mysql优化

-
根据数据库的范式,设计表结构,表结构设计的好坏直接关系到SQL语句的复杂度
-
适当的将表进行拆分,原本需要做join的查询只需要表查询就可以了
-
数据库主机的IO性能是需要优先考虑的一个因素。
-
数据库主机和普通的应用程序服务器相比,资源要相对集中很多,单台主机上所需要进行的计算量自然也就比较多,所以数据库主机的CPU处理能力也是一个重要的因素。
-
数据库主机的网络设备(一般指网卡等)的性能也可能会成为系统的瓶颈。
配置远程连接
1. 登进MySQL
2. 输入以下语句,进入mysql库:
use mysql
3. 更新域属性,'%'表示允许任意IP地址访问:
update user set host='%' where user ='root';
4. 执行以上语句之后再执行:
FLUSH PRIVILEGES;
5. 再执行授权语句:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'WITH GRANT OPTION;
https://www.percona.com/downloads/percona-toolkit/LATEST/
wget https://www.percona.com/downloads/percona-toolkit/3.2.1/binary/redhat/7/x86_64/percona-toolkit-3.2.1-1.el7.x86_64.rpm
yum localinstall percona-toolkit-3.2.1-1.el7.x86_64.rpm
show variables like 'slow_query_log';
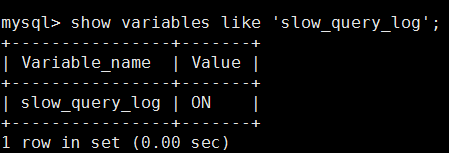
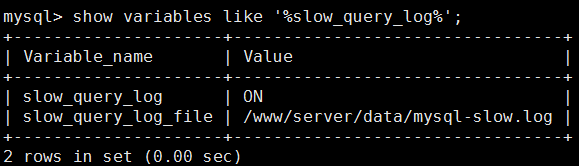
