这是一份简单到没朋友的上手图数据库的图文教程
前几天和社区小伙伴友好交流(闲聊),不少加入 NebulaGraph 的小伙伴虽然对图感兴趣,但是因为业务调整或者是时间缘故,最终没能用上 NebulaGraph。而他们当中不少的小伙伴说,春节我打算好好学习一番。既然大家有此打算,那 Nebula 一定要来助力一番。
本文是一份极度友好,你即便只会一个开机操作不懂任何数据库,你也能获得像是下图这样的直观关系图谱。
* 注:本文虽然看过篇幅很长,大多数是为了方便新手对照加入了大量的图片供参考,别担心用上图数据库的过程很复杂:它真的很简单,几分钟就搞定了~
写在前面
写给新手
本文作者是一个 SQL 都不会写的小运营,她根据文档完成了 NebulaGraph 的部署和可视化工具 NebulaGraph Studio、NebulaGraph Explorer 的部署,以及完成了简单的图探索。优秀如你,一定可以完成本次的 NebulaGraph 图库打卡活动~
本文所用操作系统为 macOS,采用 Docker 和云服务两种方式来部署 NebulaGraph。如果你采用 Docker 部署方式,而操作系统为 Windows,记得自行搜索“Windows 如何安装使用 Docker Desktop”。
写给老手
如果你已经完成了部署,会用 NebulaGraph Studio 之类的图探索工具。那么,你可以试试由思为提供的进阶实践教程(难度依次增加):
NebulaGraph 和可视化工具部署
为了降低难度(其实是没有 Linux 机器),本次部署采用了 Docker 方式,按照文档:https://docs.nebula-graph.com.cn/3.6.0/4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose/,一步步执行。
你可以按照文档一步步操作,也可以只看本文完成 Docker 的部署安装。
Docker Compose 安装
首先,安装 Docker Compose。这里我们直接安装 Docker Desktop(Docker 桌面版),它提供了 Docker Compose。点击此处:https://www.docker.com/products/docker-desktop/,自行完成安装。
安装完成之后,点击你的 Docker 图标,运行 Docker。
当你看到上图,状态栏有 Docker 的图标,说明你的 Docker 环境已 ready。我们可以来验证下:打开你的 terminal,输入命令:docker-compose version,有像下图一样的返回结果,说明你的 Docker 可以开始工作了。

NebulaGraph 部署
现在有 Docker Compose 了,我们来安装下图数据库。
还是那个执行了 Docker 版本查询的 terminal,输入命令:
git clone -b release-3.6 https://github.com/vesoft-inc/nebula-docker-compose.git
让命令运行一段时间,看到下图:
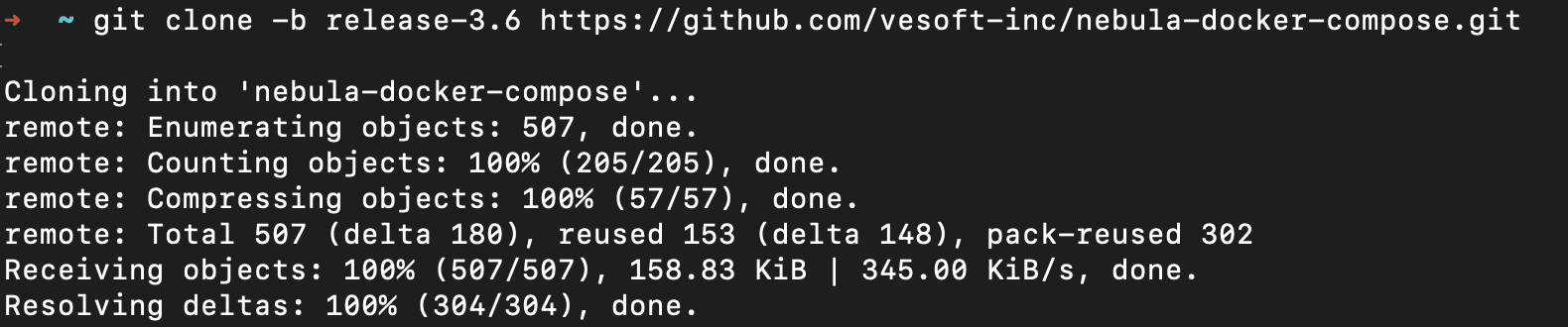
好的,到此为止。你已经有了优秀的图数据库 NebulaGraph,完成了它的部署。
NebulaGraph 服务启动
