从零开始山寨Caffe·拾贰:IO系统(四)
消费者
回忆:生产者提供产品的接口
在第捌章,IO系统(二)中,生产者DataReader提供了外部消费接口:
class DataReader { public: ......... BlockingQueue<Datum*>& free() const { return ptr_pair->free; } BlockingQueue<Datum*>& full() const { return ptr_pair->full; } ......... };
生产者DataReader本身继承了线程DragonThread,在其异步的线程工作函数中interfaceKernel()中,
不断地从pair的Free阻塞队列取出空Datum,在read_one()用KV数据库内容填充,再塞到Full队列中,如图:
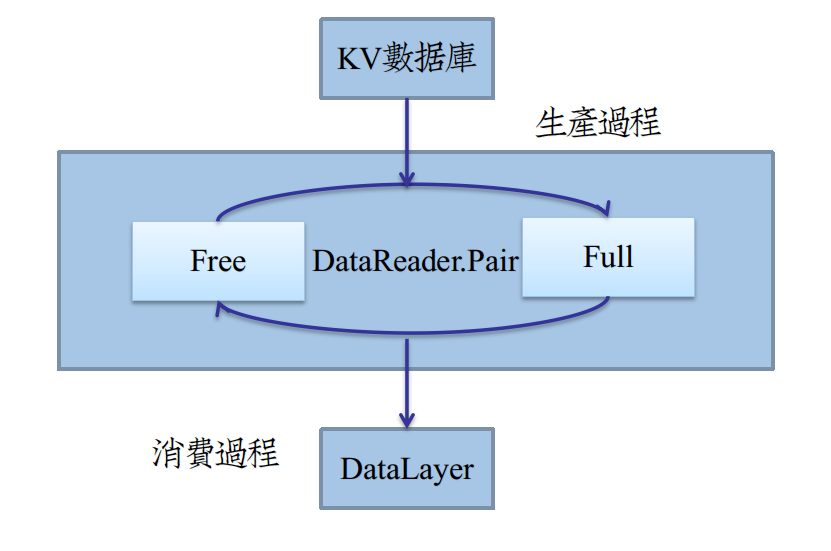
作为消费者(DataLayer),在从Datum获得数据后,立即做一份Copy,再把Datum塞回到Free队列中,继续生产。
整个过程就好像是一个工厂生产的循环链,Datum就好比一个包装盒。
生产者将产品放置其中,传递包装盒给消费者。消费者从中取出产品,让生产者回收包装盒。
回忆: 变形者加工产品接口
在第拾章,IO系统(三)中,变形者DataTransformer提供了数据变形的基接口:
void DataTransformer<Dtype>::transform(const Datum& datum, Dtype* shadow_data)
仔细观察一下transform的两个参数,你会发现整个transform过程,就是将Datum数据Copy到shadow_data的数组里。
这就是上节提到的“Copy”过程——从包装盒中取出产品,再变形加工。
加工放置的数组,之所以叫shadow_data,是因为它映射的是一个Blob的局部内存。
回忆一下Blob的shape,[batch_size,channels,height,width],便可知,一个Datum仅仅是一个Blob的1/batch_size。
让Transformer对映射的内存处理,避免了直接对Datum变形的不便。映射的内存空间,就是最终成品的实际空间,如图:
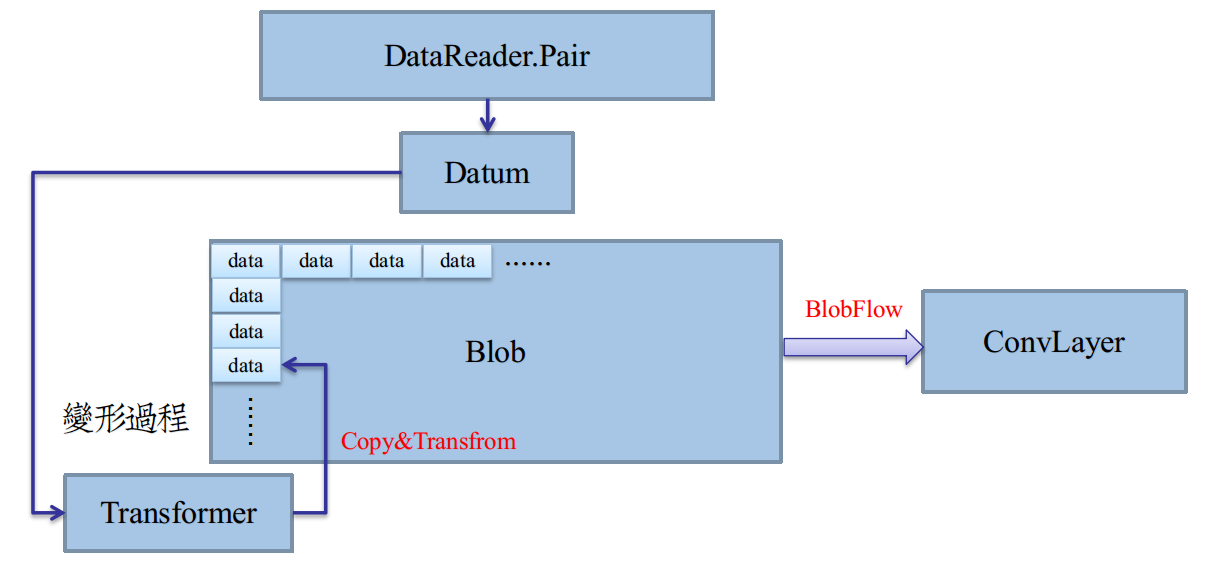
二级封装:从Datum到Blob
在上图中,Transformer提供了一个由Datum堆砌成Blob的途径。
我们只需要给Transformer提供Datum元素,以及一段内存空间(数组首指针)即可。
为了保证内存空间提供的正确性,有两点需要保障:
①每个Datum在Blob的偏移位置必须计算出来,第玖章BlobFlow给了一点偏移的思路,
只要偏移offset=Blob.offset(i)即可,i 为一个Batch内的样本数据下标。
②内存空间,也就是Blob具体的shape必须提前计算出来,而且必须启动SyncedMemory自动机,分配实际内存。
考虑一个Blob的shape,[batch_size,channels,height,width],后三个shape都可以由Datum推断出来。
至于batch_size,是一个由使用者提供的超参,可以根据网络定义直接获取。
由Datum推理channe/height/width,由DataTransformer的inferBlobShape完成,在第拾章IO系统(三)已经给出。
二级生产者
第捌章IO系统(二)介绍了LayerParameter中的prefetch概念。
在构造一个DataReader时,指定了默认Pair的缓冲区大小:
