

12行代码教大家写出简易的爬虫程序,今天爬取的是B站电影排行榜
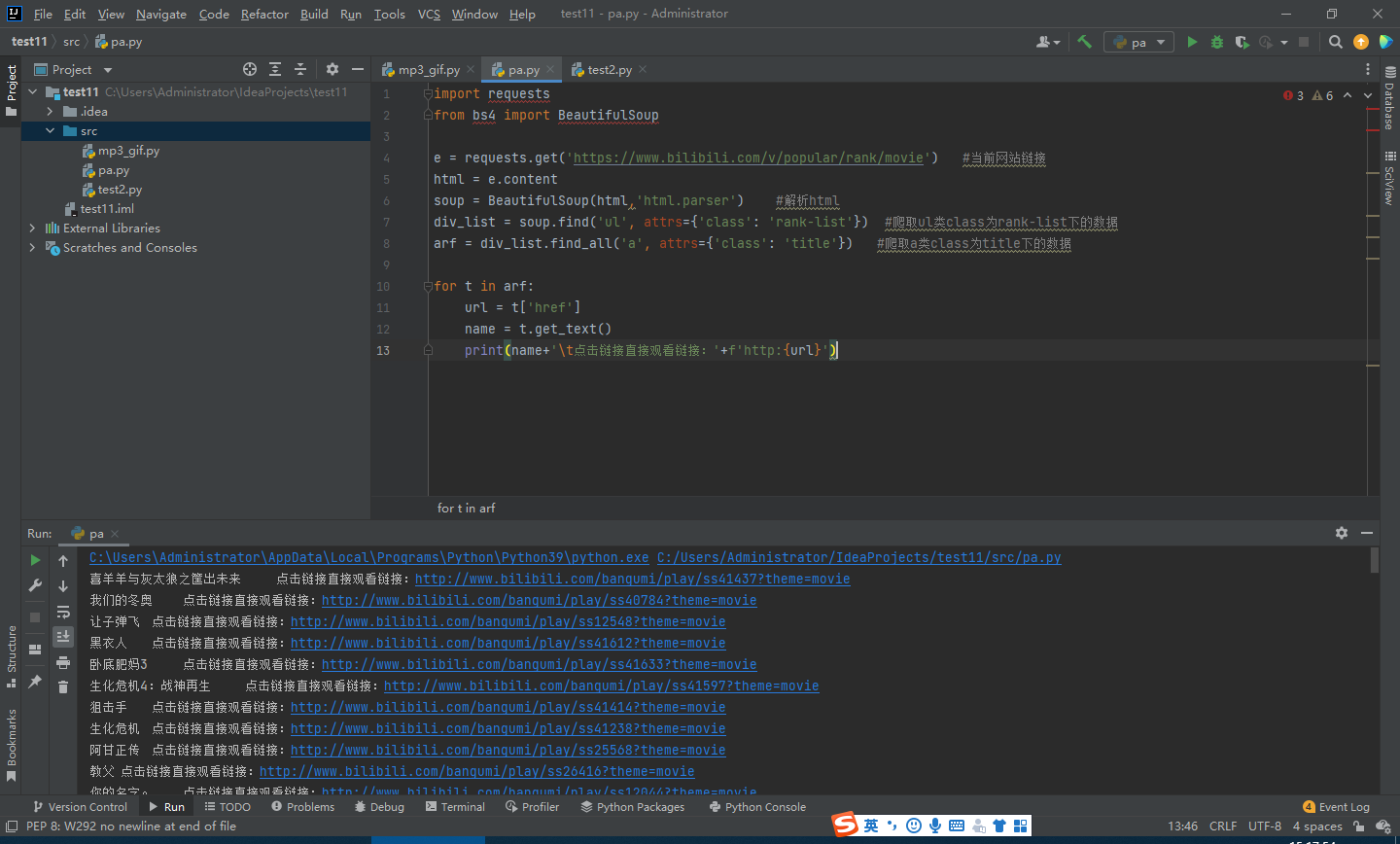
话不多说直接上代码,记得导入包;
import requests from bs4 import BeautifulSoup e = requests.get('https://www.bilibili.com/v/popular/rank/movie') #当前网站链接 html = e.content soup = BeautifulSoup(html,'html.parser') #解析html div_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul类class为rank-list下的数据 arf = div_list.find_all('a', attrs={'class': 'title'}) #爬取a类class为title下的数据 for t in arf: url = t['href'] name = t.get_text() print(name+'\t点击链接直接观看链接:'+f'http:{url}')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号