下面,我们来启动 NebulaGraph。非常简单的两条命令,还是在 terminal 里执行:
# 切到 nebula-docker-compose 目录
cd nebula-docker-compose
# 拉起服务
docker-compose up -d
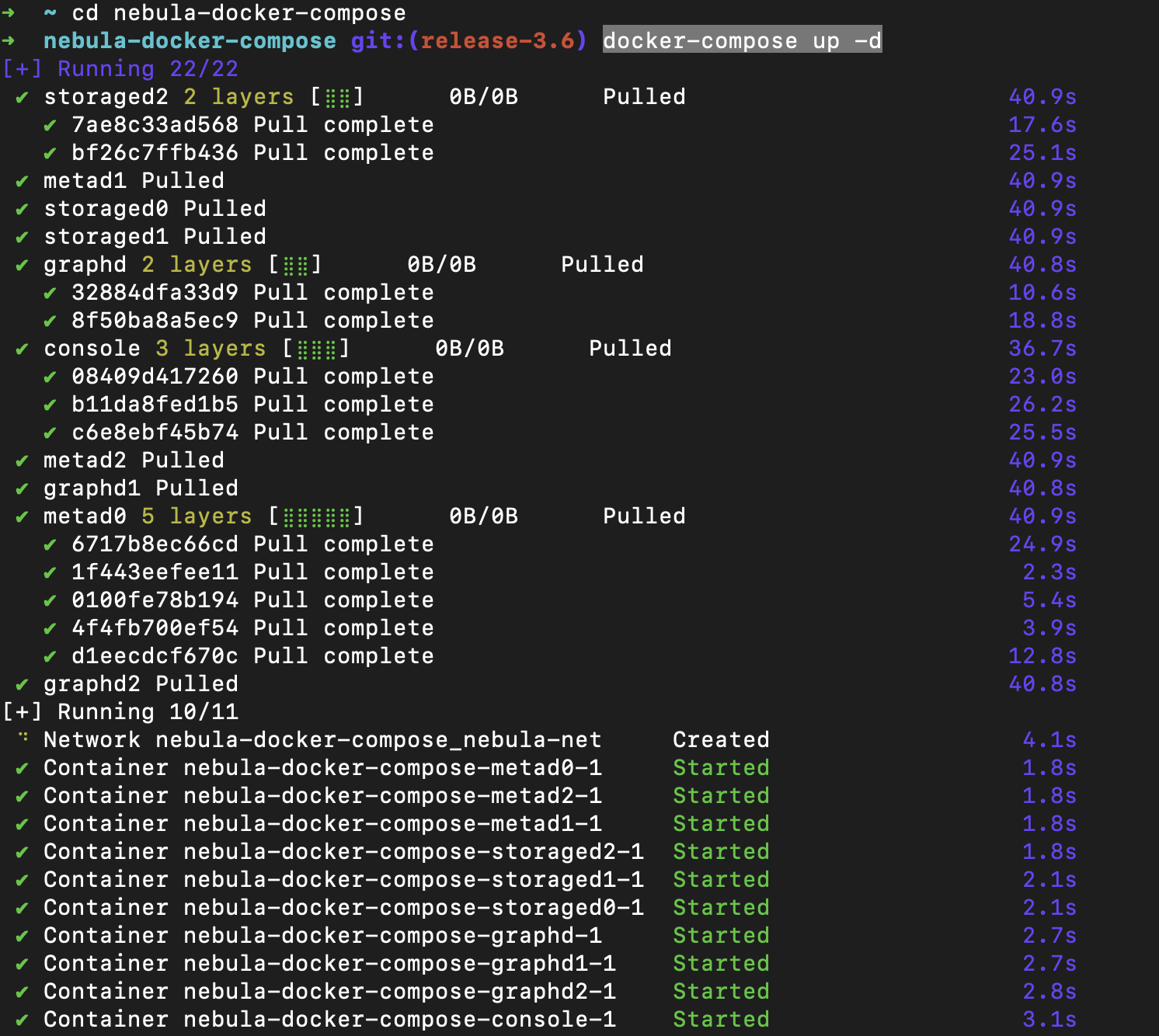
看到上图,说明你的 NebulaGraph 的服务已经启动。
NebulaGraph 服务连接
现在 NebulaGraph 已经启动了,一般来说现在就是连接它,执行什么 SQL boy 的日常 CRUD 操作——往数据库里加点数据、做些查询。
先前,我们提到了 NebulaGraph Studio 和 NebulaGraph Explorer 你可以理解是一个 Web 客户端,我们会用浏览器来连接 NebulaGraph。作为一个附加学习,下面是通过 nebula-console 来连接 NebulaGraph。
还是在之前那个执行了 docker-compose up -d 的 terminal,用命令 docker-compose ps 看下目前 Docker 中服务名:
nebula-docker-compose git:(release-3.6) docker-compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
nebula-docker-compose-console-1 docker.io/vesoft/nebula-console:v3.5 "sh -c 'for i in `se…" console 44 seconds ago Up 40 seconds
nebula-docker-compose-graphd-1 docker.io/vesoft/nebula-graphd:v3.6.0 "/usr/local/nebula/b…" graphd 44 seconds ago Up 41 seconds (healthy) 0.0.0.0:9669->9669/tcp, 0.0.0.0:55153->19669/tcp, 0.0.0.0:55154->19670/tcp
nebula-docker-compose-graphd1-1 docker.io/vesoft/nebula-graphd:v3.6.0 "/usr/local/nebula/b…" graphd1 44 seconds ago Up 41 seconds (healthy) 0.0.0.0:55152->9669/tcp, 0.0.0.0:55150->19669/tcp, 0.0.0.0:55151->19670/tcp
nebula-docker-compose-graphd2-1 docker.io/vesoft/nebula-graphd:v3.6.0 "/usr/local/nebula/b…" graphd2 44 seconds ago Up 41 seconds (healthy) 0.0.0.0:55157->9669/tcp, 0.0.0.0:55155->19669/tcp, 0.0.0.0:55156->19670/tcp