检查慢日志路径:
show variables like '%slow_query_log%';
pt-query-digest --limit=100% /www/server/data/mysql-slow.log(慢日志路径)
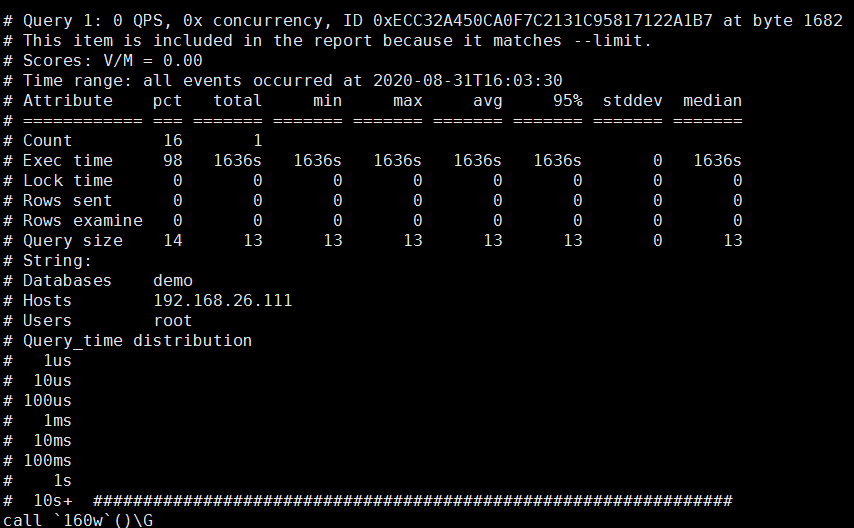
pt-query-digest是用于分析mysql慢查询的一个第三方工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。
可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题讲行优化
MySQL实例的快速汇总。
死锁:是指两个或则多个事务在同一个资源上相互占用,并请求锁定对方占用的资源,而导致恶性循环的现象;
当产生死锁的时候,MySQL会回滚一个小事务的SQL,确保另一个完成。上面是死锁的概念,而在MySQL中innodb会出现死锁的情况,
但是查看死锁却很不“智能”。只能通过 show engine innodb status 查看,但只保留最后一个死锁的信息,之前产生的死锁都被刷掉了。
下面介绍的工具却很容易做到记录。
pt-deadlock-logger --ask-pass --run-time=10 --interval=3 --create-dest-table --dest D=test,t=deadlocks u=root,P=123456
pt-index-usage 分析索引
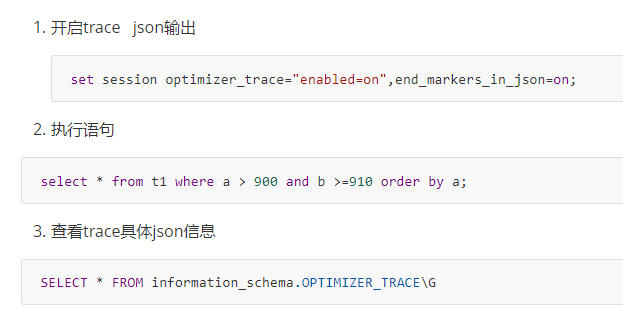
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。


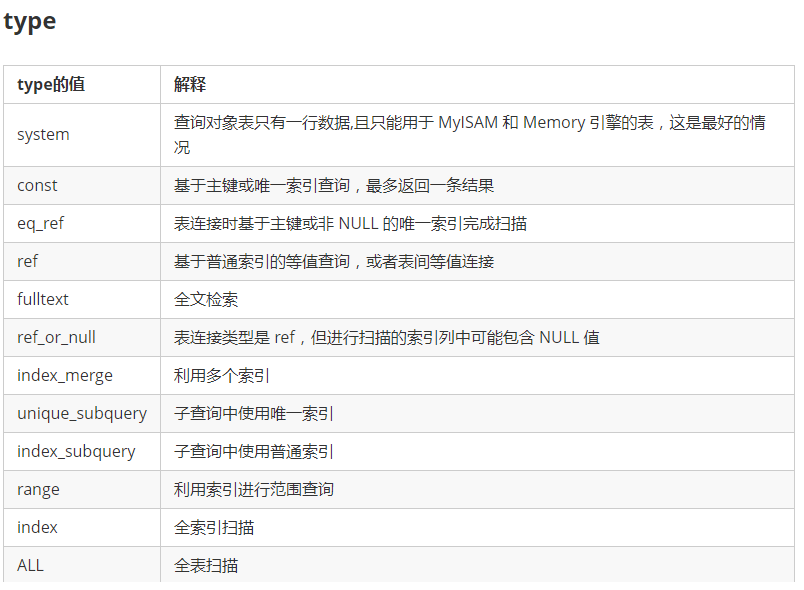