DataReader::DataReader(const LayerParameter& param){ ptr_pair.reset(new QueuePair( param.data_param().prefech()*param.data_param().batch_size())); ........ }
total_size=prefetch*batch_size
这个大小表明了DataReader需要预缓冲prefetch个Batch,每个Batch有batch_size个Datum单元。
在 单生产者单缓冲区 一节的最后,讨论了多GPU下,如何使用单Pair的补救措施:
这可能是Caffe源码的本意。在这种方案中,DataReader和DataLayer是无须改动代码的。
只要我们加大DataParameter里的prefech数值,让CPU多缓冲几个Batch,为多个GPU准备就好了。
prefetch的数量由用户指定,而且也是一个上界,而且显然不能全部将整个KV数据库prefetch完。
于是,以Batch为单位的二级封装,需要一个二级生产者和消费者,而且同样是异步的,如IO系统(二)的图:
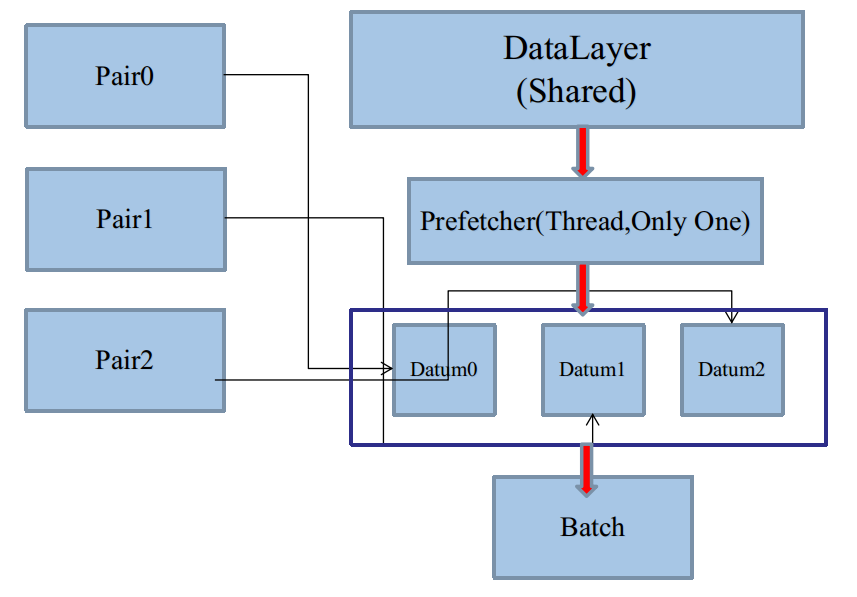
二级生产者,在Caffe里就是DataLayer衍生的线程。二级消费者,恰恰就是DataLayer本身。
DataLayer集二级生产者与消费者于一体,这归功于面向对象技术的多重继承。
类继承体系
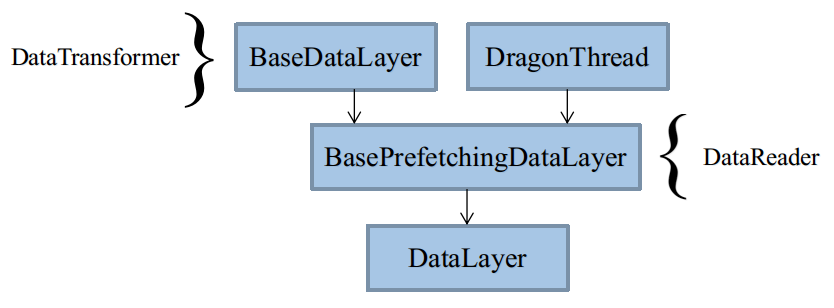
最终使用的是DataLayer,被拆解成3个类BaseDataLayer、BasePrefetchingDataLayer、DataLayer。
三个类负责不同的任务,你也可以整合在一起写。
构造函数执行顺序与二级生产者预缓冲流程
二级C++最喜欢考继承类的执行顺序,当然,这里搞清楚这点至关重要。
除了基本的类构造函数外,我们还需要考虑Layer类setup的具体函数layerSetup。

几个DataLayer的layerSetup相当混乱,几乎每个都各司其职,①②③④顺序不能颠倒。
完成全部setup之后,才能让二级生产者工作。
生产单位以一个Batch为单元,每个Batch包含DataBlob和LabelBlob(可选)。
二级生产缓冲区
二级缓冲区构建于BasePrefetchingDataLayer类中。
template<typename Dtype> class BasePrefetchingDataLayer :public BaseDataLayer<Dtype>,public DragonThread { public: ....... const int PREFETCH_COUNT; protected: ....... Batch<Dtype>* prefetch; BlockingQueue<Batch<Dtype>*> free; BlockingQueue<Batch<Dtype>*> full; };
产能上界由常数PREFETCH_COUNT指定,来源于proto参数DataParamter里prefetch大小。
在BasePrefetchingDataLayer构造函数中,用new申请等量的堆内存prefetch。
注意这里不要使用shared_ptr,比较麻烦,而且Batch有可能会被智能指针提前释放,应当手动析构。
可以看到,默认提供了和DataReader类似的消费者接口free/full,不过这消费的是Batch,而不是Datum。
没有用函数封装,是因为DataLayer自己生产,自己消费。
二级生产
同DataReader的一级生产类似,二级生产需要从free队列pop,填充,再塞入full。
生产过程于BasePrefetchingDataLayer的interfaceKernel函数中。