nebula-docker-compose-metad0-1 docker.io/vesoft/nebula-metad:v3.6.0 "/usr/local/nebula/b…" metad0 44 seconds ago Up 43 seconds (healthy) 9560/tcp, 0.0.0.0:55131->9559/tcp, 0.0.0.0:55132->19559/tcp, 0.0.0.0:55133->19560/tcp
nebula-docker-compose-metad1-1 docker.io/vesoft/nebula-metad:v3.6.0 "/usr/local/nebula/b…" metad1 44 seconds ago Up 43 seconds (healthy) 9560/tcp, 0.0.0.0:55130->9559/tcp, 0.0.0.0:55128->19559/tcp, 0.0.0.0:55129->19560/tcp
nebula-docker-compose-metad2-1 docker.io/vesoft/nebula-metad:v3.6.0 "/usr/local/nebula/b…" metad2 44 seconds ago Up 43 seconds (healthy) 9560/tcp, 0.0.0.0:55136->9559/tcp, 0.0.0.0:55134->19559/tcp, 0.0.0.0:55135->19560/tcp
nebula-docker-compose-storaged0-1 docker.io/vesoft/nebula-storaged:v3.6.0 "/usr/local/nebula/b…" storaged0 44 seconds ago Up 42 seconds (health: starting) 9777-9778/tcp, 9780/tcp, 0.0.0.0:55140->9779/tcp, 0.0.0.0:55141->19779/tcp, 0.0.0.0:55142->19780/tcp
nebula-docker-compose-storaged1-1 docker.io/vesoft/nebula-storaged:v3.6.0 "/usr/local/nebula/b…" storaged1 44 seconds ago Up 42 seconds (health: starting) 9777-9778/tcp, 9780/tcp, 0.0.0.0:55144->9779/tcp, 0.0.0.0:55145->19779/tcp, 0.0.0.0:55143->19780/tcp
nebula-docker-compose-storaged2-1 docker.io/vesoft/nebula-storaged:v3.6.0 "/usr/local/nebula/b…" storaged2 44 seconds ago Up 42 seconds (health: starting) 9777-9778/tcp, 9780/tcp, 0.0.0.0:55139->9779/tcp, 0.0.0.0:55137->19779/tcp, 0.0.0.0:55138->19780/tcp