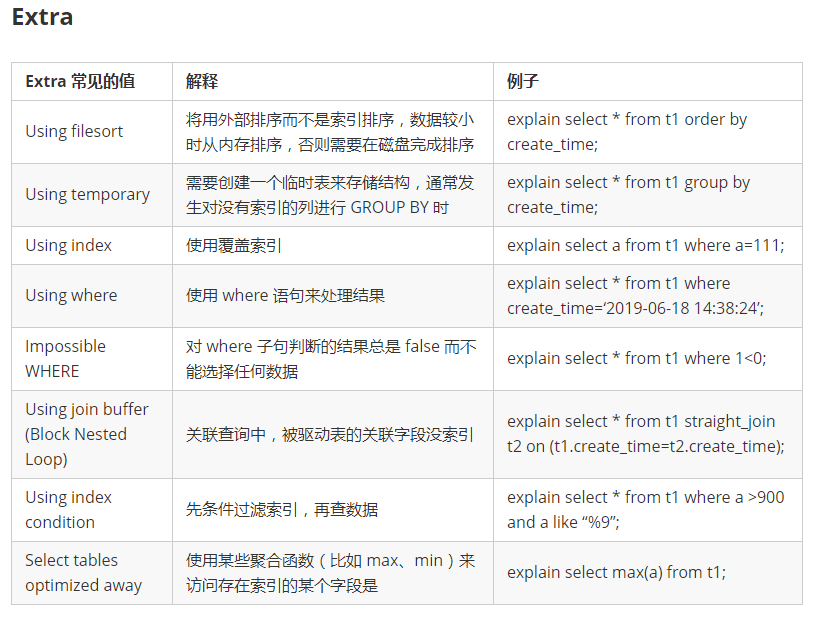
sql语句记录开销 如 IO 上下文切换 cpu 内存。 调整和优化。
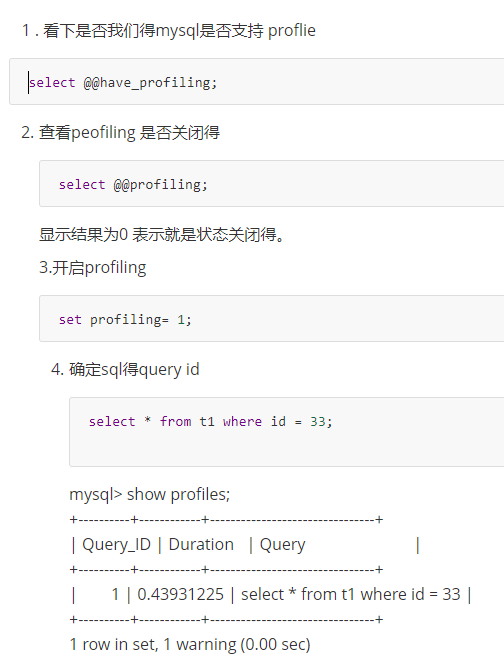
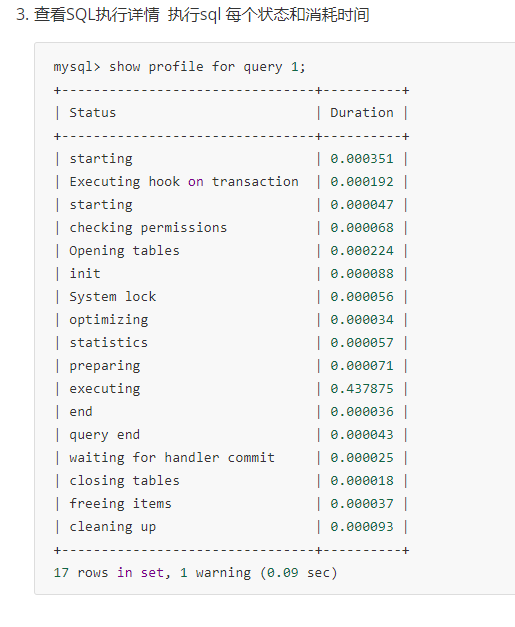
通过trace 能够进一步了解为什么优化器选择a 不选择b
建表语句:
CREATE TABLE `t1` ( /* 创建表t1 */
`id` int(11) NOT NULL auto_increment,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;



主键索引
查询索引
全文索引
唯一索引
use muke; /* 使用muke这个database */ drop table if exists t9_1; /* 如果表t9_1存在则删除表t9_1 */ CREATE TABLE `t9_1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_a` (`a`), KEY `idx_b_c` (`b`,`c`) ) ENGINE=InnoDB CHARSET=utf8mb4; drop procedure if exists insert_t9_1; /* 如果存在存储过程insert_t9_1,则删除 */ delimiter ;; create procedure insert_t9_1() /* 创建存储过程insert_t9_1 */ begin declare i int; /* 声明变量i */ set i=1; /* 设置i的初始值为1 */ while(i<=1600000)do /* 对满足i<=100000的值进行while循环 */ insert into