
Linux新手必须掌握的之grep及正则表达式
正则表达式引擎
grep [OPTIONS] PATTERN [FILE...]
选项:
--color=auto:对匹配到的文本着色显示,例如:

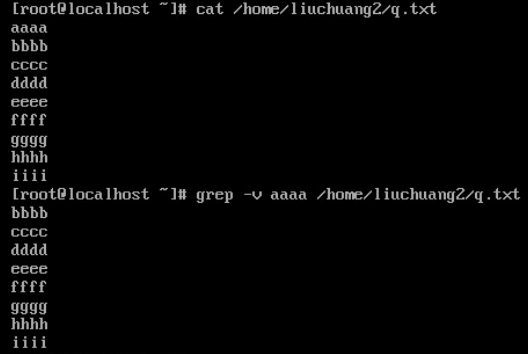
-v:显示不能被PATTERN匹配到的,例如:先查看文档里内容,再通过-v来查看
-i:忽略字母大小写
-o:仅显示匹配到的字符串
-q:不输出任何信息,如果想知道是否成功,可以用 echo $? 命令来查看

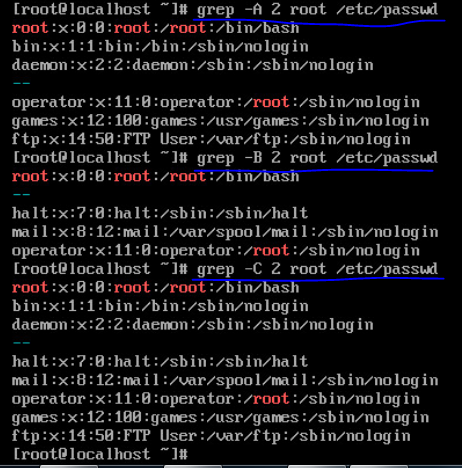
-A + 数字 :显示匹配到的行及后n行
-B + 数字:显示匹配到的行及前n行
-C + 数字:显示匹配到的行及前后各n行。例如:
基本正则表达式元字符
字符匹配
. :匹配任何单个字符
[ ]:匹配指定范围内任意单个字符,例如:[0-9]匹配任意一个数字
[^]:匹配指定范围外的任意单个字符,例如:[^0-9]匹配任意一个非数字
[:digit:]:任意数字
[:lower:]:任意小写字母
[:upper:]:任意大写字母
[:alpha:]:任意字母
[:alnum:]:任意数字或字母
[:punct:]:任意标点符号
[:space:]:空格
匹配次数:用在要指定次数的字符后面,意思是前面这个字符出现的次数
* :匹配任意个字符,例如:x*y可以表示:xaaay,xay,x12y等
.*:匹配任意长度的任意字符
\?:匹配前面字符0次或1次
\+:匹配前面字符1次或多次
\{m\}:匹配前面字符m次
\{m,n\}:匹配前面字符至少m次,最多n次
\{0,n\}:匹配前面字符最多n次
\{m,\}:匹配前面字符最少m次
位置锚定:
^:行首锚定,用于最左侧
$:行尾锚定,用于最右侧
所以,^$代表,空行
^PATTERN$:匹配整行
\<或\b:词首锚定,用于单词模式的左侧
\>或\b:词尾锚定,用于单词模式的右侧
\<PATTERN\>:匹配整个单词
分组:
\(\):将一个或多个字符捆绑在一起,当做一个整体处理,例如:\(xy\)*ab可以当做xyab,xyxyab,xyxyxyab等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号