这里要注意 nebula-console 这个镜像对应的服务名 nebula-docker-compose-console-1,用 nebula-console 连接 NebulaGraph 时需要用到它。
在 terminal 继续执行命令 docker exec -it nebula-docker-compose-console-1 /bin/sh,此时终端需要你输入 NebulaGraph 的账号、密码信息:
./usr/local/bin/nebula-console -u root -p nebula1234 --address=graphd --port=9669
在本文示例中设定账号 -u 为 root,密码 -p 为 nebula1234。你可以根据自己的喜好,修改为你记得住的密码。而上面语句的地址 --address 和端口 --port 直接用默认的 graphd 和 9669 即可。
等你通过账号和密码连接上 nebula-console 之后,你便可以进行相关的数据库操作,比如:你可以看下相关的服务状态。
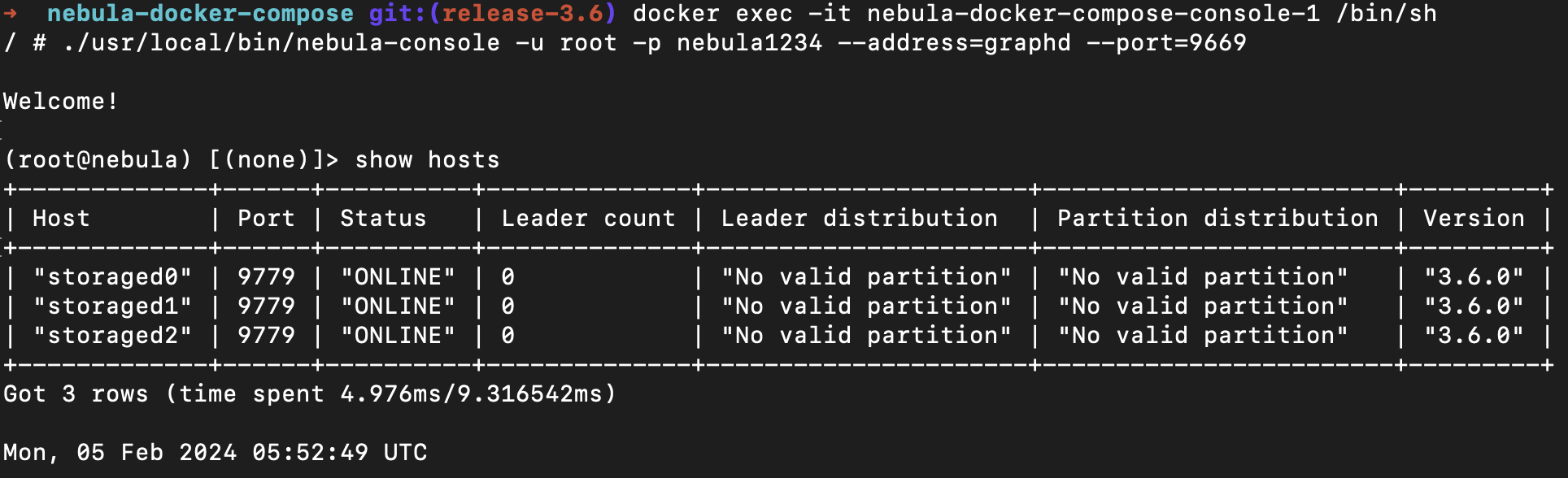
可视化工具 NebulaGraph Studio 部署
还是根据文档:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/deploy-connect/st-ug-deploy/#docker_studio 走下。
先下载 nebula-studio 的 tar 包:3.8.0 版本,将下载的包放到你的 nebula-docker-compose 文件所在的目录下。
terminal 在 nebula-docker-compose 目录的情况下,执行下面的命令、打开对应的 tar 包:
mkdir nebula-graph-studio-3.8.0 && tar -zxvf nebula-graph-studio-3.8.0.tar.gz -C nebula-graph-studio-3.8.0

将 terminla 的目录切到 nebula-graph-studio-3.8.0 这个目录下:
cd nebula-graph-studio-3.8.0
如果你查看过 nebula-graph-studio-3.8.0 里的内容,里面就一个 .yaml 文件和说明文档,那如何搞到 nebula-studio 的镜像呢?下面的命令就是拉取相关的 nebula-studio:
docker-compose pull
现在看下上面命令的执行结果:

现在,我们来启动下 nebula-studio 服务:在刚才的 terminla 执行下面的命令
docker-compose up -d
看到下面的 nebula-graph-studio-380-web-1 已经是状态为 Started(绿色),

我们可以在浏览器终端打开 127.0.0.1:7001 访问 nebula-stuido:

在 graphd 部分填入你本机真实 IP,账号和密码可输入:root / nebula。至此,恭喜你已经有了玩转图数据库的环境。
10 秒搞定部署安装
刚我们搞了 Docker 的 NebulaGraph、NebulaGraph Studio 的部署安装,这里有一键完成之前的捷径。
