # 0 # 1 # 2 # 报错, stopiteration # 上面生成器中假如了return: def range2(n): return 33333 count=0 while count < n: yield count count += 1 new_range = range2(3) print(next(new_range)) # 输出结果: # 报错,StopIteration: 33333 # return让生成器终止执行,就会报错
所以,函数有了yield之后:
1. 函数名加()就得到了生成器
2. return在生成器里,代表生成器的终止,就会报错
生成器的send方法:
可以利用 “ 生成器.send( '指令 ' ) ” 的方法给生成器内部发送指令, 发送的指令是发送到了 yield那一句。
def range2(n): count=0 while count < n: sign = yield count # send的指令发送给yield语句 print('-----检测-----',sign) count += 1 new_range = range2(5) print(next(new_range)) print(next(new_range)) print(new_range.send('test')) # 输出结果: # 0 # -----检测----- None # 1 # -----检测----- test # 2
# 注: 1. send发送的括号里面的内容不能为空
# 2. can't send non-None value to a just-started generator (大致意思就是说,你要是想用send方法调用生成器的第一次执行,send括号里面的内容必须为“None”(生成器起始的第1次并没有yield的等待)
# 3. 可以这么理解: next()这种调用方式的底层其实就是调用的send方法,只不过send的内容为“None”
# 4. next()只能唤醒程序执行,发送给生成器内部的指令只能是“None”; 而send不但可以唤醒生成器继续执行,而且可以给生成器内部发送任何指令
迭代器:
可直接作用于for循环的数据类型有:
1. 集合数据类型,如 list、tuple、dict、set、str等
2. generator,包括生成器和带yield的generator function
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用 isinstance()判断一个对象是不是Iterable对象:
from collections import Iterable print(isinstance(['a','b','c'],Iterable)) # 输出结果: # True from collections import Iterable print(isinstance((i for i in range(10)),Iterable)) # 输出结果: # True
定义:可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator (生成器只是迭代器的一种)
可以用 isinstance()判断一个对象是不是Iterator对象:
from collections import Iterator print(isinstance(['a','b','c'],Iterator)) # 输出结果: # False from collections import Iterator print(isinstance((i for i in range(10)),Iterator)) # 输出结果: # True
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、str、dict等Iterable变成Iterator可以使用iter()函数:
from collections import Iterator print(isinstance(iter(['a','b','c']),Iterator)) # 输出结果: # True a = ['a','b','c'] b = iter(a) print(b) print(a) print(next(b)) print(next(b)) # 输出结果: # <list_iterator object at 0x0000004C9B7BA080> # 生成器内存地址 # ['a', 'b', 'c'] # a # b # 可利用next()函数调用该生成器
注: Python3中的for循环本质上就是通过不断调用next()函数实现的
When a generator function is called, it returns a generator object without even beginning execution of the function. When next method is called for the first time, the function starts executing until it reaches yield statement. The yielded value is returned by the next call.
参考链接:https://anandology.com/python-practice-book/iterators.html
迭代器示例:
# 迭代器1 class yrange: def __init__(self, n): self.i = 0 self.n = n def __iter__(self): return self def __next__(self): if self.i < self.n: i = self.i self.i += 1 return i else: raise StopIteration() # 迭代器2 class zrange: def __init__(self, n): self.n = n def __iter__(self): return zrange_iter(self.n) class zrange_iter: def __init__(self, n): self.i = 0 self.n = n def __iter__(self): # Iterators are iterables too. # Adding this functions to make them so. return self def __next__(self): if self.i < self.n: i = self.i self.i += 1 return i else: raise StopIteration()
运行效果:
>>> y = yrange(5) # y 是 yrange 的实例化对象; >>> list(y) # 对 y 进行 list 实例化时,可简单理解成 [for i in y],y 遇到 for 调用 __iter__ 方法返回迭代器,然后for 执行不断调用其 __next__ 方法 [0, 1, 2, 3, 4] >>> list(y) # 两次 list 实例化时是对同一个 yrange 对象 [] >>> z = zrange(5) # z 是 zrange 的实例化对象 >>> list(z) # list 对 z 进行实例化时,[for i in y] ,z 遇到 for 调用其 __iter__ 方法返回 zrange_iter(self.n),zrange_iter 再对 self.n 进行实例化返回一个 zrange_iter 的对象(list 对 z 实例化两次就生成两个不同的 zrange_iter 的对象), zrange_iter 的对象遇到 for 会再调用 zrange_iter 的 __iter__ 方法 [0, 1, 2, 3, 4] >>> list(z) # 每次 list 对 z 进行实例化时,得到的都不同的 zrange_iter 的对象 [0, 1, 2, 3, 4]
参考链接:
https://anandology.com/python-practice-book/iterators.html