由于多重继承的关系,interfaceKernel函数来自父类DragonThread
template<typename Dtype> void BasePrefetchingDataLayer<Dtype>::interfaceKernel(){ try{ while (!must_stop()){ Batch<Dtype> *batch = free.pop(); //batch has already reshape in dataLayerSetup loadBatch(batch); // pure abstract function full.push(batch); //product } } catch (boost::thread_interrupted&) {} }
loadBatch函数与DataReader的read_one函数效果类似,负责填充batch。
二级生产与异步流同步
第贰章主存模型末尾介绍了SyncedMemory异步提交显存Memcpy的方法。
第玖章BlobFlow中,且已知SyncedMemory隶属于Blob的成员变量。
当数据缓冲至Blob级别时,就需要考虑提前向显存复制数据了。
第陆章IO系统(一)开头给了这张图:

可以看到,DataLayer处于CPU与GPU的分界点,DataLayer源输入由CPU主控,存于内存。
而DataLayer的下一层是计算层,源输入必须存于显存。
于是,尽管DataLayer的前向传播函数forward(bottom,top)只是复制数据,但是更重要的是转换数据。
在上一节的CPU异步线程工作函数interfaceKernel中,我们可以看到,Batch(Blob)级别已经构成,
而此时整个神经网络Net可能正在初始化,距离Net正式启动前向传播函数Net.forward(),需要显存数据,还有一段时间。
利用这段时间,可以利用CUDA的异步流预先由内存向显存转换数据,据此,完善interfaceKernel函数:
template<typename Dtype> void BasePrefetchingDataLayer<Dtype>::interfaceKernel(){ // create GPU async stream // speed up memcpy between CPU and GPU // because cudaMemcpy will be called frequently // rather than malloc gpu memory firstly(just call cudaMemcpy) #ifndef CPU_ONLY cudaStream_t stream; if (Dragon::get_mode() == Dragon::GPU) CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking)); #endif try{ while (!must_stop()){ Batch<Dtype> *batch = free.pop(); //batch has already reshape in dataLayerSetup loadBatch(batch); // pure abstract function #ifndef CPU_ONLY if (Dragon::get_mode() == Dragon::GPU){ batch->data.data()->async_gpu_data(stream); // blocking this thread until host->device memcpy finished CUDA_CHECK(cudaStreamSynchronize(stream)); } #endif full.push(batch); //product } } catch (boost::thread_interrupted&) {} // destroy async stream #ifndef CPU_ONLY if (Dragon::get_mode() == Dragon::GPU) CUDA_CHECK(cudaStreamDestroy(stream)); #endif }