前提,你得装好 Docker Desktop。打开 Docker,看到界面左侧的菜单栏有“Extension”:
添加扩展之后,在搜索框里输入:Nebula 便能找到对应的 NebulaGraph 扩展:
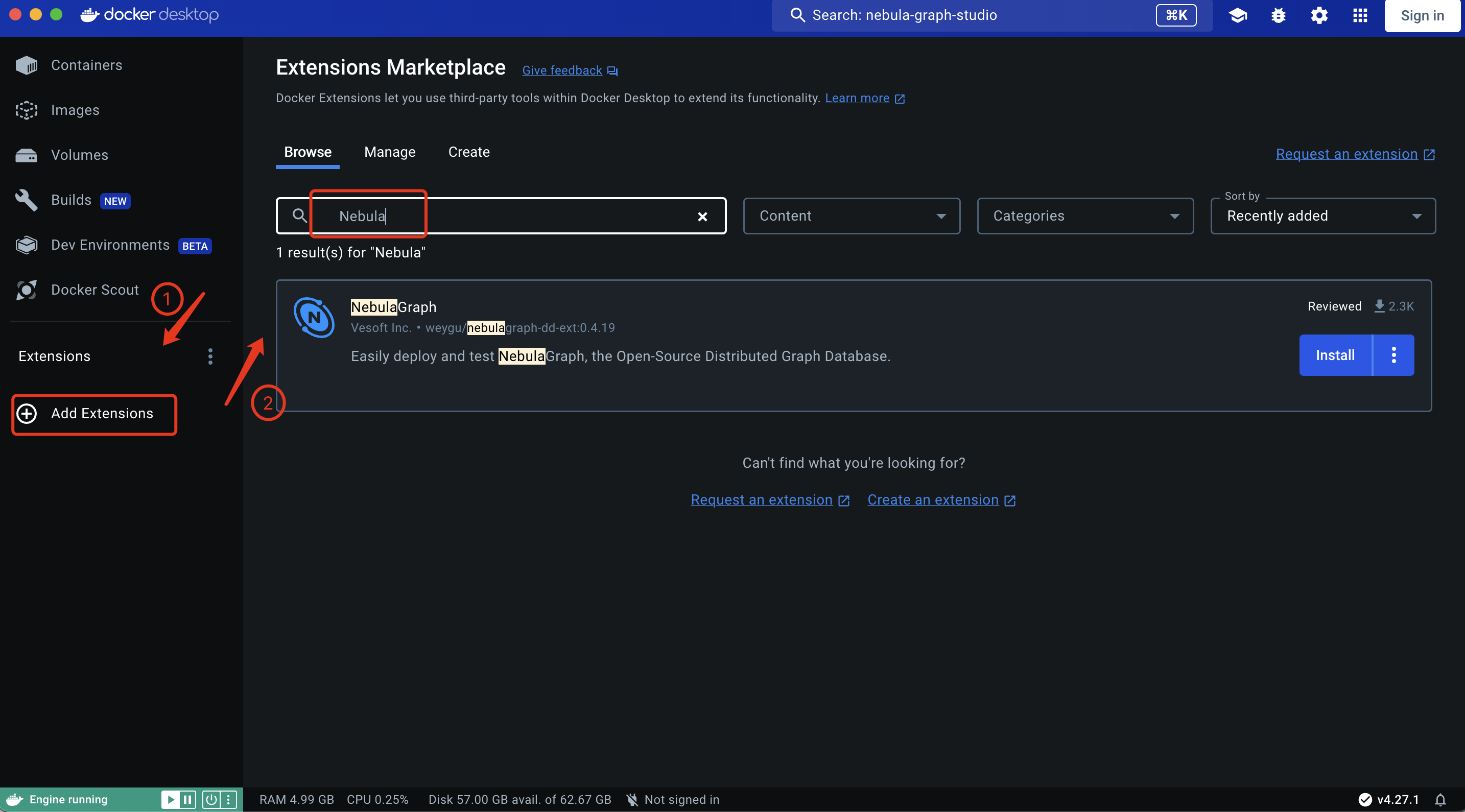
点击安装之后,你便能看到 NebulaGraph Extension 已经安装在你的 Docker Desktop 里。点击【Studio】:
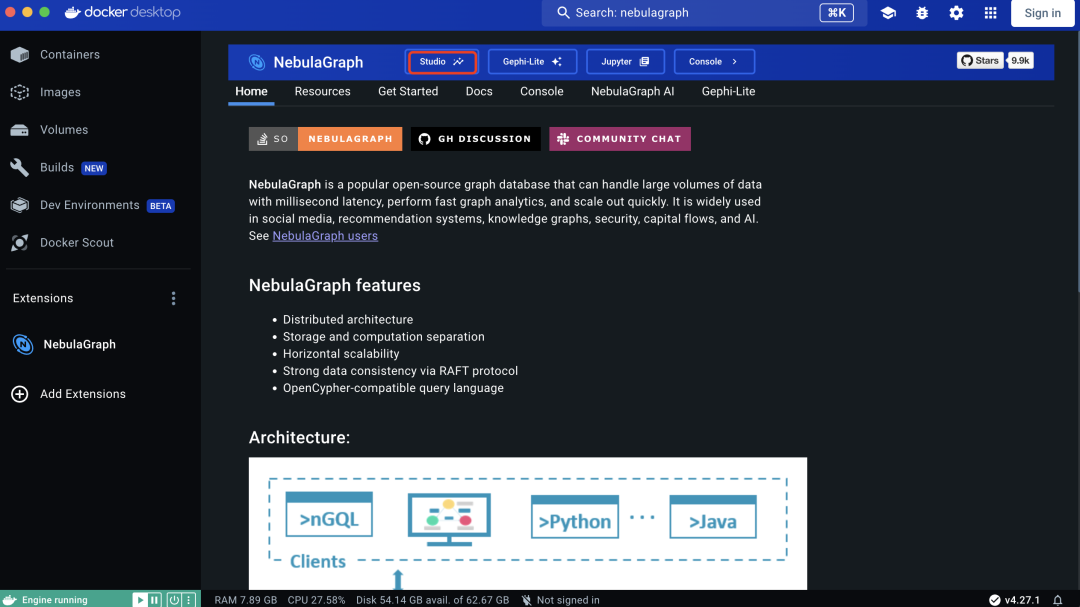
好的 nebula-studio 服务启动 🎉,再填入相关的信息:graphd /9669,以及账号和密码:root / nebula,完成登陆。
绿色通道
下面带大家走一趟阿里云计算巢,薅一个付费的企业服务。(注意:填写完信息之后,需要审核,审核结果将会以短信形式发送给你)
先访问:https://market.aliyun.com/isv-nebulagraph,打开 NebulaGraph 企业版使用界面:
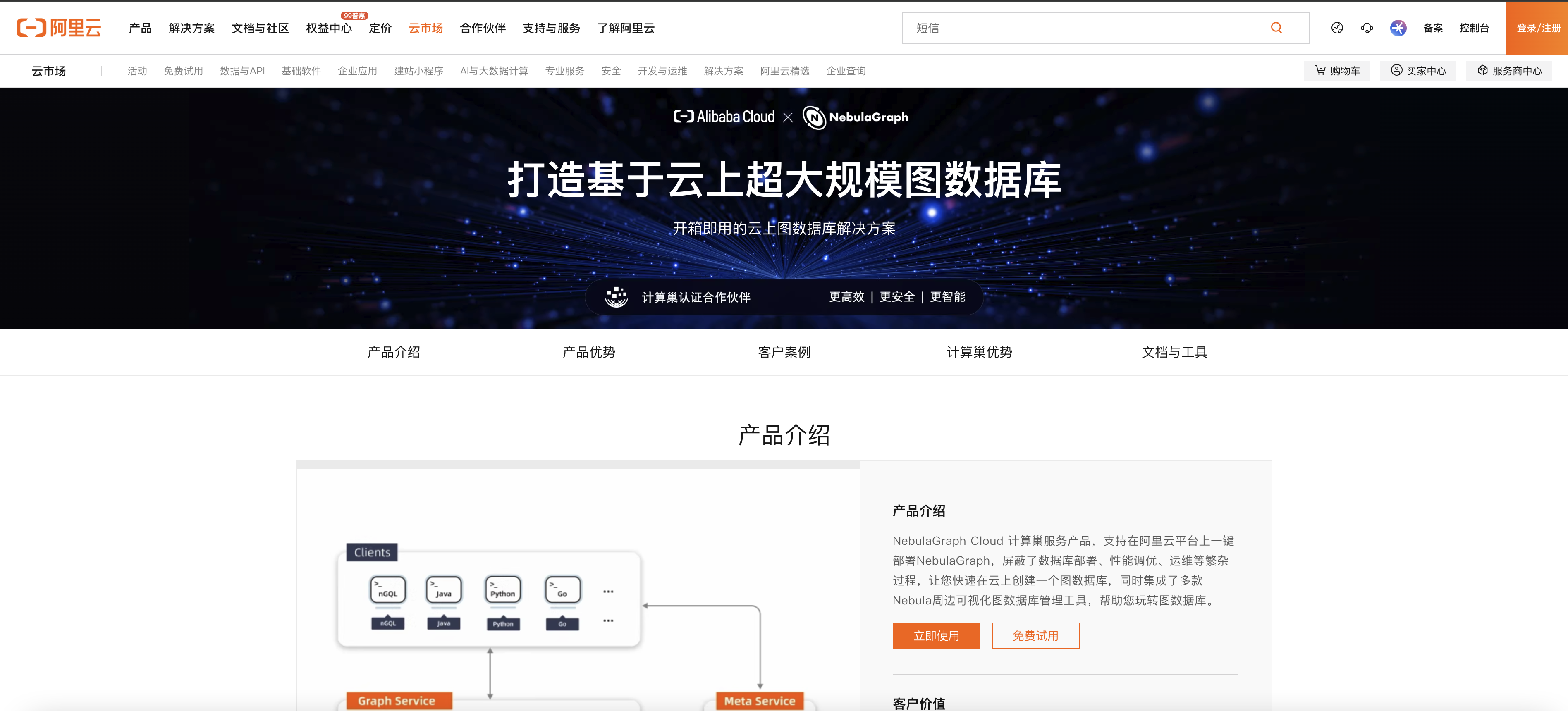
登录之后,点击页面上方的【立即使用】,填写下相关的信息:
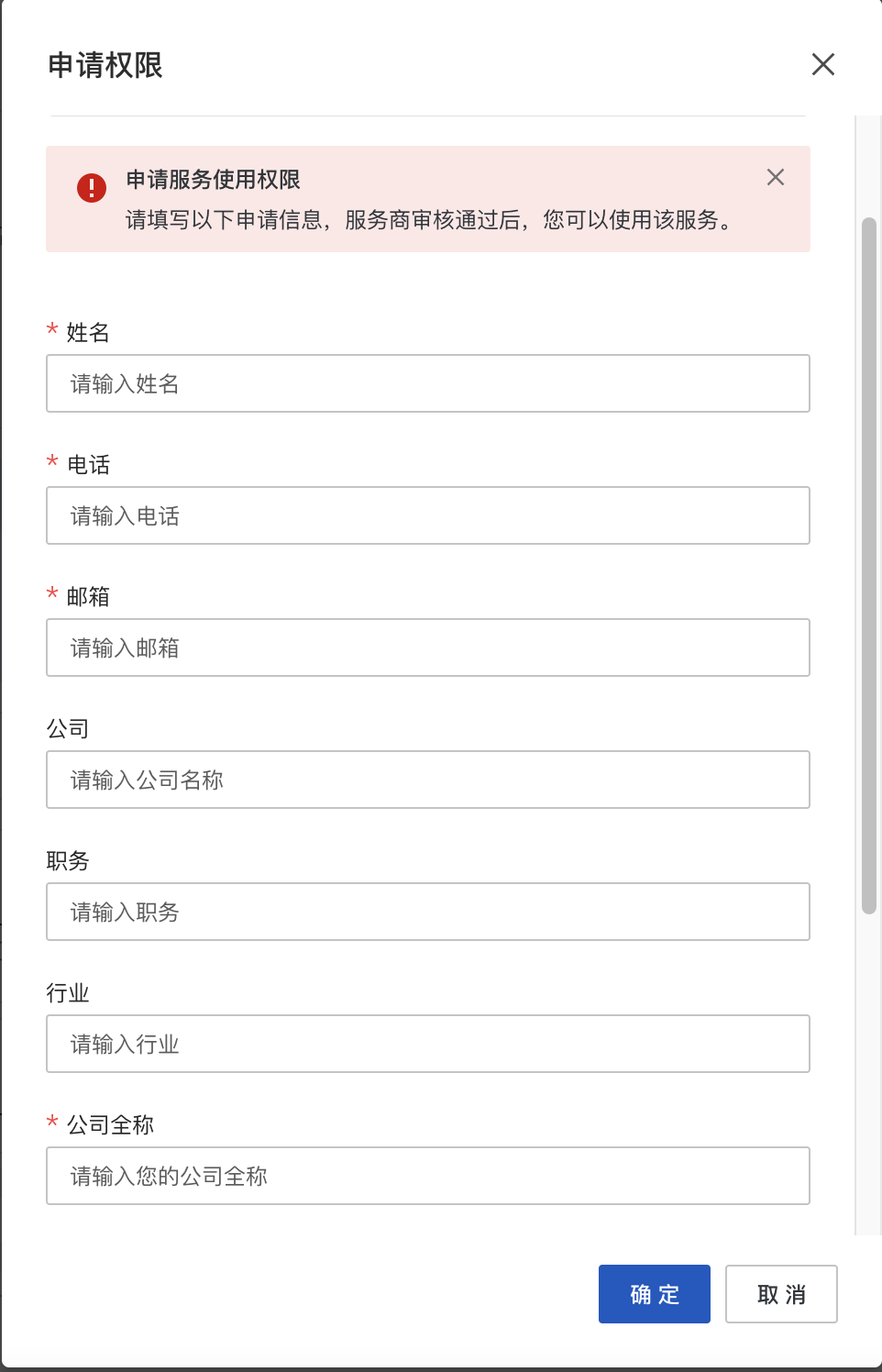
正常情况下,这是需要审核的:一般是 3 个工作日。不过,这次我们已经打点妥当直接提交信息之后自动审批。等你填完信息之后,前往计算巢服务页面:https://computenest.console.aliyun.com/service/cn-hangzhou?tabKey=used,在我的服务中找到【我使用的服务】,同下图:
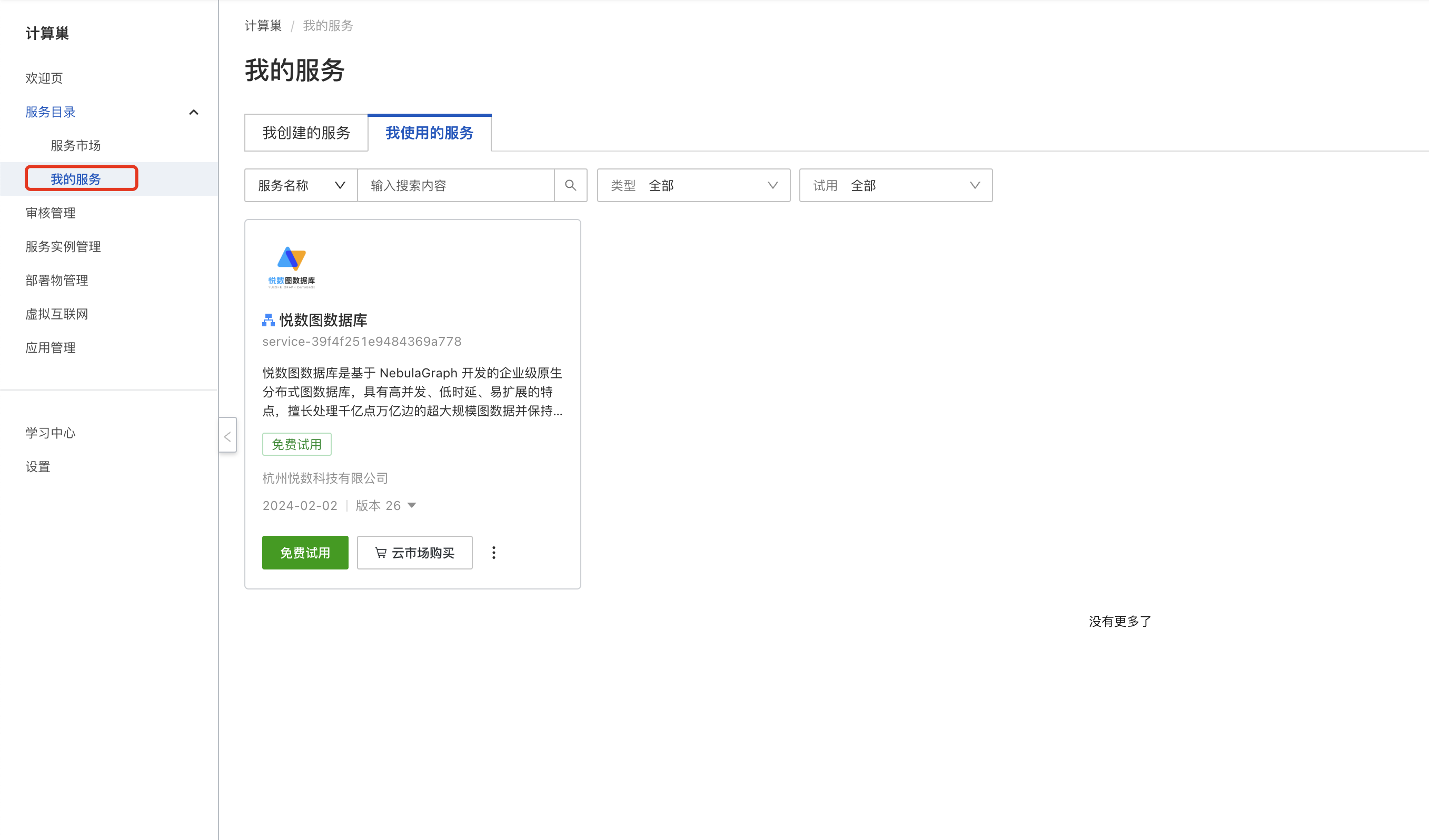
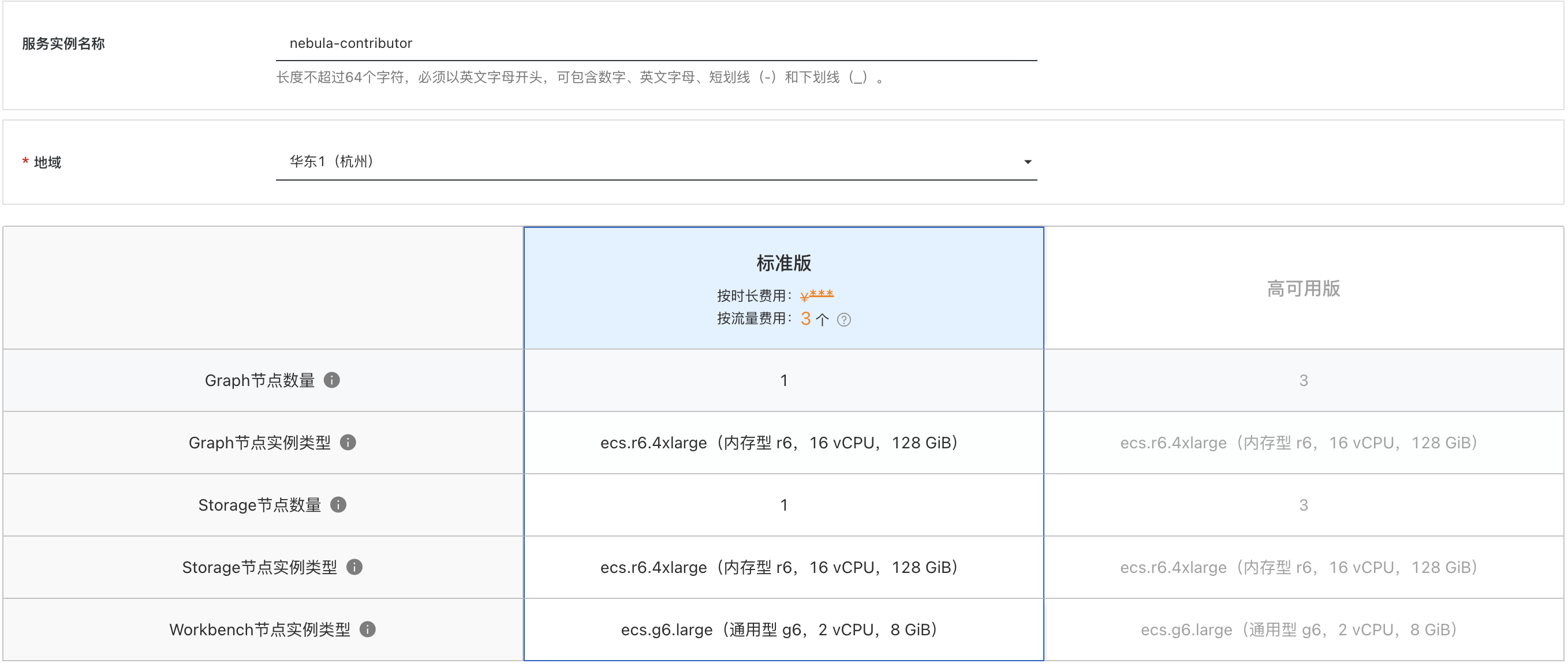
我们现在开始创建 30 天的免费企业版 NebulaGraph,遇到需要填写的地方填写下,已经自动填充默认值的地方直接跳过,毕竟我们是白嫖的企业服务——没有啥可以选择的余地。
下面是需要填写的信息:
- 服务实例名称:随便取个你喜欢的名字;
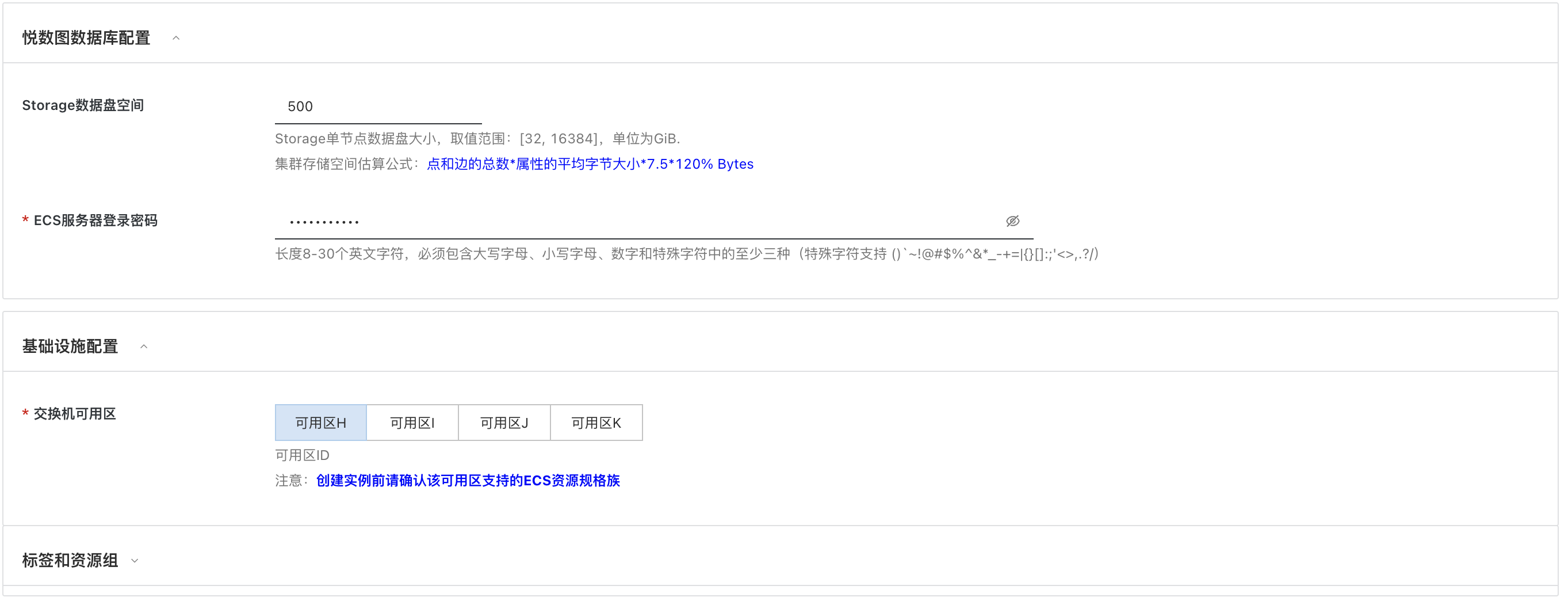
- Storage 数据盘空间:随便填个大于 32 小于 16384 的值,这里我填了 500;
- ECS服务器密码:填个你记得住的密码;
- 交换机可用区:选择默认的第一个可用区;
再勾选下 2 个协议,之后提交下信息:
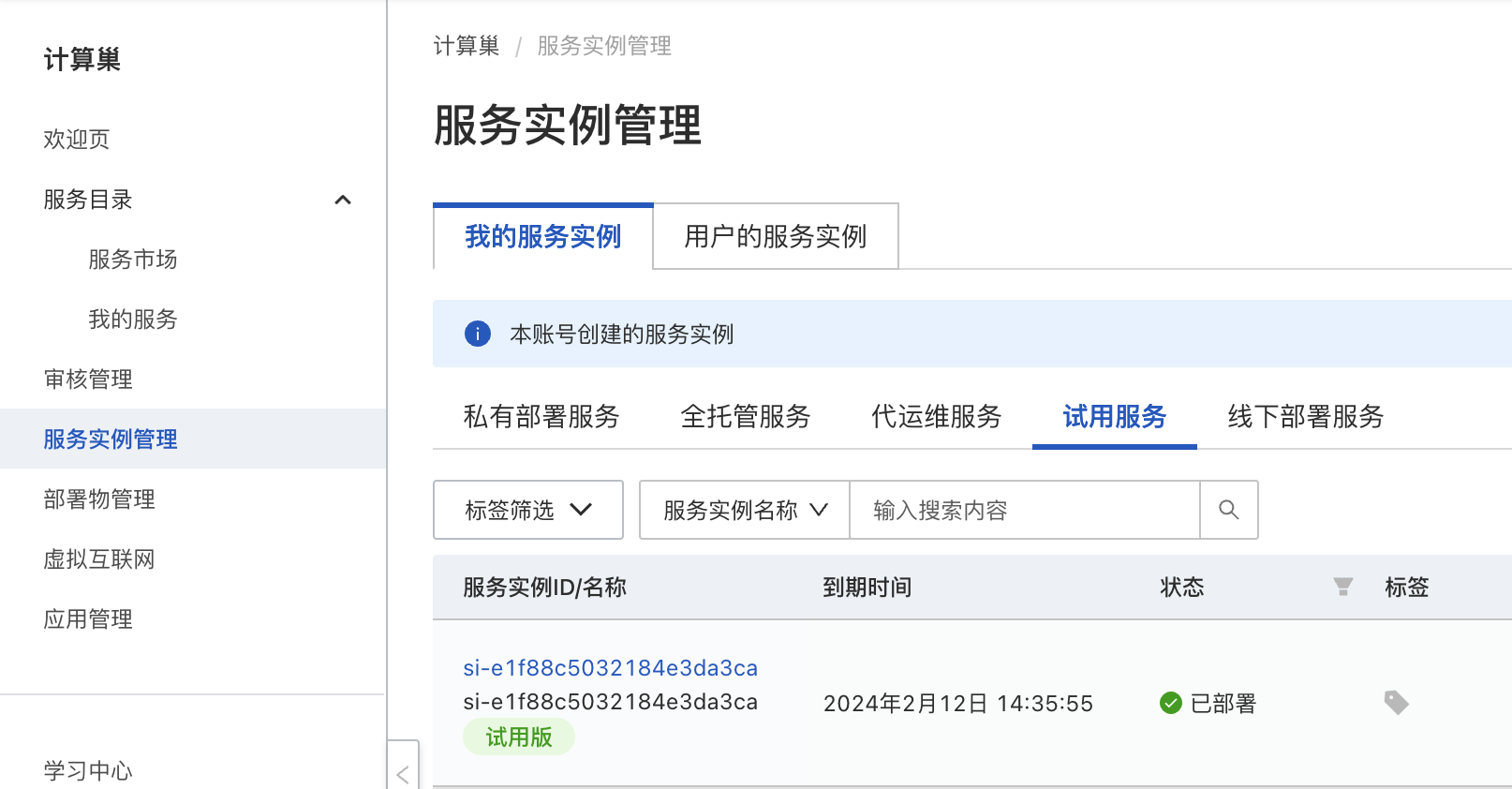
现在你有了一个 30 天的企业版 NebulaGraph 服务。我们现在去找到它,它还附带了一个企业版可视化工具 NebulaGraph Explorer。前往服务实例页面:https://computenest.console.aliyun.com/service/instance/cn-hangzhou?secondTabKey=poc 在我的【试用服务】服务中找到刚才创建的实例:
往右拉动滚动条,看到该实例的详情,点击【详情】。可以看到对应的实例信息,包括在线可视化探索工具 nebula-explorer 的在线地址:
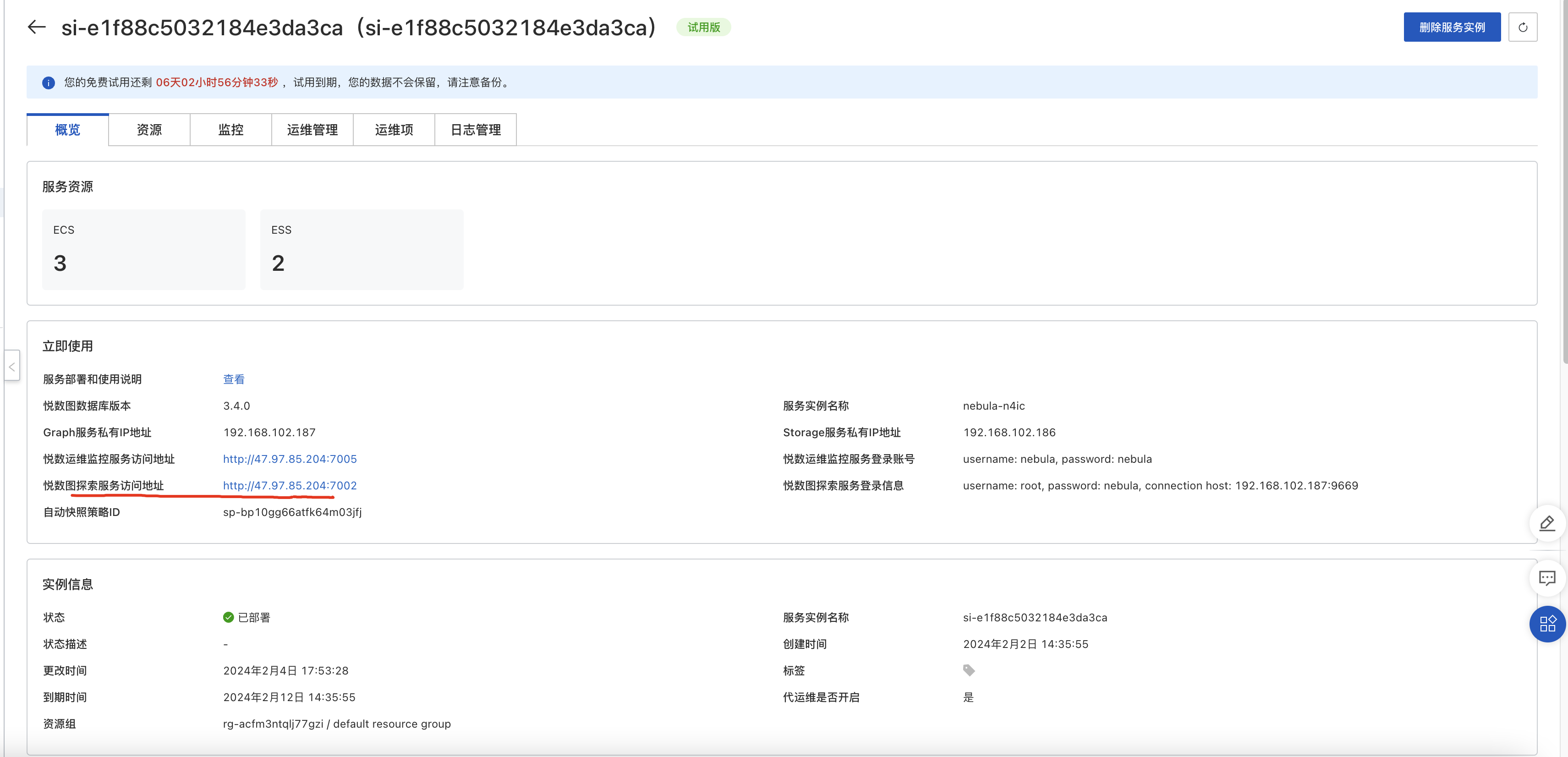