t9_1(a,b,c,d) values(i,i,i,i); /* 写入表t9_1中a、b两个字段,值都为i当前的值 */ set i=i+1; /* 将i加1 */ end while; end;; delimiter ; /* 创建批量写入100000条数据到表t9_1的存储过程insert_t9_1 */ call insert_t9_1(); /* 运行存储过程insert_t9_1 */ insert into t9_1(a,b,c,d) select a,b,c,d from t9_1; insert into t9_1(a,b,c,d) select a,b,c,d from t9_1; insert into t9_1(a,b,c,d) select a,b,c,d from t9_1; insert into t9_1(a,b,c,d) select a,b,c,d from t9_1; insert into t9_1(a,b,c,d) select a,b,c,d from t9_1; /* 把t9_1的数据量扩大到160万 */
数据检索条件字段添加索引,
聚合函数对聚合字段添加索引,
对排序字段添加索引。
为了防止回表添加索引关联查询在关联查询字段添加索引等。
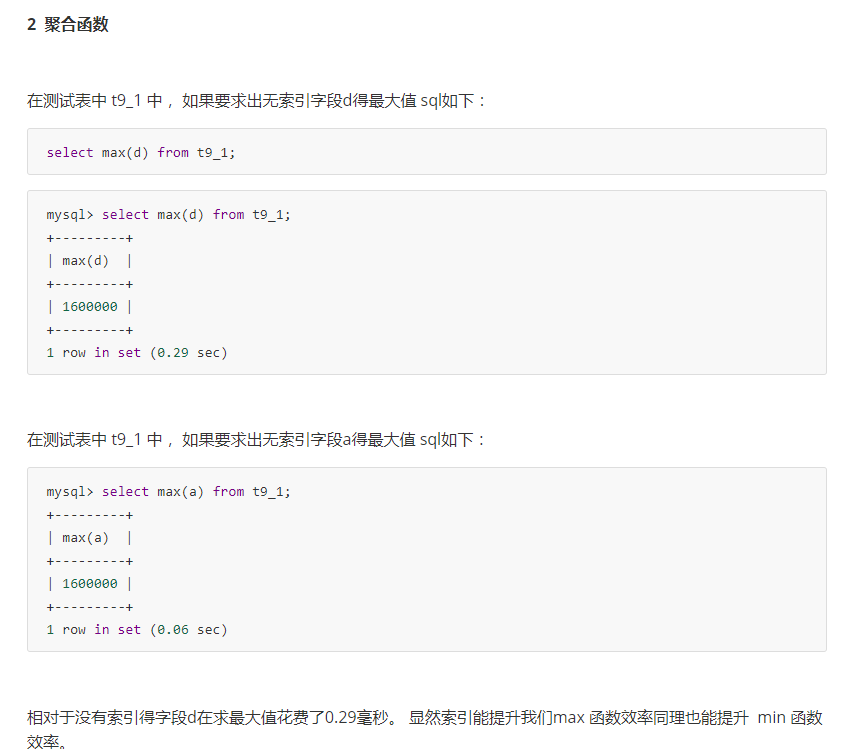
用上面建表语句构建得表得数据进行测试。 首先我们把没有索引字段得d作为条件进行查询:
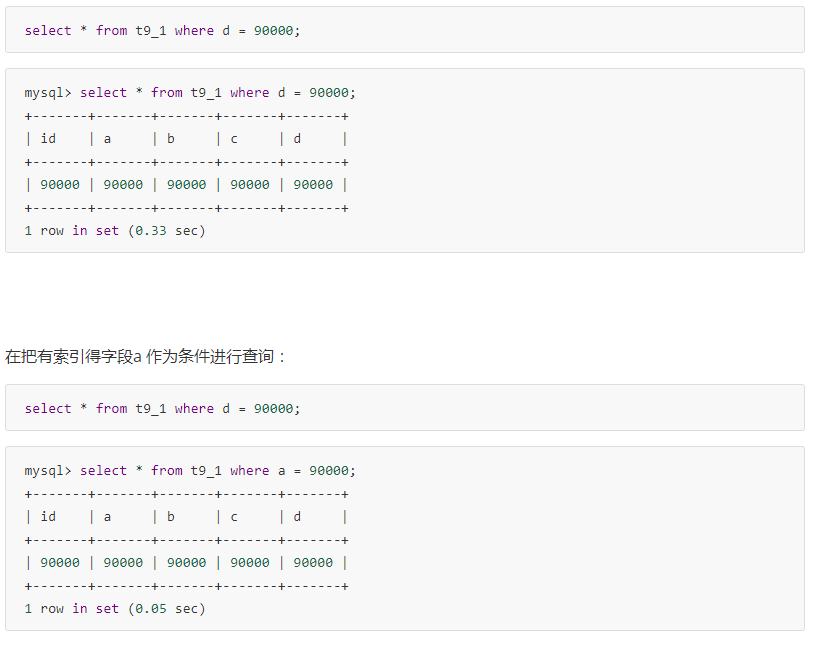
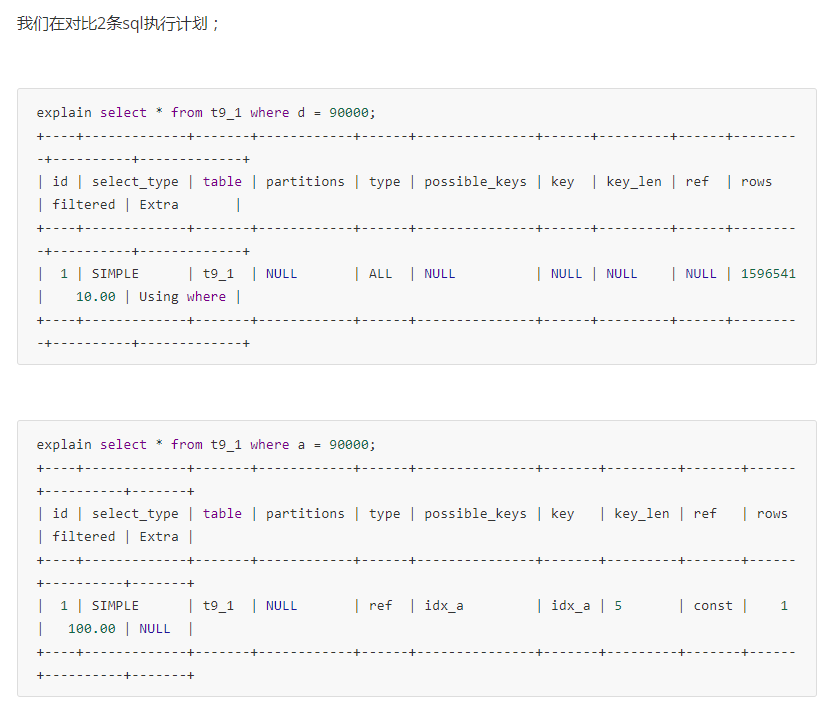
前者type字段为ALL 后者 type字段为ref, 显然后者性能好
row是字段 前者1596541后者 1 在由索引得情况下扫描行数大大降低了。
因此建议数据检索时。 在条件字段添加索引