使用异步流,需要用cudaStreamCreateWithFlags申请Flag为cudaStreamNonBlocking的流。
cudaStreamNonBlocking的值为0x1,代表此流非默认Memcpy流(默认流)
与之相对的是Flag为cudaStreamDefault的流,值为0x0,这是主复制流,cudaMemcpy的任务全部提交于此。
使用Blob内提交异步流的函数async_gpu_data(stream)[稍后给出]后,需要立即阻塞(同步)该CPU线程。
使用cudaStreamSynchronize(stream),直到GPU返回复制完毕信号之前,CPU一直同步在本行代码。
最后,需要释放异步流。
二级消费者
即DataLayer的forward函数。
由于大量工作已经在父类中做完,DataLayer的消费函数相对简单。
template <typename Dtype> void DataLayer<Dtype>::forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ // consume Batch<Dtype> *batch = full.pop("DataLayer prefectching queue is now empty"); dragon_copy<Dtype>(batch->data.count(), top[0]->mutable_cpu_data(), batch->data.cpu_data()); if (has_labels) dragon_copy(batch->label.count(), top[1]->mutable_cpu_data(), batch->label.cpu_data()); free.push(batch); }
直接访问full队列获取一个可用的Batch,完成消费。
将batch数据(data/label)分别复制到top里,完成Blob的Flow,提供给下一层计算。
template <typename Dtype> void DataLayer<Dtype>::forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ Batch<Dtype> *batch = full.pop("DataLayer prefectching queue is now empty"); dragon_gpu_copy(batch->data.count(), top[0]->mutable_gpu_data(), batch->data.gpu_data()); if (has_labels) dragon_gpu_copy(batch->label.count(), top[1]->mutable_gpu_data(), batch->label.gpu_data()); free.push(batch); }
GPU版本,直接替换copy函数为GPU版本即可。
(注:Caffe在forward_gpu()最后,对默认流的强制同步是没有必要的。
Memcpy也本身不是异步执行,不需要额外同步。对默认流同步,也不会影响异步流)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号