点击 nebula-explorer 的在线地址,就能打开 explorer,填入详情中 graph 服务私有 IP 对应的 ip,以及详情提到的图探索服务登陆信息中的账号和密码。
至此,你已经可以正常使用可视化图探索工具来探索 NebulaGraph 了。
下面,开始我们的主菜:探索图数据库。因为 nebula-studio 有较多相似,又不少不同的地方。下面内容无特殊说明,说明二者通用。
探索图数据库
草图构建 Schema
草图功能是 nebula-explorer 先有,后来再添加到 nebula-studio 的功能。由奢入俭难,我们从比较朴素的开源的 nebula-studio 为例。
登陆 nebula-studio 之后,在页面上左上方导航处选中【Schema 草图】,nebula-explorer 对应的功能在页面右侧、从左往右数第一个图标。
下面这个是我们本次实践的图模型(社区的 contributor 关系图):
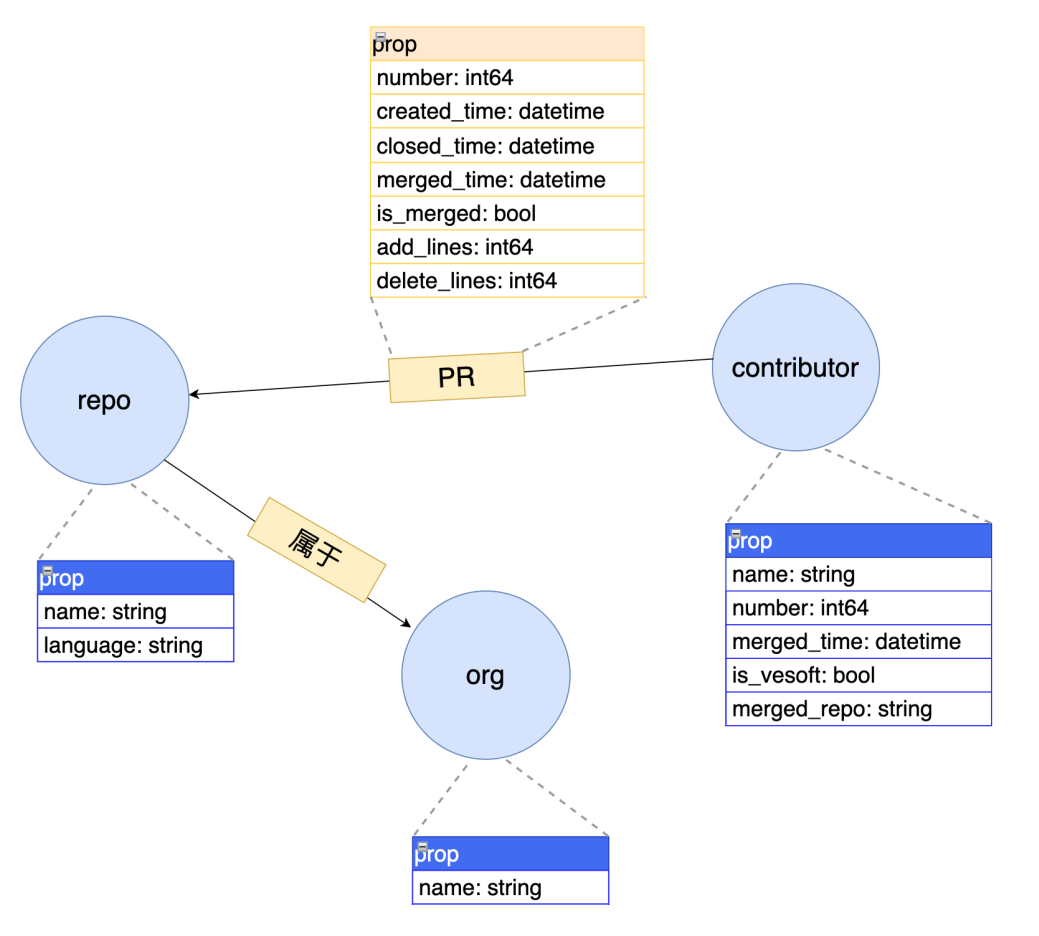
OK,根据这个图模型上面的 Schema 信息,我们在草图中创建下相关的点(圆圈)和边(一个圆指向另外个圆的连接线)信息:
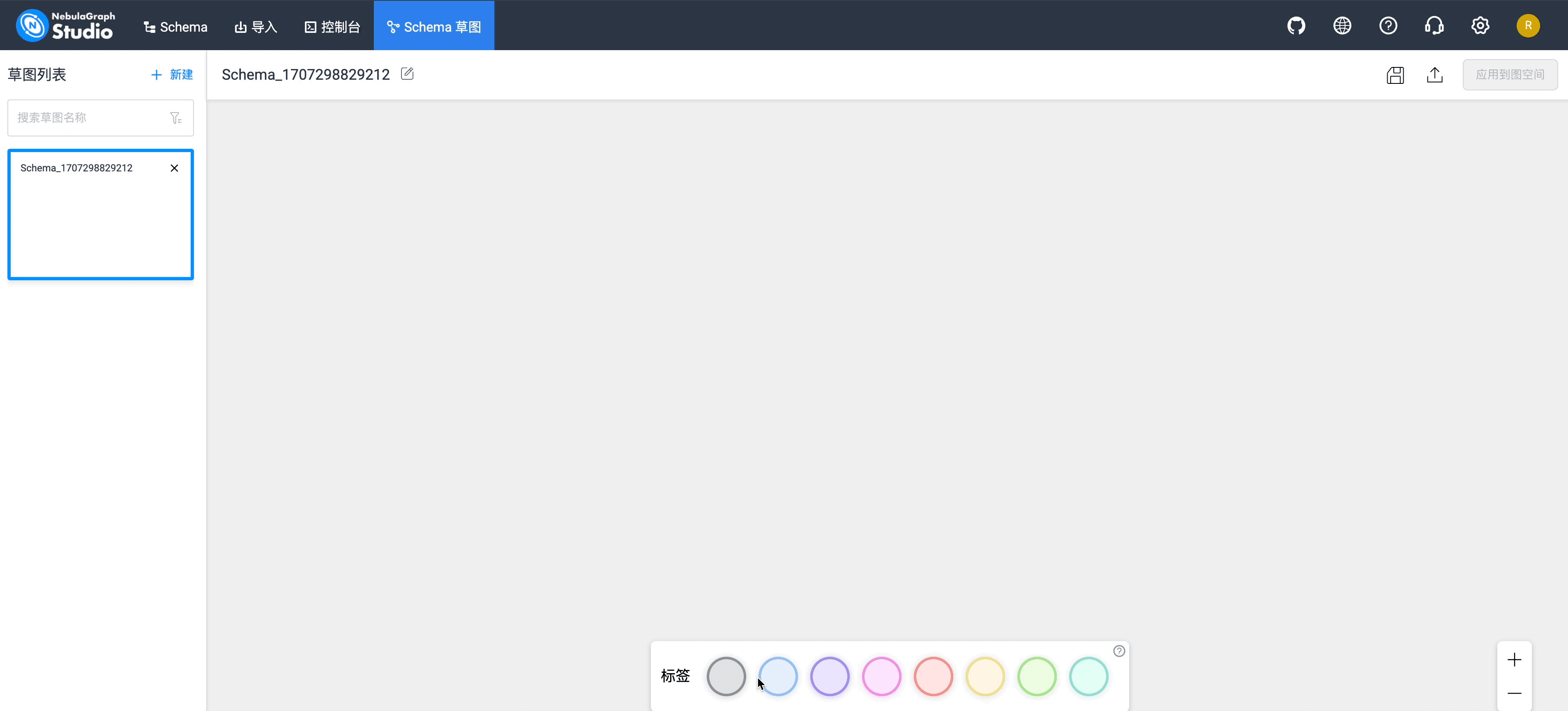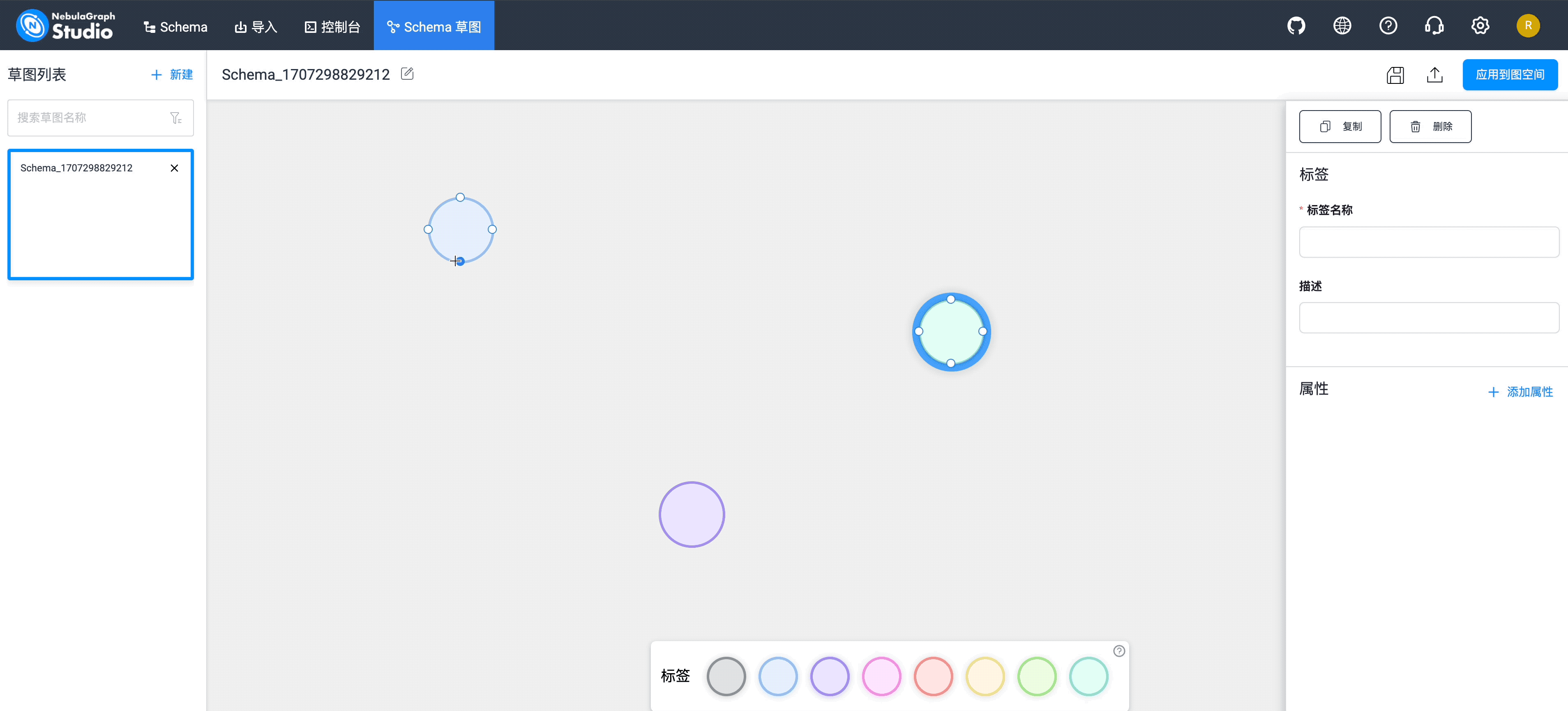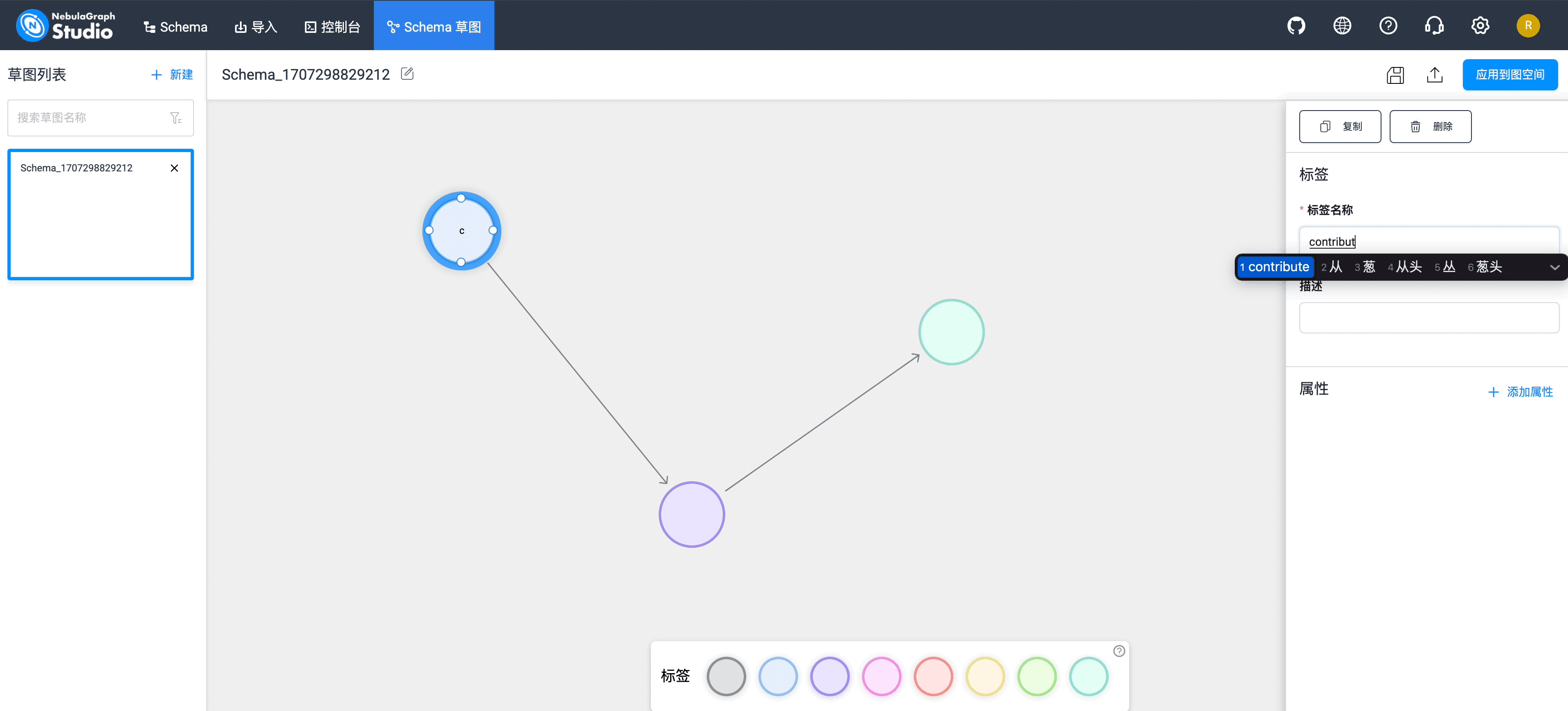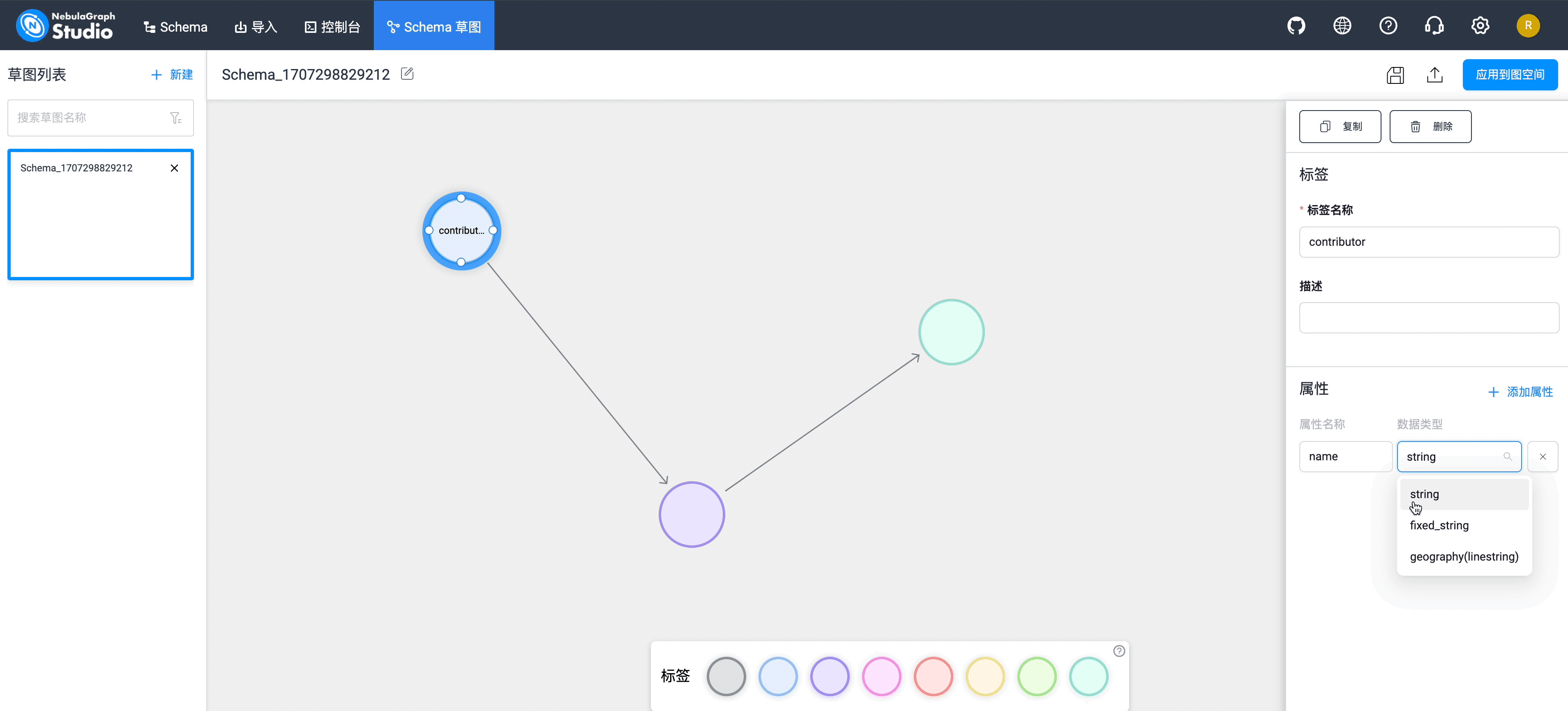
将 repo、contributor、org 等 3 个 tag 类型信息,以及 PR、属于 等 2 个 edgetype 类型提交之后,你可以在页面到对应的 Schema 信息。下图以 contributor tag 为例:

点击右上角的保存图标保存之后,应用到图空间——现在,我们要开始创建图空间了:
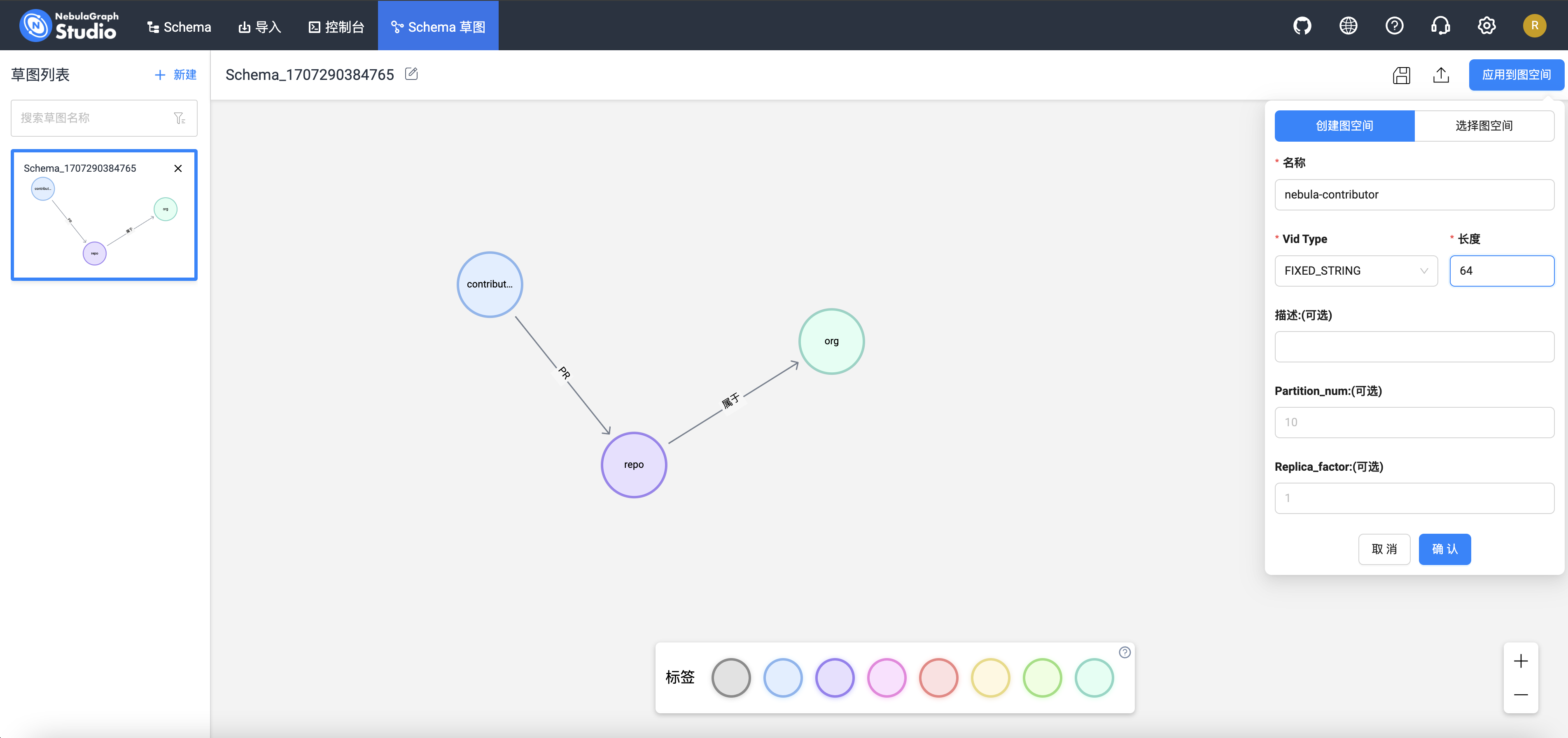
至此,我们的 Schema 信息创建完成。
nebula-studio 的小伙伴可直接点击左侧的菜单的 Schema(nebula-explorer 的小伙伴点击右侧菜单从左往右数第二个图标)查看图空间信息,等你看到 nebula-contributor 之后,点击图空间名,可查看相关的 Schema 信息:
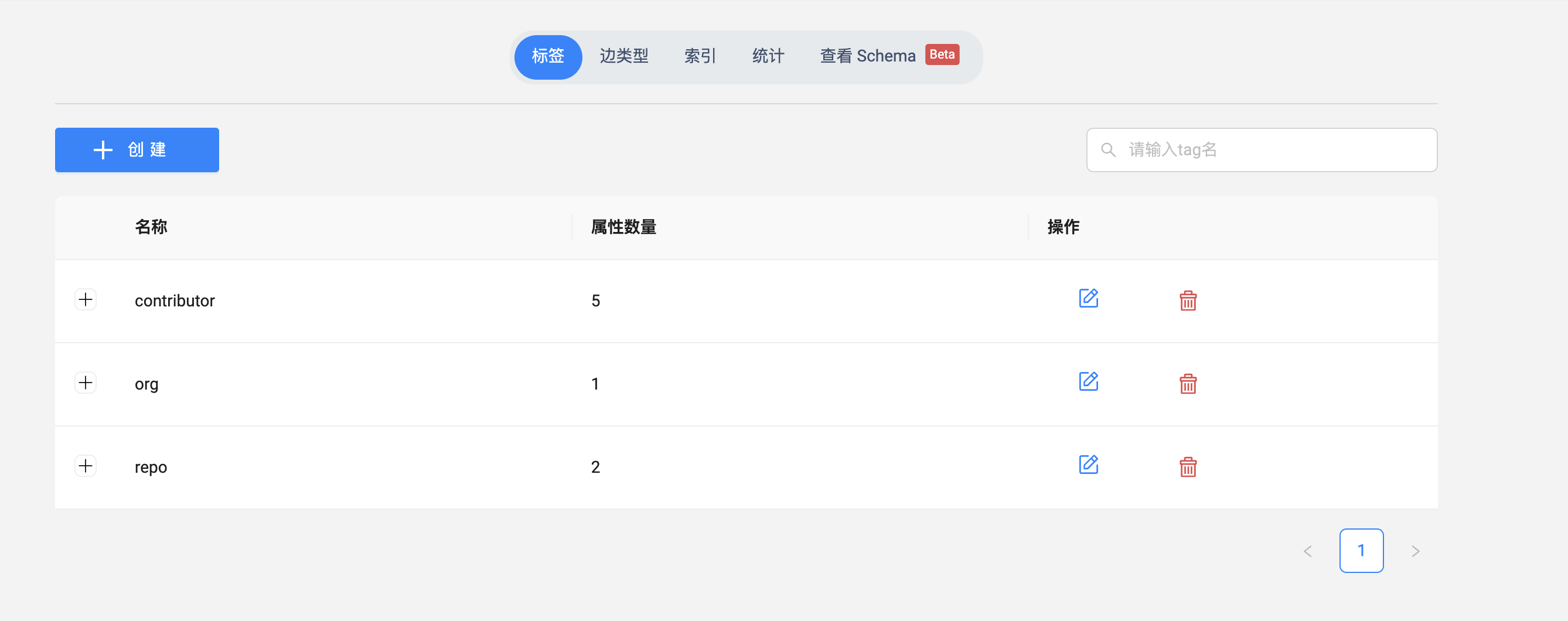
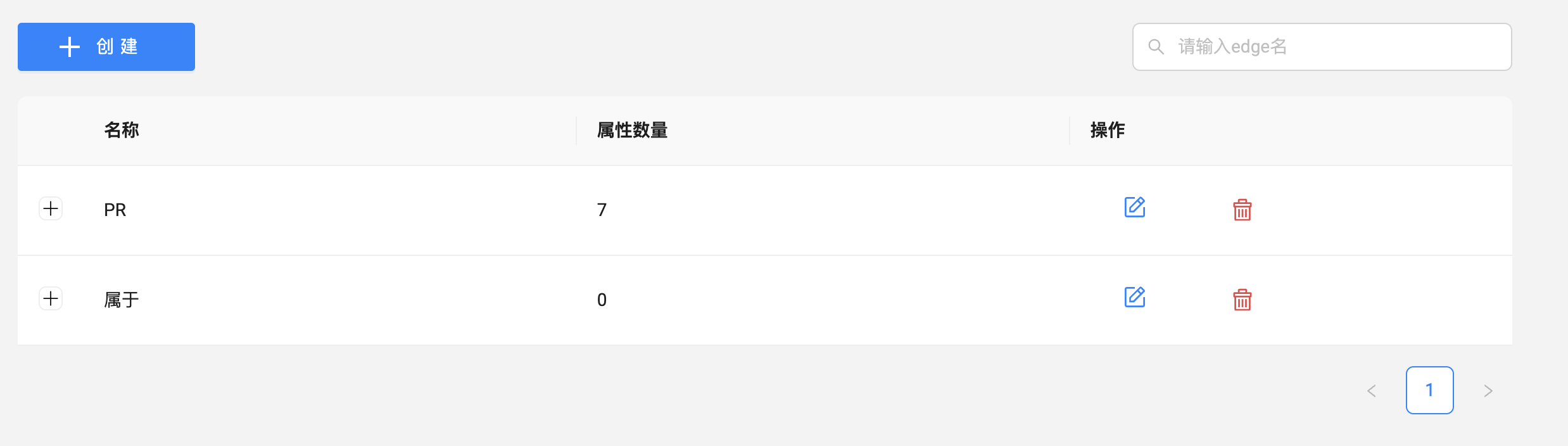
细心的你此时可以对下相关的属性个数。
导入图数据
点击这里把本次用的 nebula-contributor-dataset2024 数据集下载到本地,放在一个你能找到的目录下。
解压缩之后得到 5 个文件:
- tag 点类型数据
- contributor20240110.csv
- repo20240110.csv
- org.csv
- edgetype 边类型数据
- pr20240110.csv
- belong20240110.csv
上面的数据已经经过处理,我们开始导数环节。nebula-studio 和 nebula-explorer 的数据导入流程相似,下面以 nebula-studio 为例:
点击左侧导航的【导入】菜单(nebula-explorer 为右侧第三个图标),进入导数页面之后我们先上传本地文件(支持批量上传),将所有文件上传到 nebula-stuido 中:
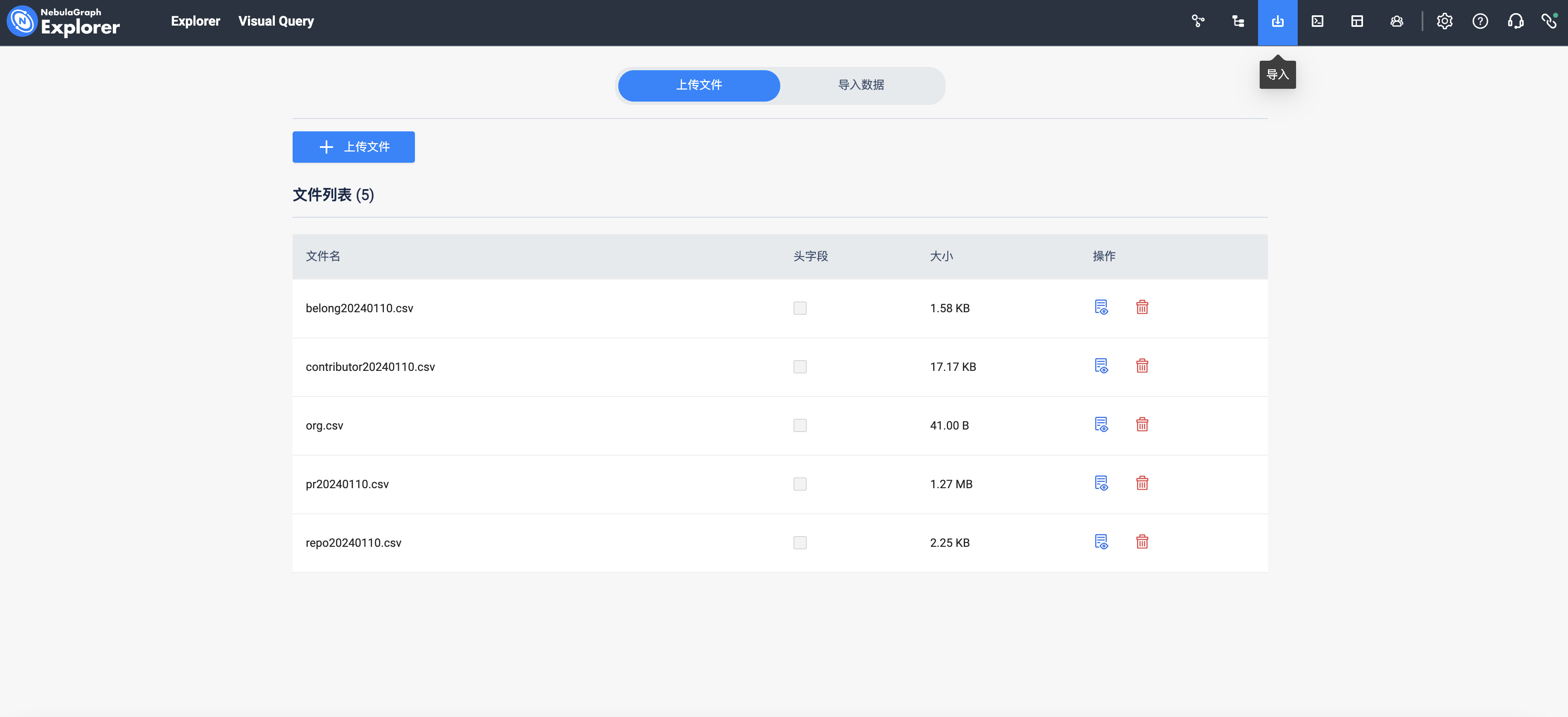
点击同页面右侧的【导入数据】,进行数据和 Schema 关联。
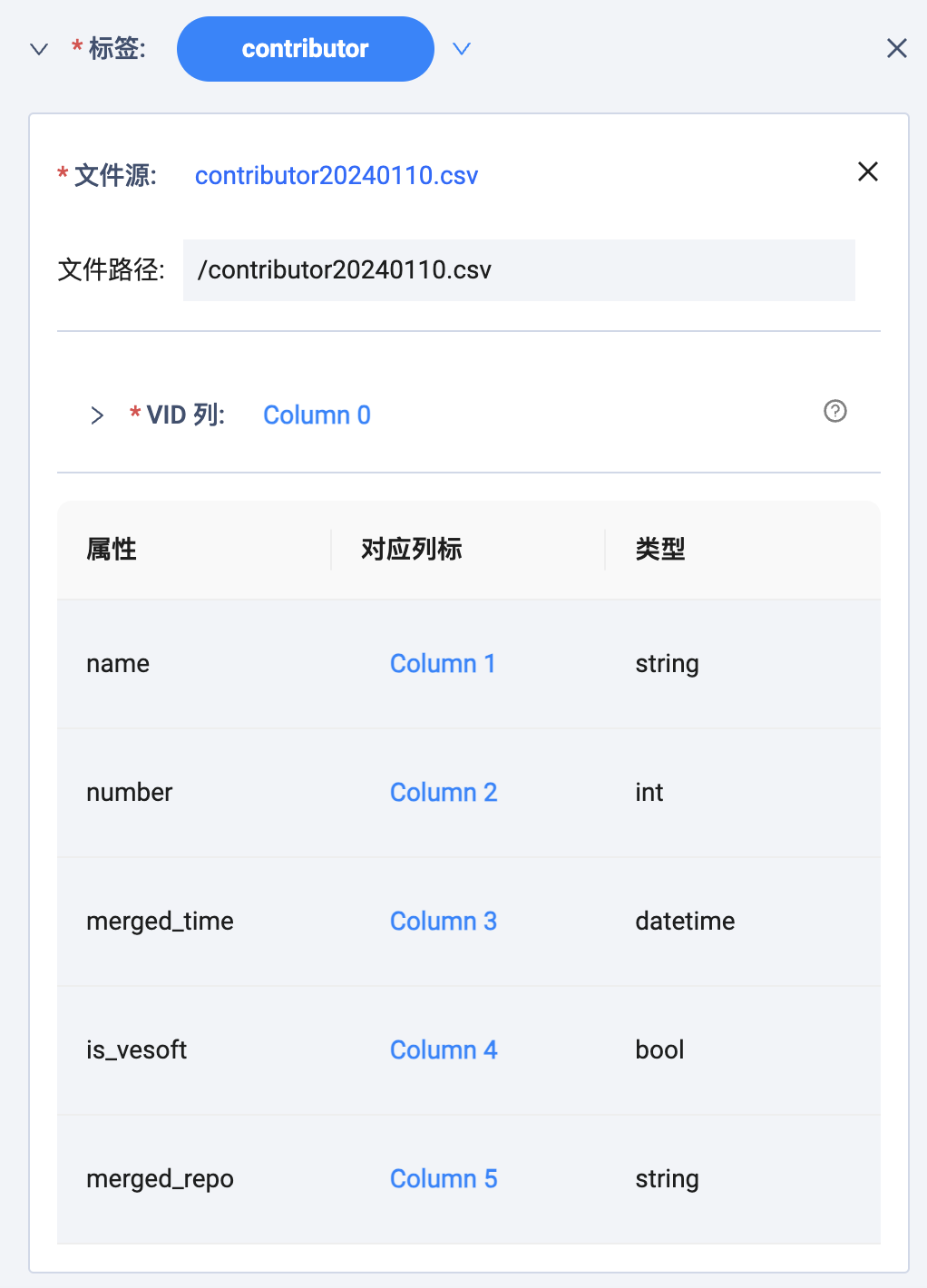
以 contributor tag 为例,将对应的 Schema 属性信息同源数据进行关联:
- 标签:选 contributor
- 关联文件:选【本地】再选择 contributor20240110.csv
- VID 列:选 Column 0
- name:选 Column 1
- number:选 Column 2
- merged_time:选 Column 3
- is_vesoft:选 Column 4
- merge_repo:选 Column 5
聪明的你应该发现了,所有的 Schema 和原数据关联都是顺序的——因为为了方便:
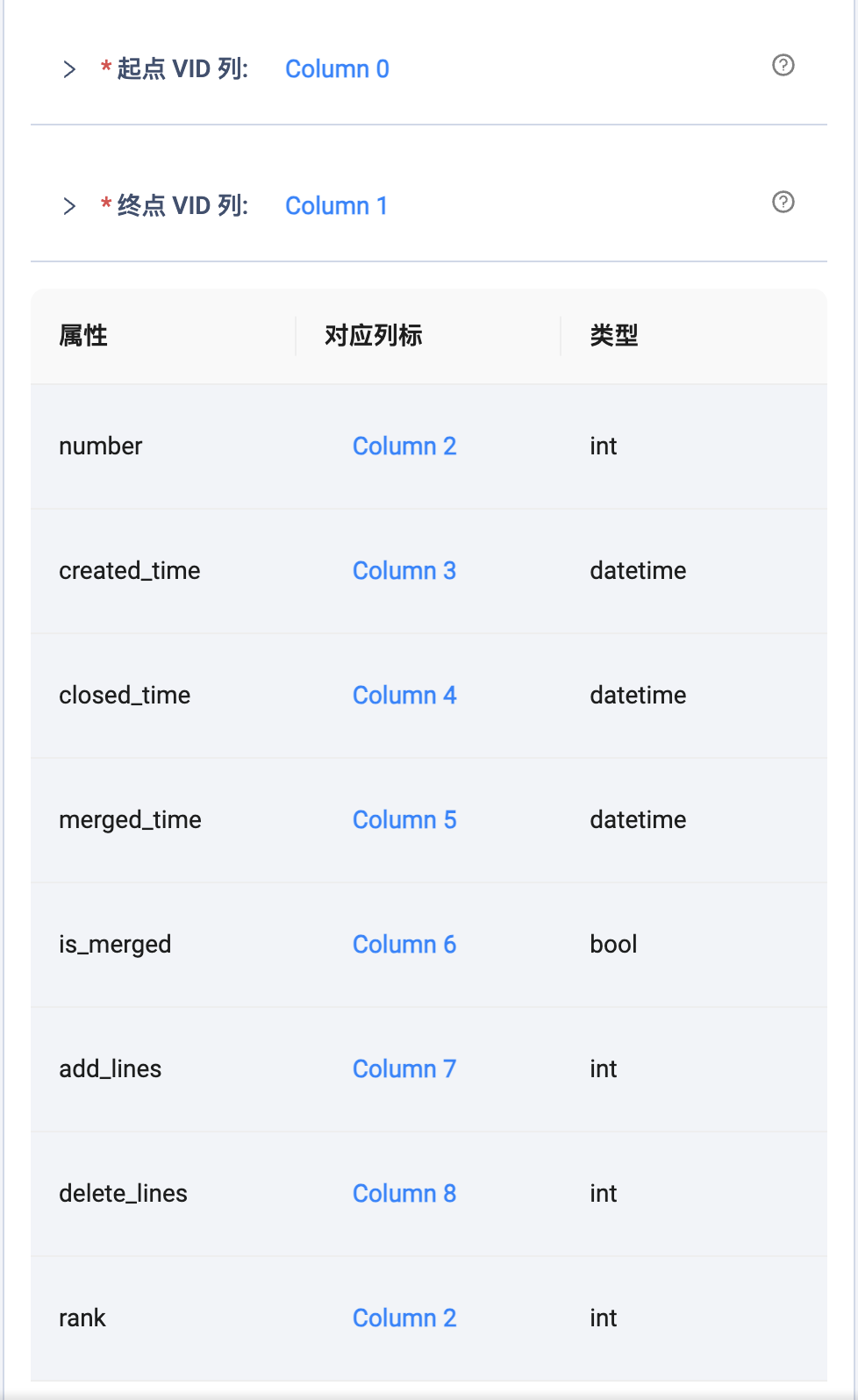
而边的关联稍显复杂,这里做个文字描述:
- 边类型:选 PR
- 关联文件:选【本地】再选择 pr20240110.csv
- 起点 VID 列:选 Column 0
- 终点 VID 列:选 Column 1
- number:选 Column 2
- created_time:选 Column 3
- closed_time:选 Column 4
- merged_time:选 Column 5
- is_merged:选 Column 6
- add_lines:选 Column 7
- delete_lines:选 Column 8
- rank:选 Column 2
参考下图
同理,将其他的 2 个 tag 和 1 个 edgetype 关联之后,点击导入按钮:
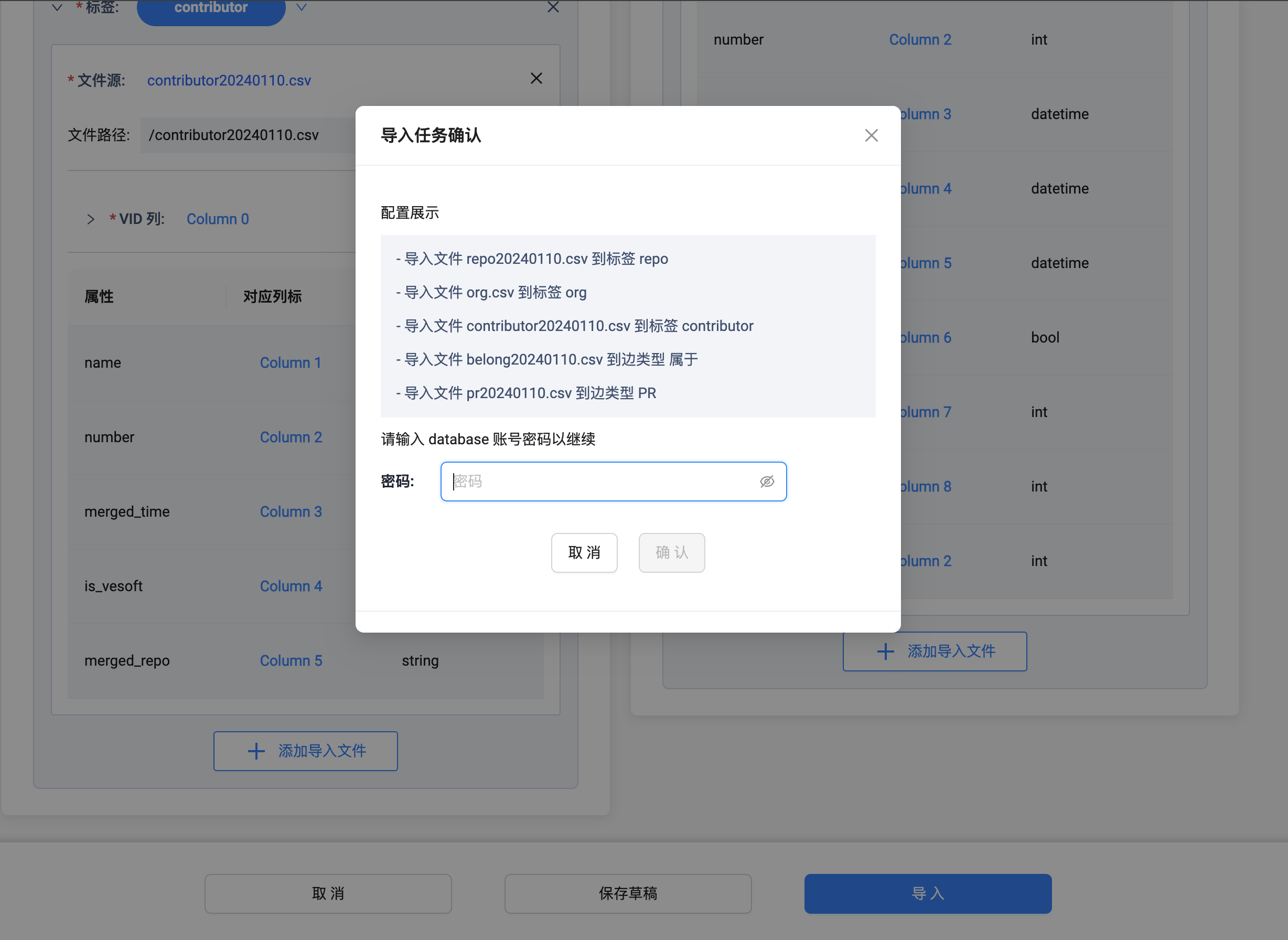
输入你的 NebulaGraph 服务密码(nebula)。等待数据导入…
等导入任务完成之后,我们去 Schema 页面看下数据【统计】点击下【更新】按钮:
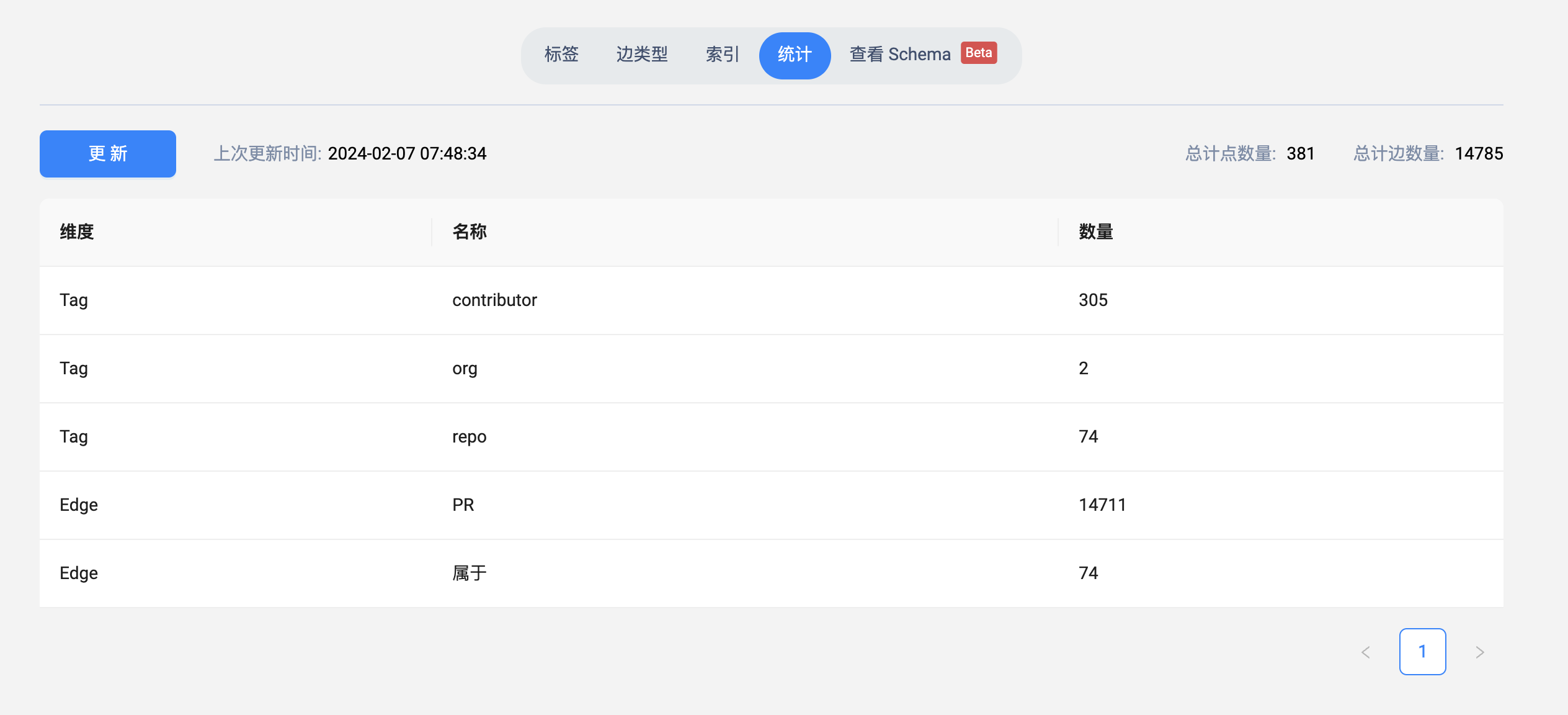
如果你的数据和我的数据相同,说明你已经成功了,我们开始探索图数据库。
探索图数据
现在,我们开始探索下刚导入进去的数据。探索数据之前,我们先创建几个索引来检索数据:
依旧是 Schema 页面,进入图空间之后,看到【索引】选项,我们需要创建几个索引:
- 标签索引
- contributor 它的属性 is_vesoft 为索引
- org 索引,可不选属性
- repo 它的属性 name 为索引
- 边类型索引
- belong 索引,因为它本身就没有属性,直接创建边索引即可
- PR 的 closed_time 属性索引
- PR 的 is_merged 属性索引
等我们创建完所有索引之后,对所有的索引进行【重建索引】。记得所有都得重建完成哦~~
准备工作做完,我们开始探索数据。
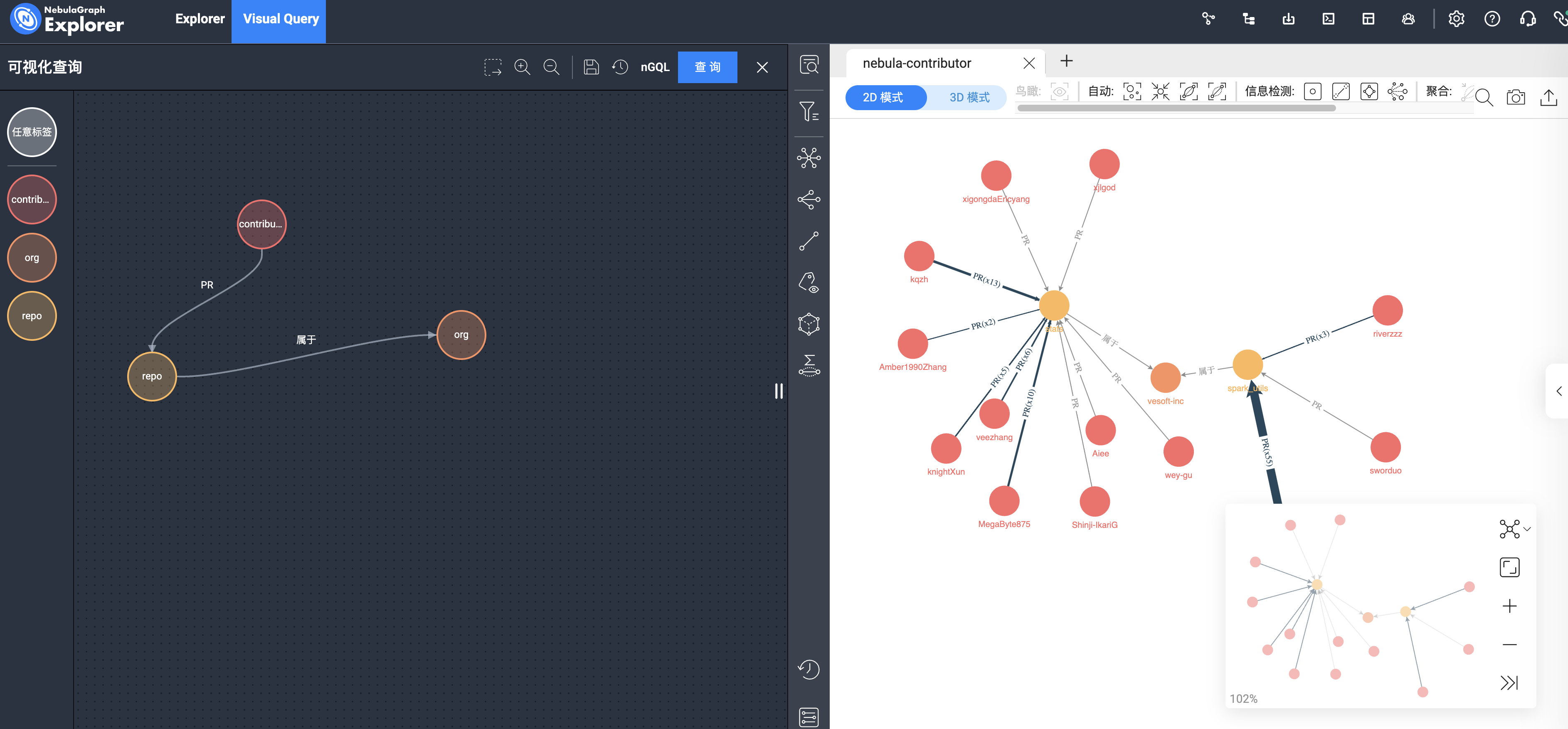
如果你是尊贵的企业版用户(绿色通道用户),我们直接用 nebula-explorer 的可视化探索(Visual Query),和草图类似:把 3 个 tag 拖出来,通过边进行链接,在边上选中边类型,像下图这样:
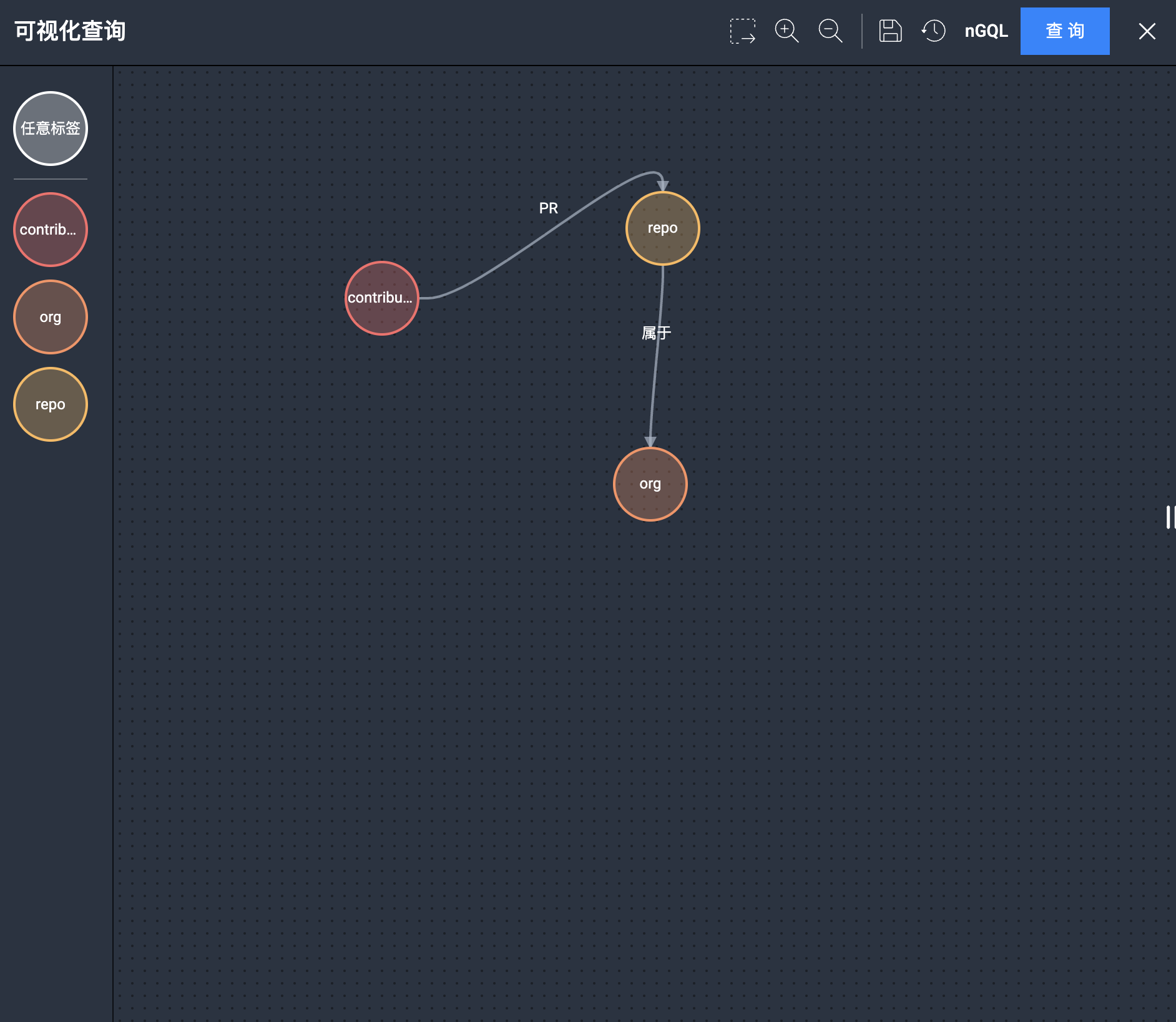
点击右上角的【查询】,你就可以看到相关数据了:
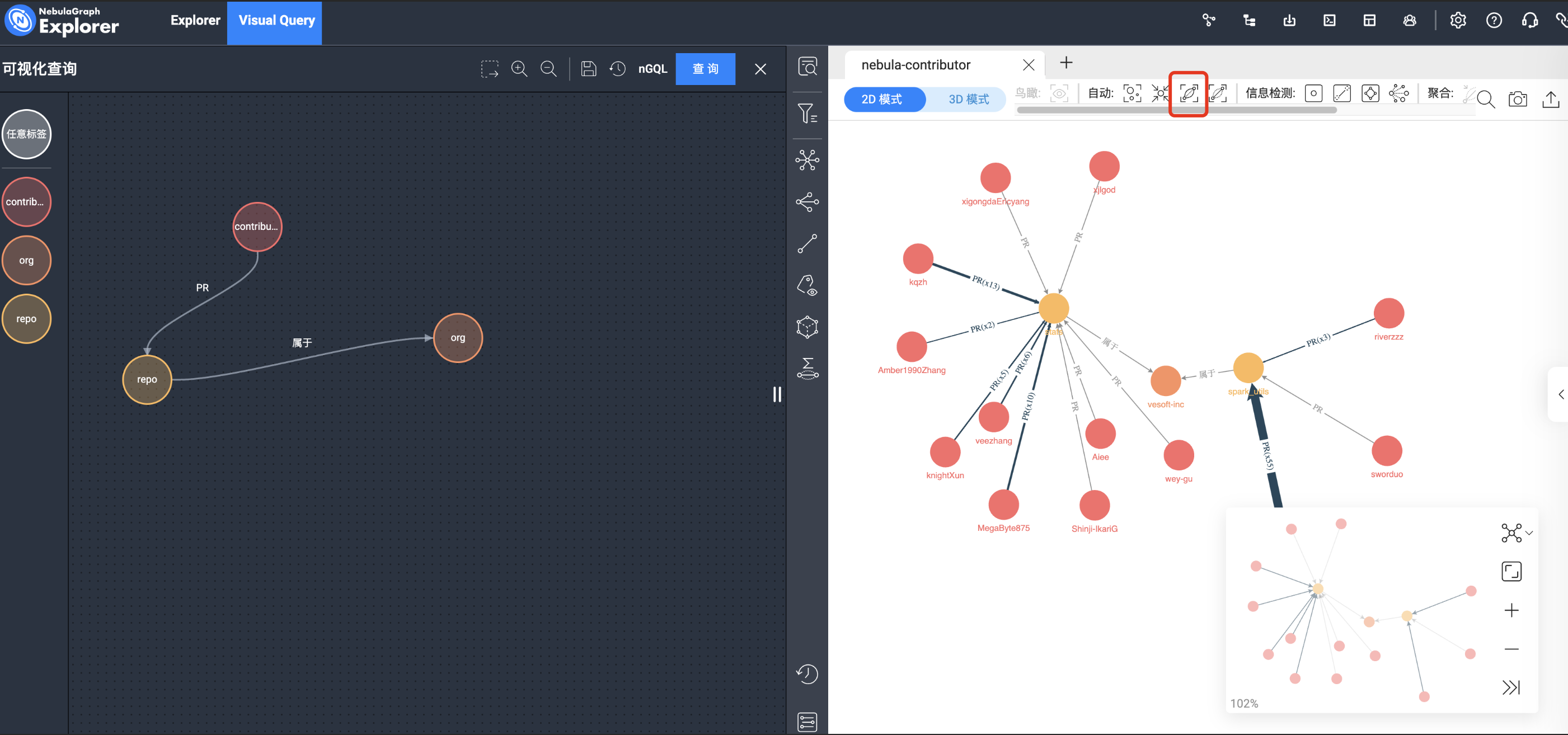
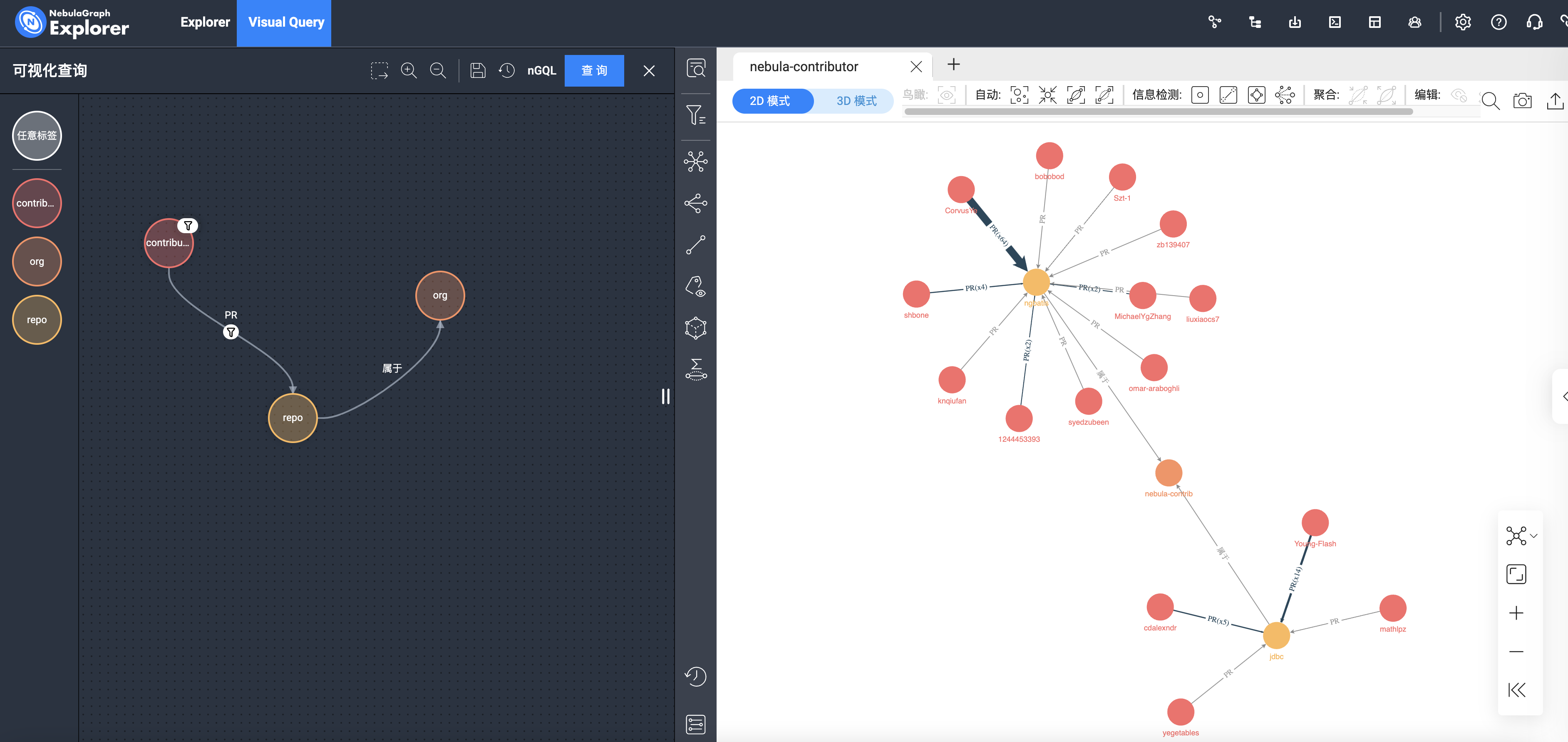
上图点击了红框中的边聚合,将同类型的边进行了聚合,看过去非常清爽。
上面的只是简单查询了图模型的对应数据,你可以加一点点筛选条件,比如:“找出非 NebulaGraph 雇员的人的 PR 合并情况”,你可以在 Visual Query 界面加入过筛条件:
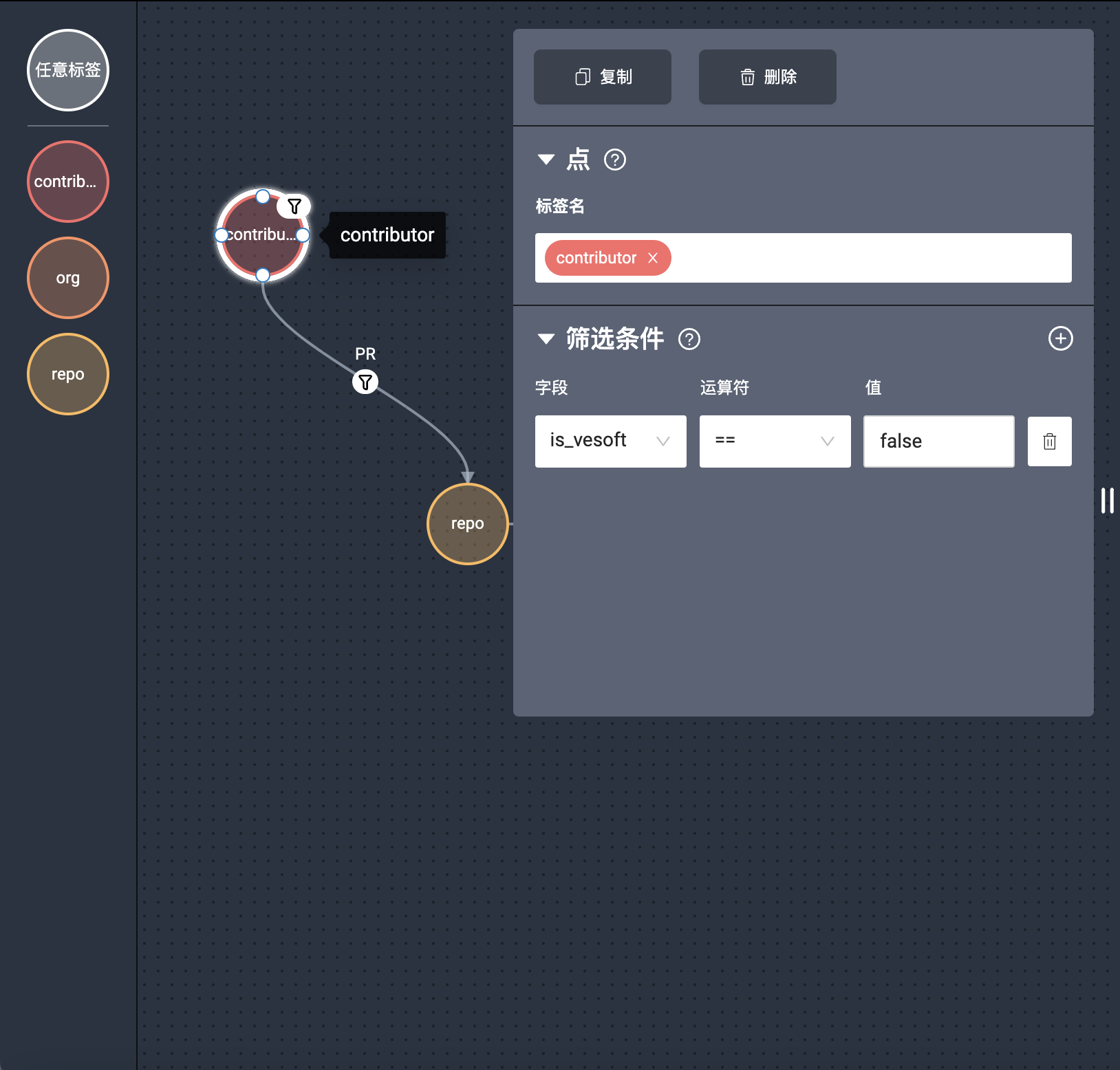
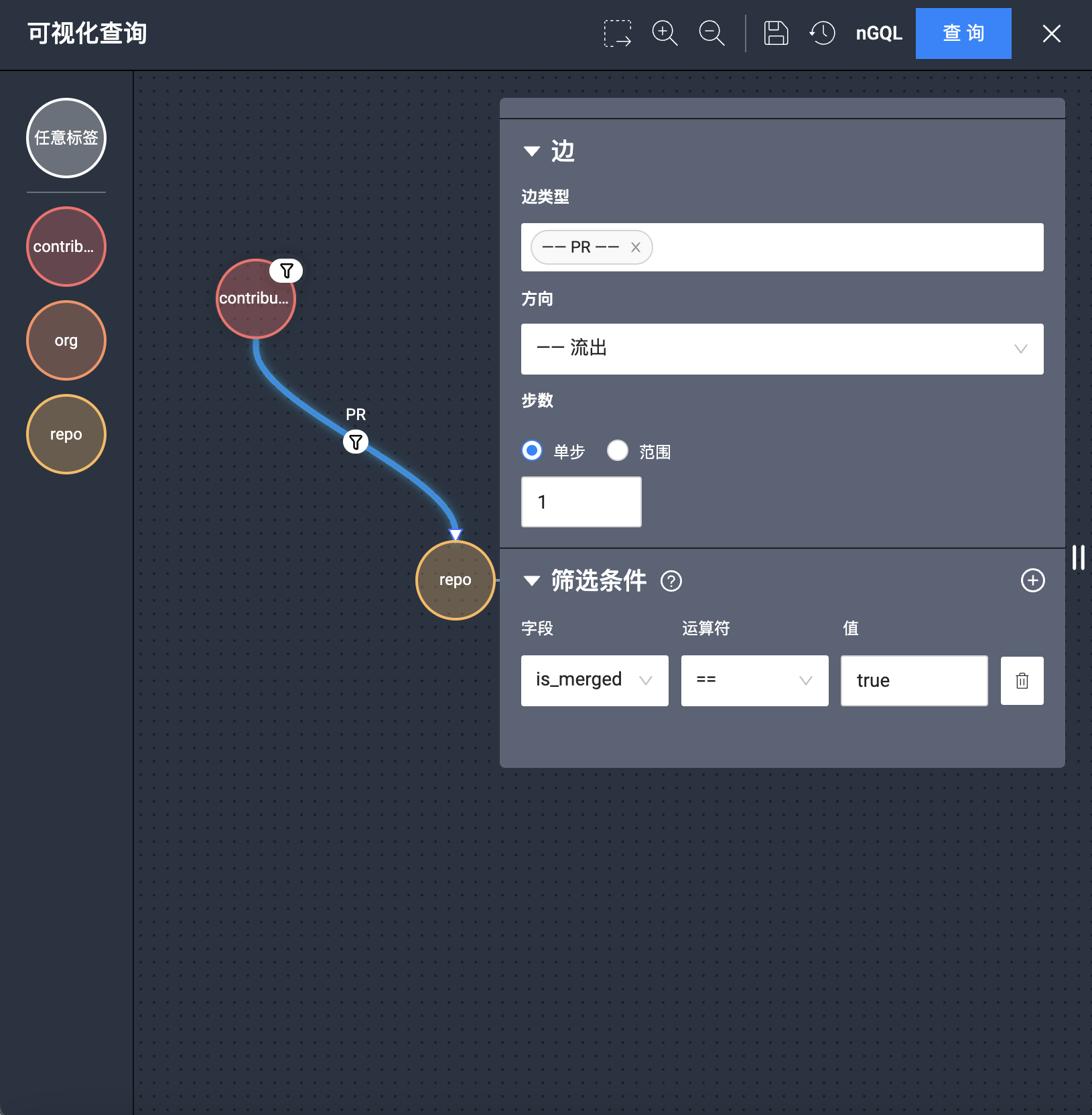
执行下看到:
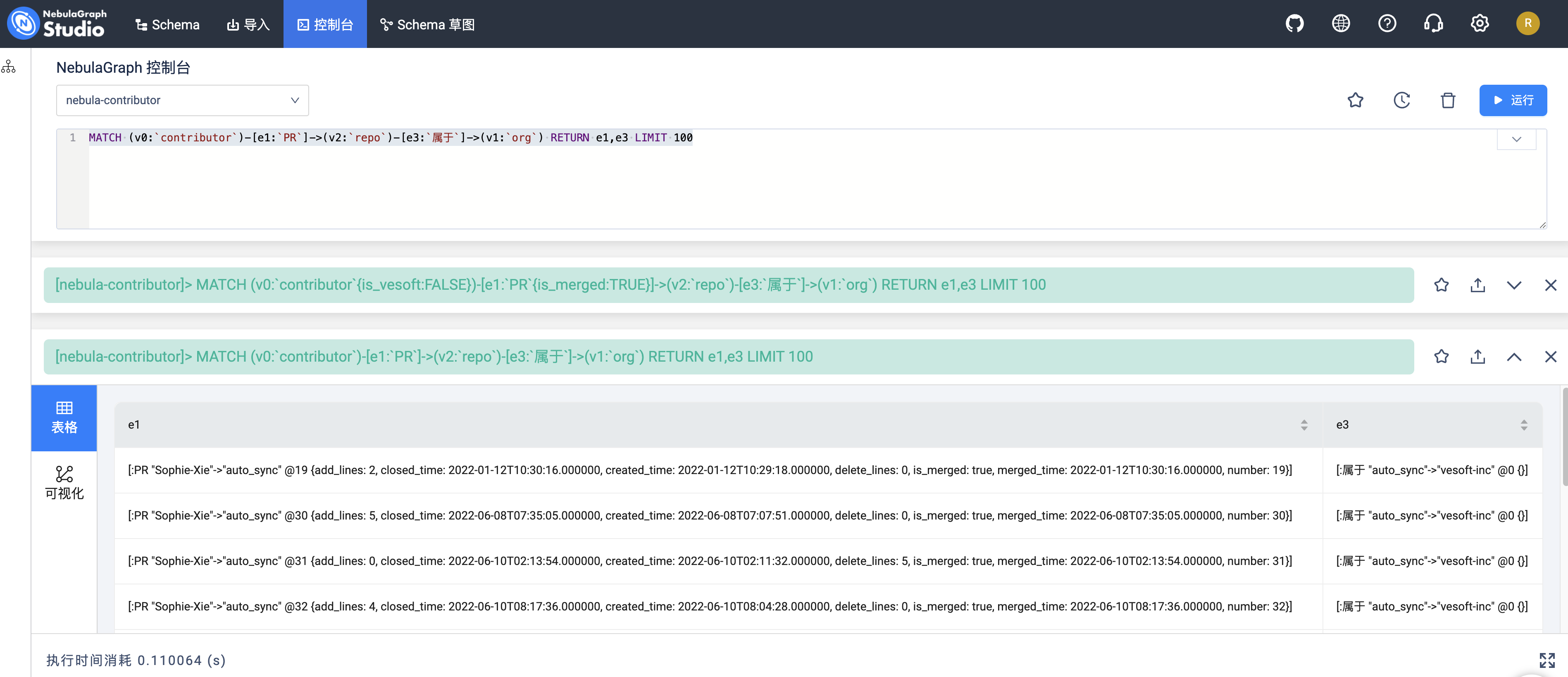
而 nebula-stuido 的用户不能通过拖拽看到数据,可以前往左上角导航的【控制台】功能,选择图空间为 nebula-contributor 之后,输入下面的查询语句:
MATCH (v0:`contributor`)-[e1:`PR`]->(v2:`repo`)-[e3:`属于`]->(v1:`org`) RETURN e1,e3 LIMIT 100
得到和 nebula-explorer 类似的结果:
点击【可视化】,得到下图类似的可视化结果(因为查询时随机返回 100 条边,可能你的数据和下图有出入):
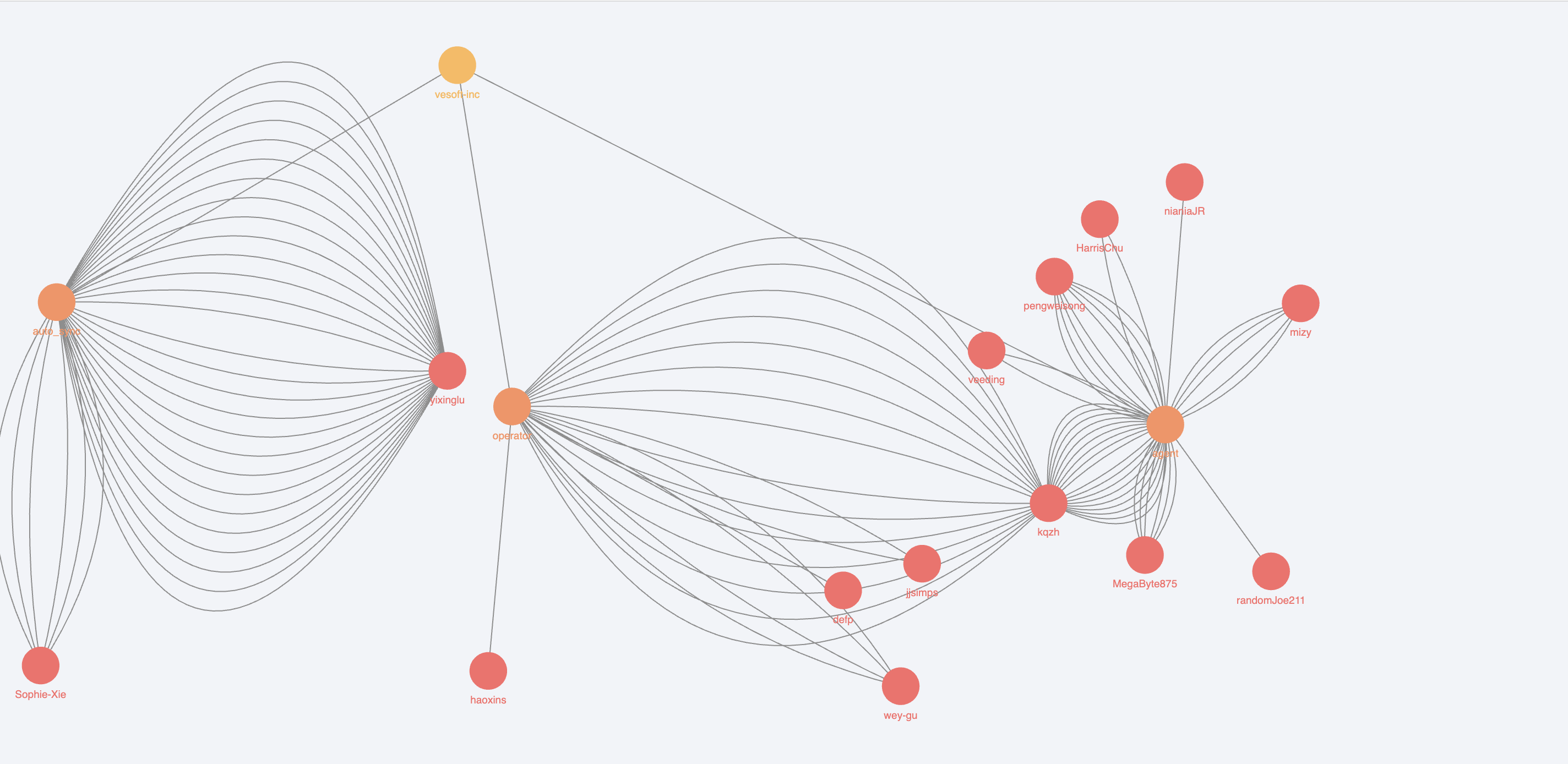
恭喜,你现在已经会图探索了。
可能你对文中用到的一些术语感到困惑,记得去读一读 NebuleGraph 的文档:https://docs.nebula-graph.com.cn/3.6.0/
完成本文实操的小伙伴,可以联系星云小姐姐领取限量的春节学图礼包哟~
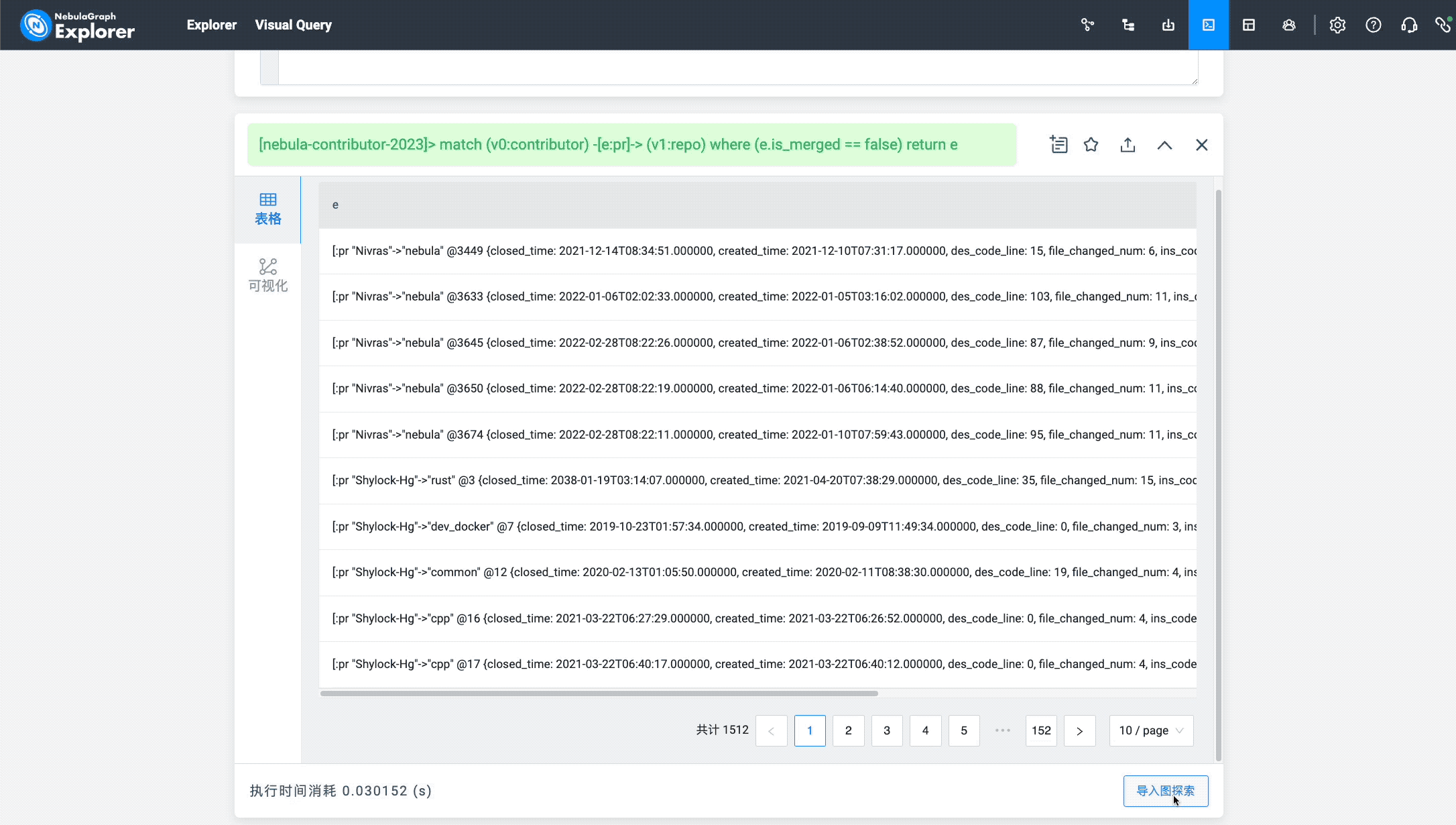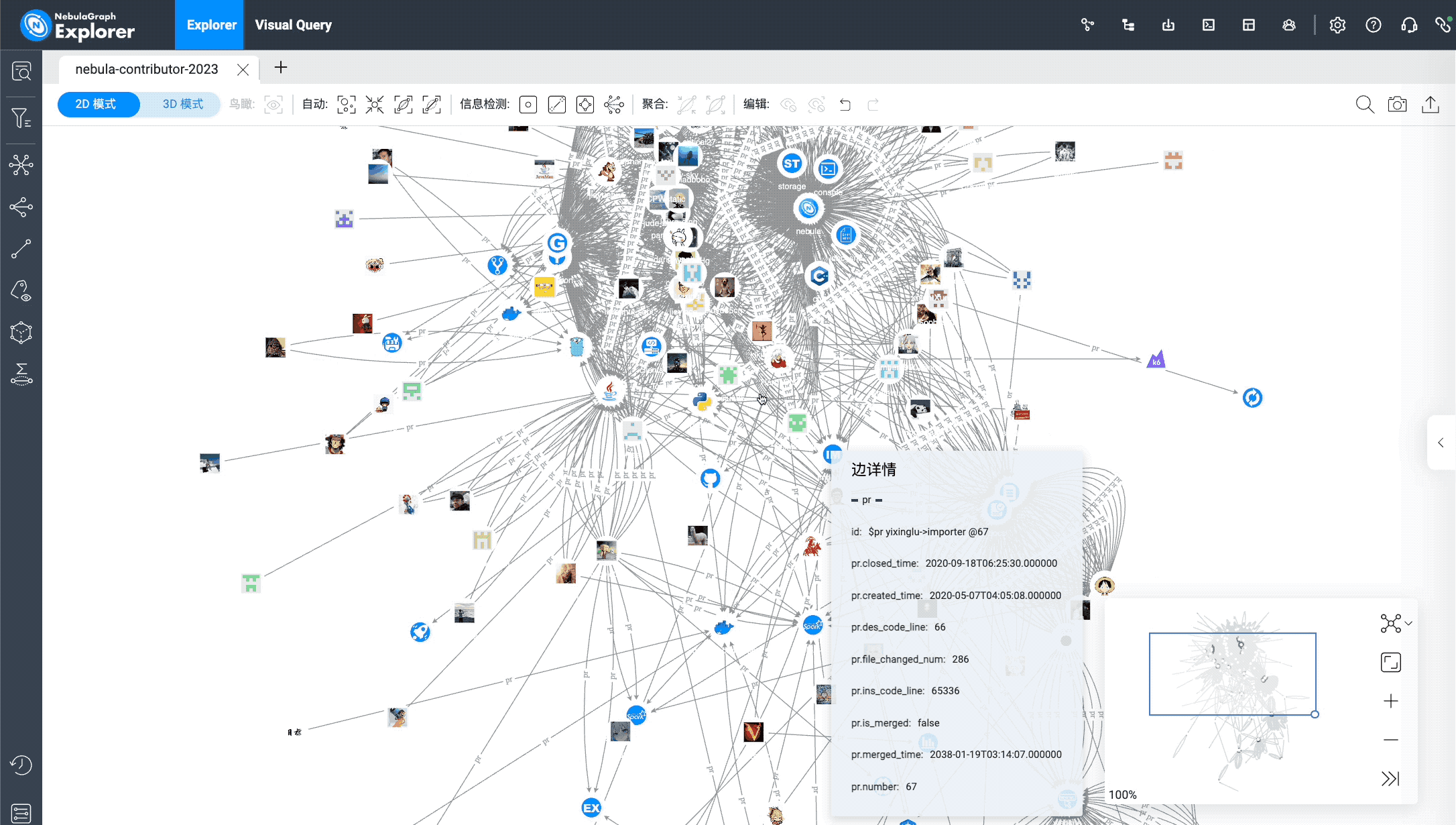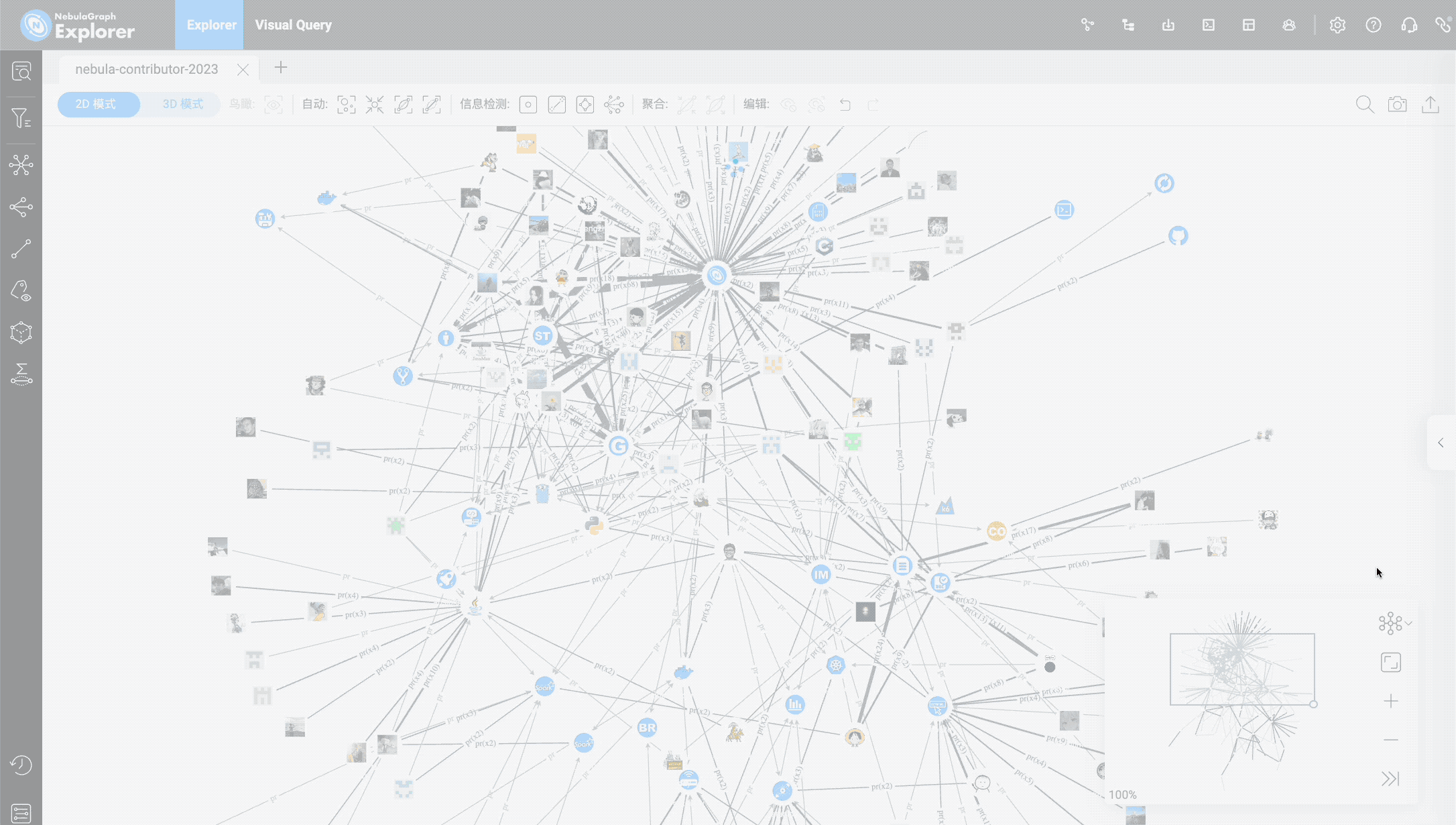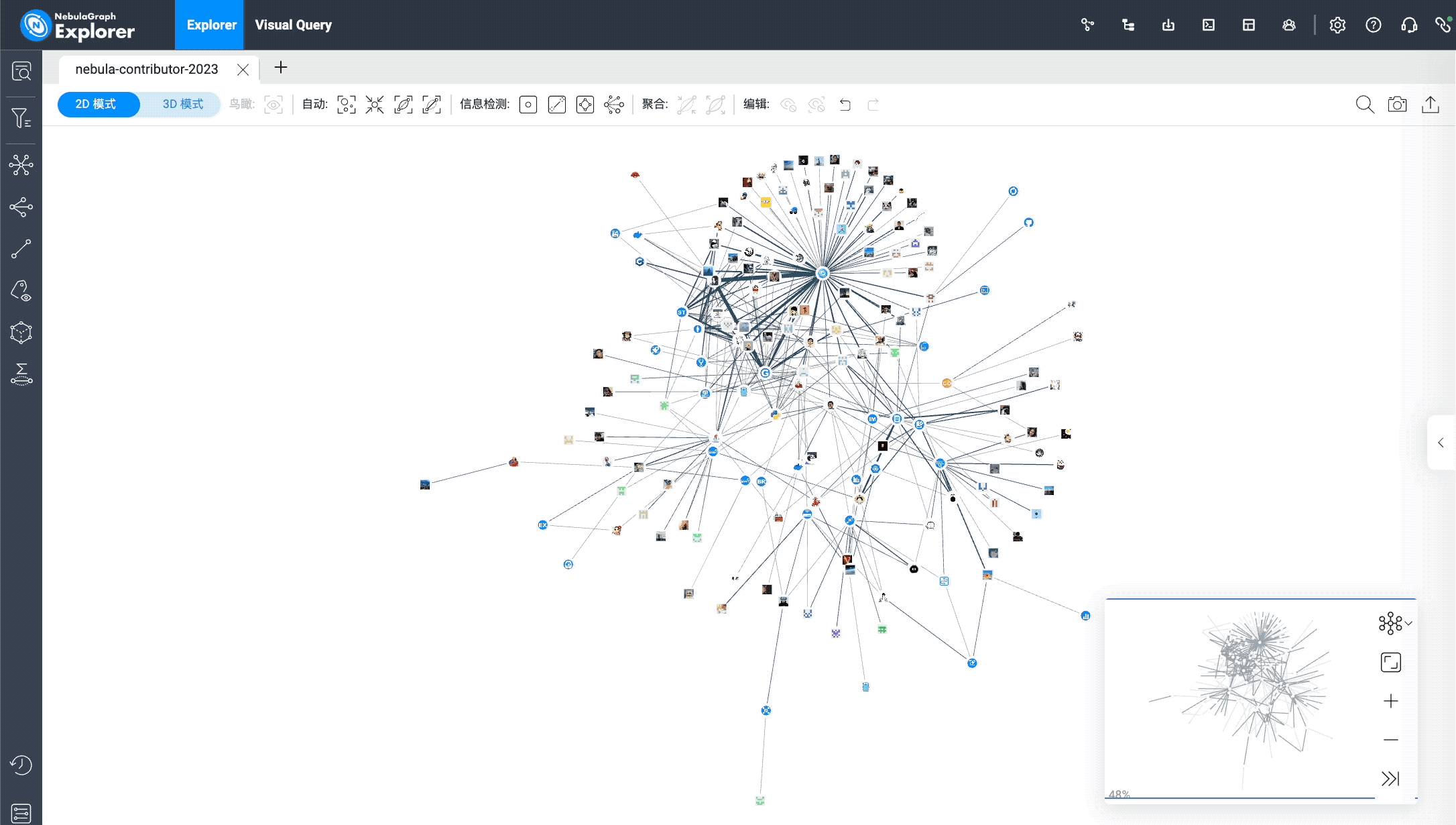
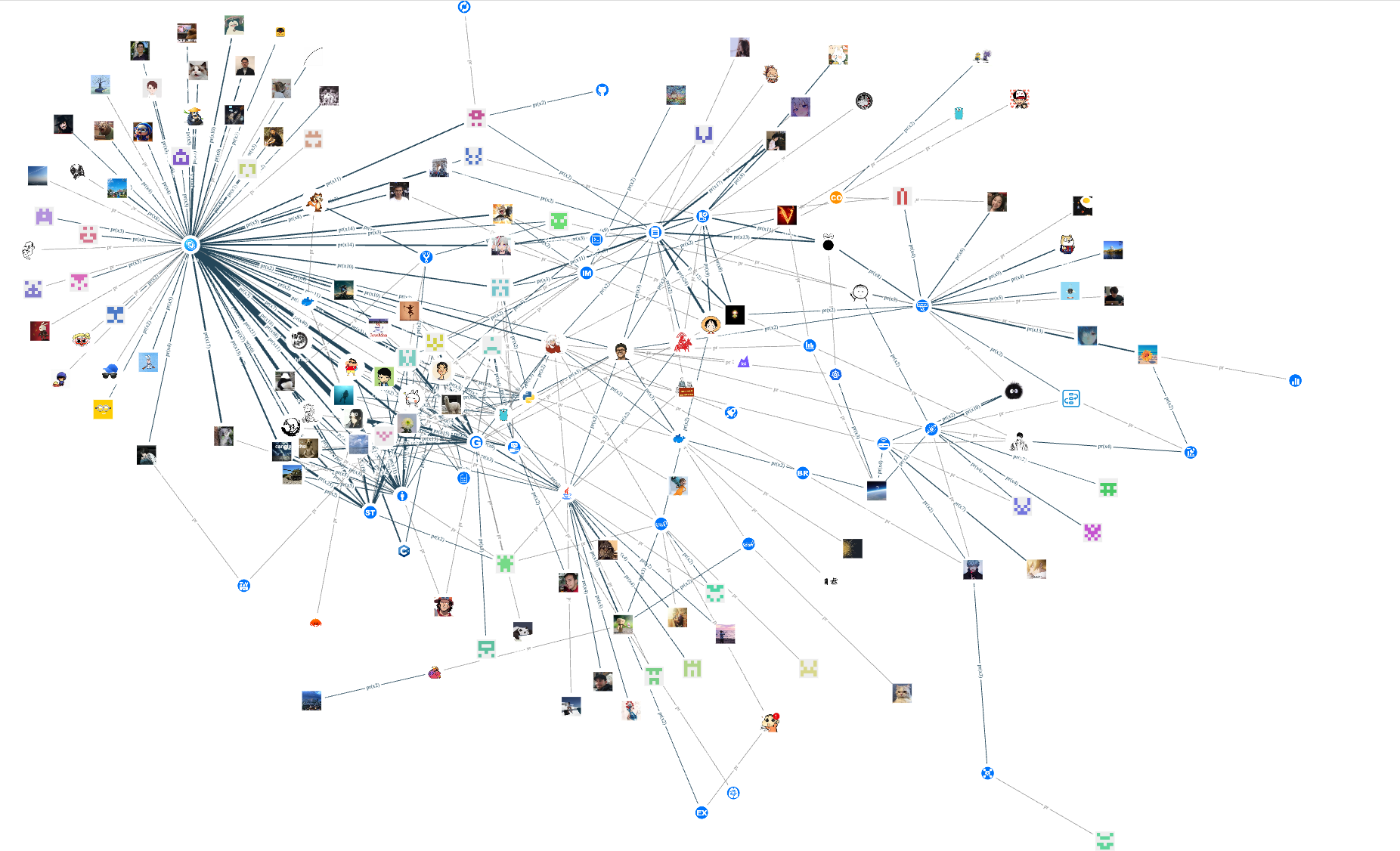
下面,放几个基于本数据集的一些探索图:
PR 还没被合并的小伙伴分布(下图为 nebula-explorer 的可视化展示,用上了点的换图标功能):
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub ✨ 查看源码:https://github.com/vesoft-inc/nebula;
想要一起提高文档的可读性么?一起来给『文档 nGQL 示例添加注释』吧~请瞄准那条让人费解的 nGQL 语句,留下你的讲解 (///▽///)
点击下图了解活动详情 🥹


 浙公网安备 33010602011771号
浙公网安备 33010602011771号